# “中国软件杯”大学生软件设计大赛二等奖开源代码——基于深度学习的企业实体识别
未经作者允许,本文禁止转载!
## 代码地址
## 比赛简介:
为贯彻落实《国家中长期教育改革和发展规划纲要(2010-2020年)》,科学引导高校青年学子积极参加科研活动,切实增强自主创新能力和实际动手能力,实现应用型人才培养和产业需求的有效衔接,推动我国软件和信息技术服务业又好又快发展,工业和信息化部、教育部和江苏省人民政府共同主办了面向中国高校及广大海外院校在校学生(含高职)的纯公益性软件设计大赛。其中普通本科高校600余所,高职院校200余所,211、985高校百余所,累计近万名大学生参赛。
## 赛题介绍:
> 着深度学习技术的发展,文字识别与自然语言处理近年来受到广泛关注。结合文字识别与自然语言处理技术解决传统方法无法处理的问题,成为企业提高自身竞争力的重要利器。
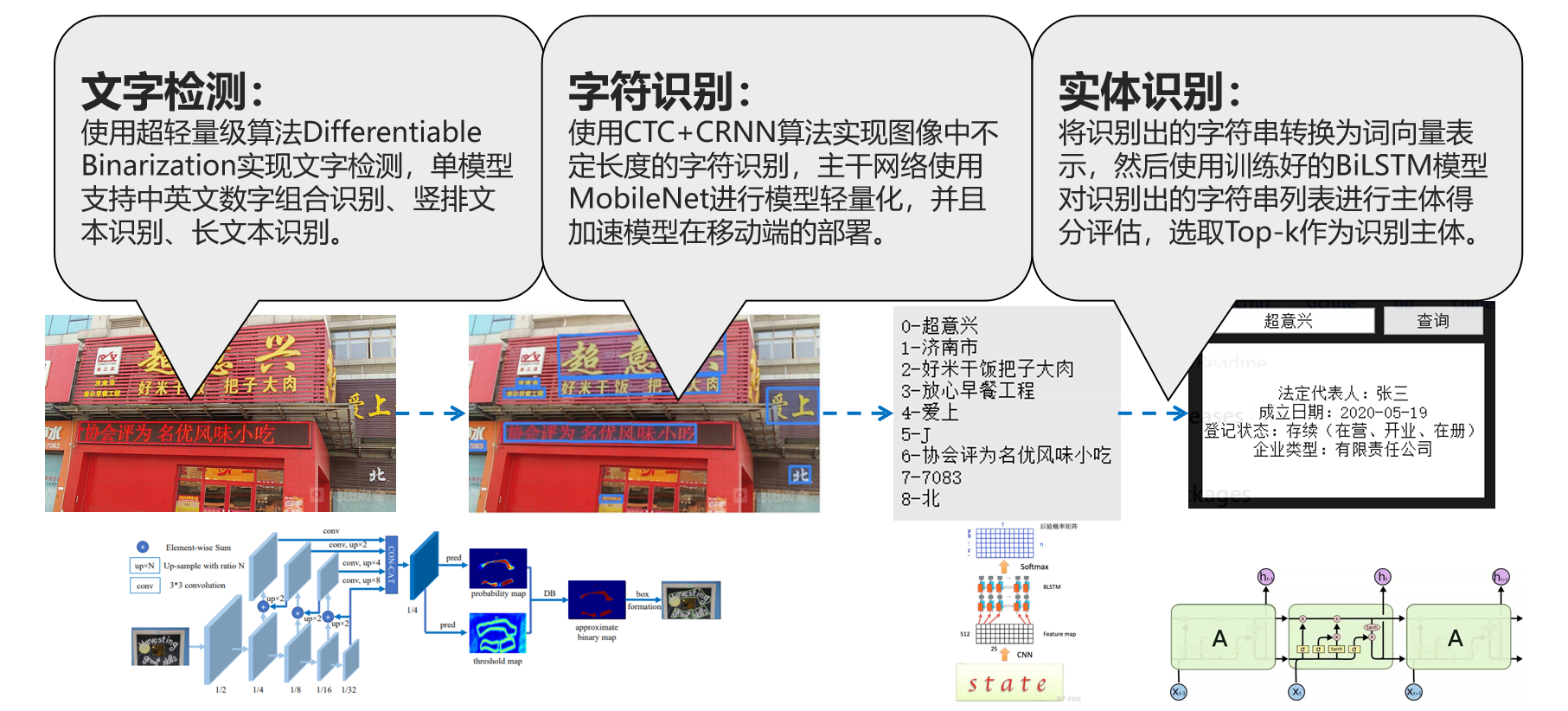
本赛题要求使用基于深度学习的文字识别与自然语言处理技术,识别商铺广告牌图片中的文字,从识别出的文字中提取出商铺名称。此系统涉及文字检测、文字识别、命名实体识别三种技术。
## 业务场景:
> 企业实体识别主要应用在我们目前业务系统中的查证功能。查证功能的主要作用是将用户拍摄的店铺照片经过OCR识别后进行店铺名称的提取,然后通过店铺名称查询证照库,获取该店铺办理过的所有证照信息,方便用户进一步了解该店铺。在日常应用中,例如外出就餐时利用我们的系统随手拍摄要就餐的饭店门脸,系统会自动检测该饭店证照是否齐全以及所办证照的详细信息,方便用户做出就餐决策。
