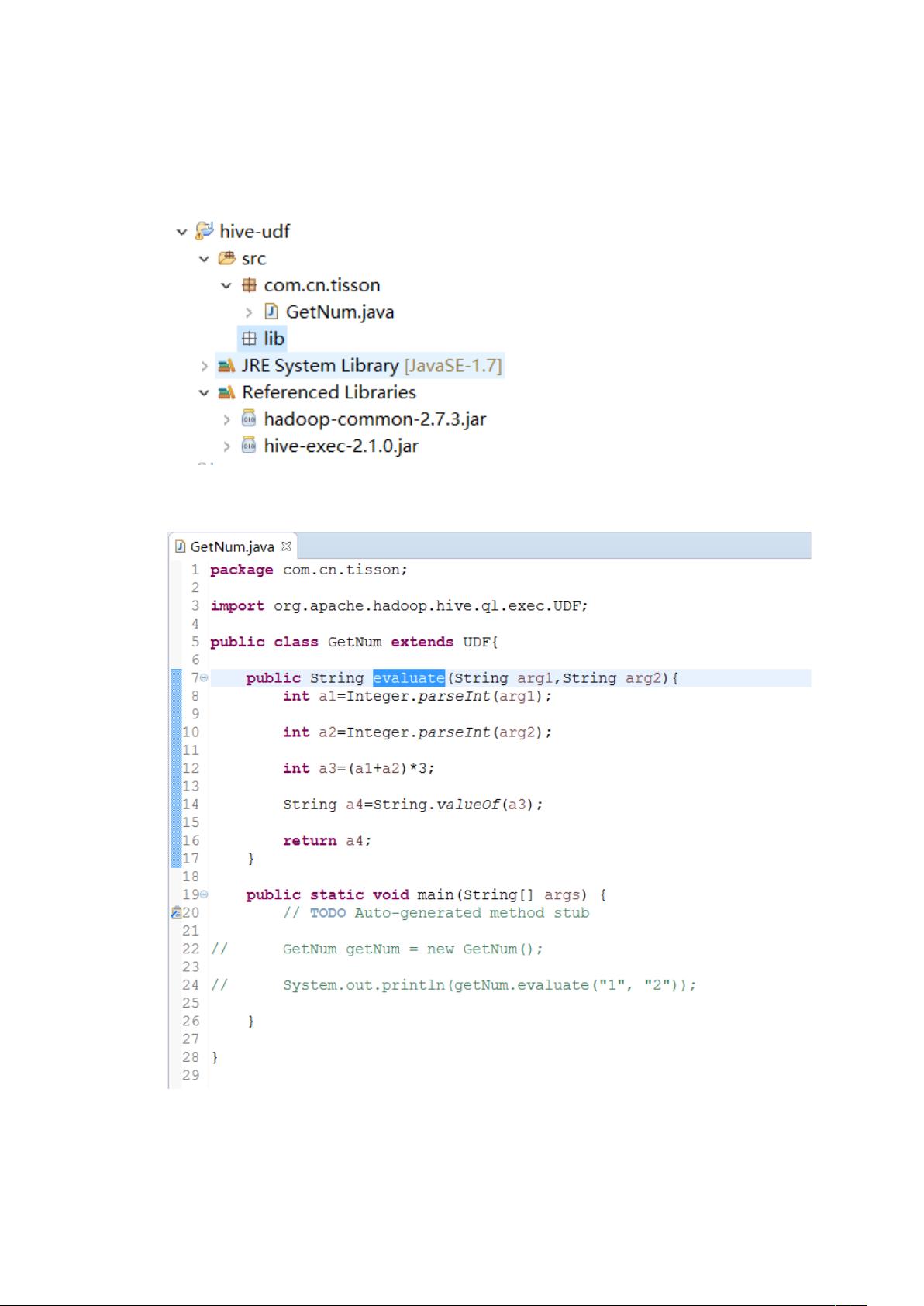
hive的UDF编写指南 hive是大数据处理的重要工具之一,其提供了强大的数据处理能力。然而,在实际应用中,我们可能需要根据业务需求编写自定义的UDF(User Defined Function),以满足特定的数据处理需求。下面,我们将详细介绍如何使用Java编写hive的UDF,并将其部署到hive中。 UDF的概念 在hive中,UDF是用户自定义的函数,可以根据业务需求编写自定义的函数来实现特定的数据处理逻辑。UDF可以将复杂的数据处理逻辑封装在一个函数中,以便于在hive查询中使用。 使用Java编写hive的UDF 使用Java编写hive的UDF需要遵循以下步骤: 步骤1:创建Java项目 我们需要创建一个Java项目。在Eclipse中,我们可以通过File -> New -> Java Project来创建一个新的Java项目。 步骤2:添加依赖项 在src目录下,我们需要创建一个文件夹lib,并将hadoop-common-XXX.jar和hive-exec-XXX.jar拷贝到该文件夹中。这些jar包是hive的依赖项,用于提供hive的基本功能。 步骤3:创建UDF类 接下来,我们需要创建一个Java类,用于实现UDF的逻辑。在本例中,我们将创建一个名为GetNum的Java类,该类继承自hive的UDF类。 步骤4:编写evaluate方法 在GetNum类中,我们需要编写evaluate方法,该方法是UDF的核心逻辑。evaluate方法将接收输入参数,并返回处理后的结果。 步骤5:编译和打包 编译完成后,我们需要将项目打包成jar包。在Eclipse中,我们可以通过Export -> Java -> JAR file来生成jar包。 步骤6:部署到hive 将jar包上传到服务器,并添加到hive的classpath中。 步骤7:创建自定义函数 在hive中,我们需要创建一个自定义函数,该函数将使用我们编写的UDF。我们可以使用CREATE FUNCTION语句来创建自定义函数。 步骤8:测试 我们可以使用SELECT语句来测试我们的自定义函数是否生效。 总结 通过上述步骤,我们可以成功地使用Java编写hive的UDF,并将其部署到hive中。这种方法可以帮助我们实现复杂的数据处理逻辑,并提高hive的可扩展性。
本内容试读结束,登录后可阅读更多
下载后可阅读完整内容,剩余2页未读,立即下载
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~