

“大数据技术原理与应用”课程实验报告
题目:实验七:Spark
初级编程实践
姓名:朱小凡
日期:2022/5/30
1、实验环境:
设备名称 LAPTOP-9KJS8HO6
处理器 Intel(R) Core(TM) i5-10300H CPU @ 2.50GHz 2.50 GHz
机带 RAM16.0 GB (15.8 GB 可用)
主机操作系统 Windows 10 家庭中文版
虚拟机操作系统 ubuntukylin-16.04
Hadoop 版本 3.1.3
JDK 版本 1.8
Java IDE:Eclipse
系统类型 64 位操作系统, 基于 x64 的处理器
笔和触控 没有可用于此显示器的笔或触控输入
2、实验内容与完成情况:
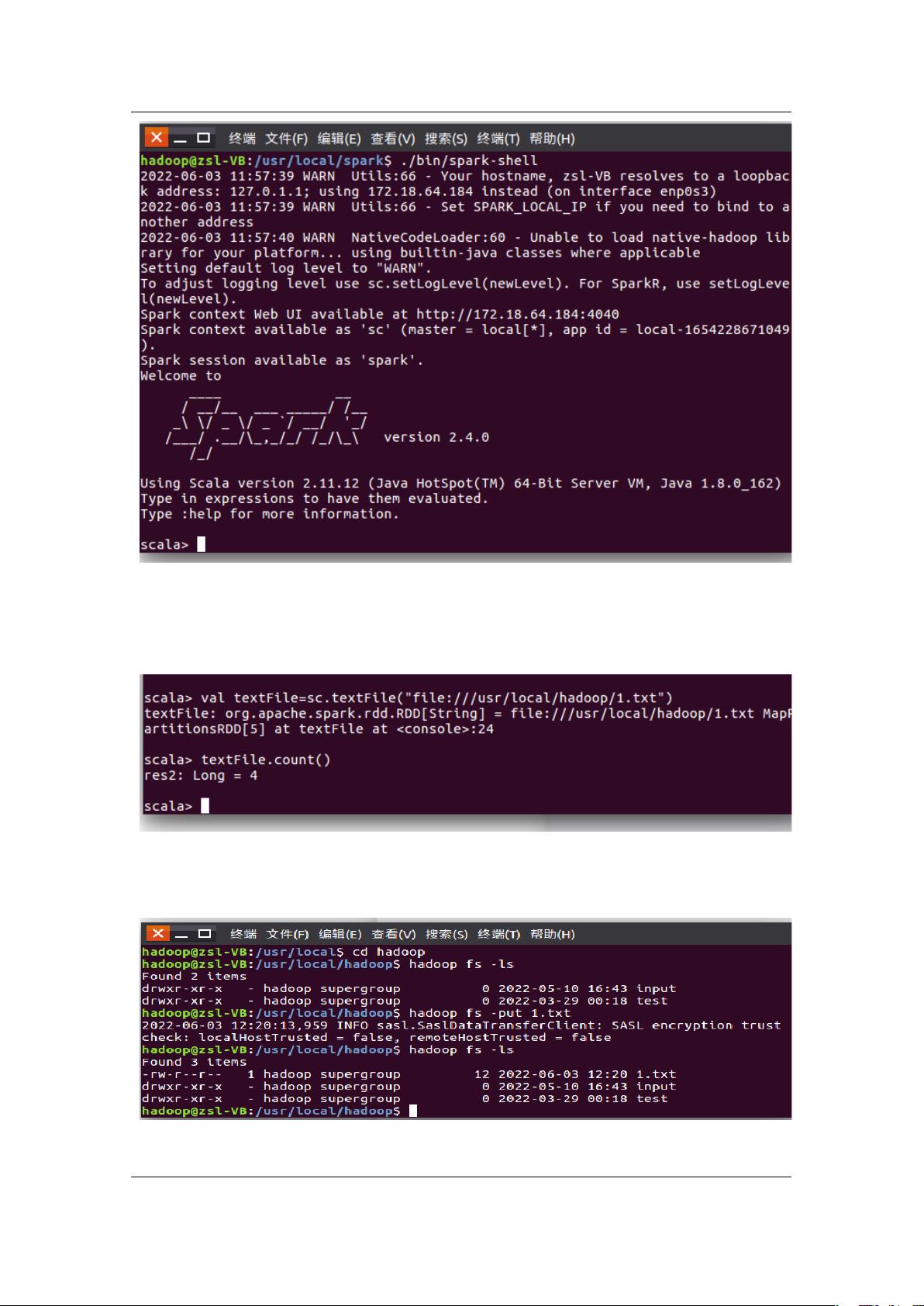
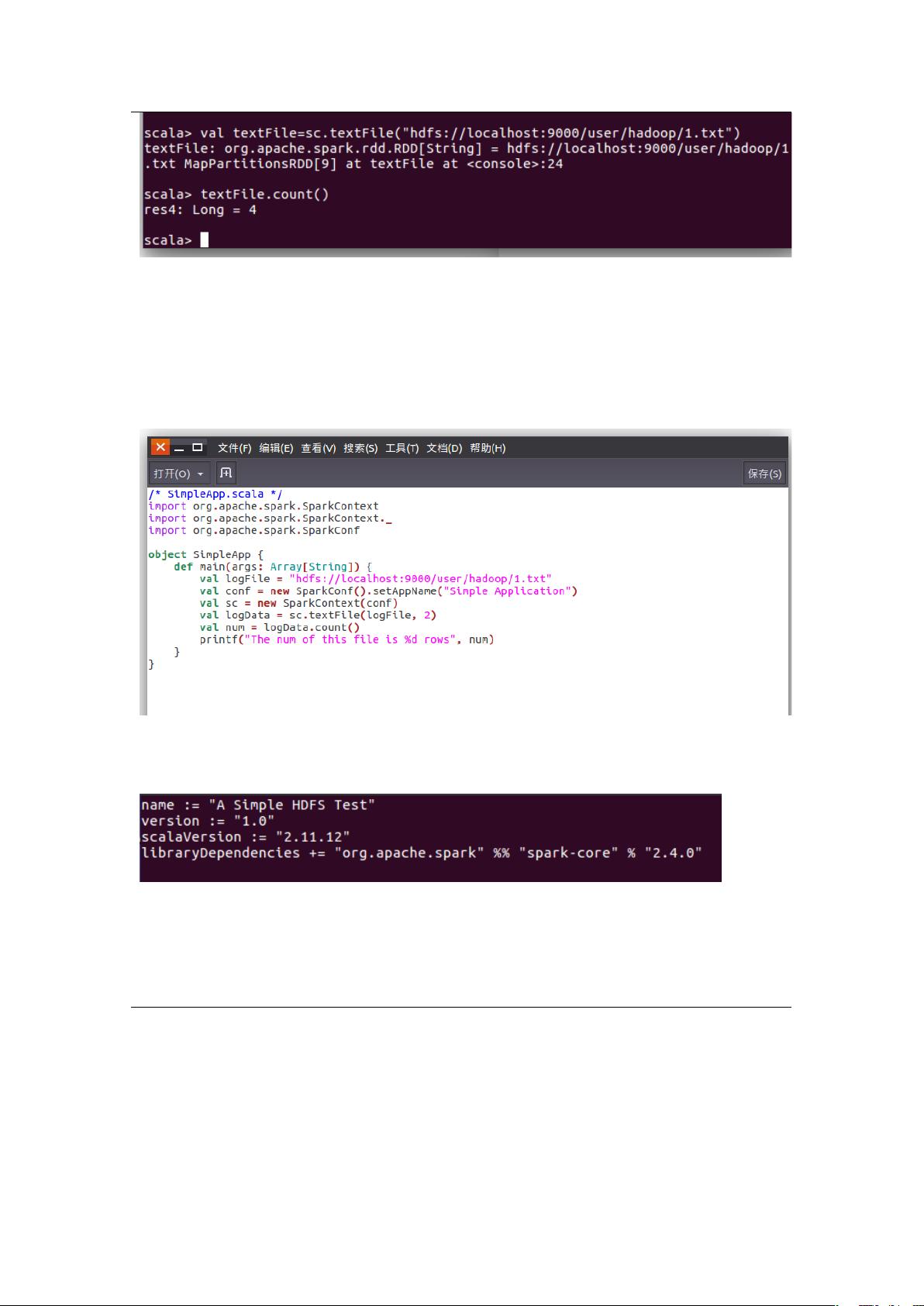
1. 安装 hadoop 和 spark。
将下载好的安装包解压至固定路径并安装
图 1 安装 spark
使用命令./bin/spark-shell 启动 spark
剩余10页未读,继续阅读













评论0