## 涉及工具:
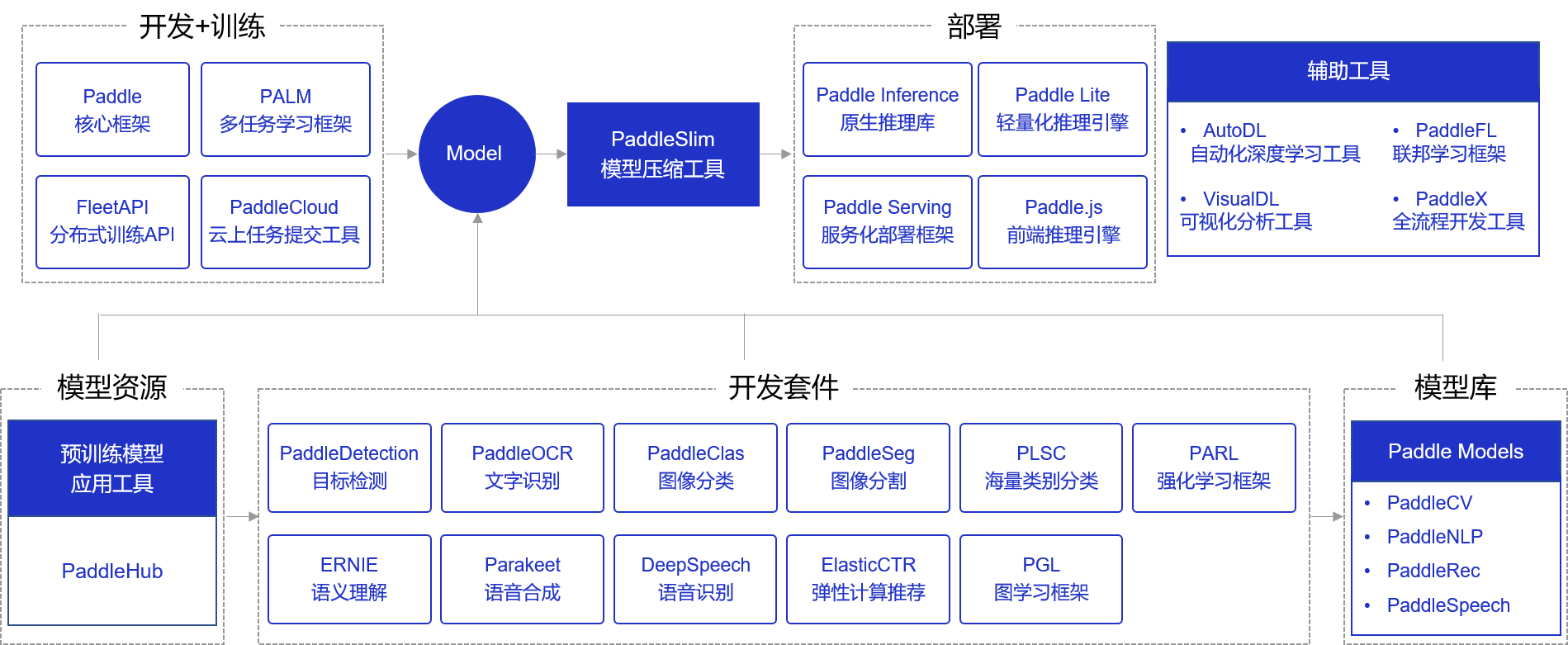
### 1. PaddlePaddle原生框架:
百度出品的深度学习平台飞桨(PaddlePaddle)是主流深度学习框架中一款完全国产化的产品,与Google TensorFlow、Facebook Pytorch齐名。2016 年飞桨正式开源,是国内首个全面开源开放、技术领先、功能完备的产业级深度学习平台。相比国内其他平台,飞桨是一个功能完整的深度学习平台,也是唯一成熟稳定、具备大规模推广条件的深度学习平台。
### 2. PaddleOCR工具库:
PaddleOCR是一个与OCR相关的开源项目,不仅支持超轻量级中文OCR预测模型,总模型仅8.6M(单模型支持中英文数字组合识别、竖排文本识别、长文本识别,其中检测模型DB(4.1M)+识别模型CRNN(4.5M)),而且提供多种文本检测训练算法(EAST、DB)和多种文本识别训练算法(Rosetta、CRNN、STAR-Net、RARE)。
### 3. Paddle-Lite轻量级推理框架:
Paddle Lite是飞桨基于Paddle Mobile全新升级推出的端侧推理引擎,在多硬件、多平台以及硬件混合调度的支持上更加完备,为包括手机在内的端侧场景的AI应用提供高效轻量的推理能力,有效解决手机算力和内存限制等问题,致力于推动AI应用更广泛的落地
## 设计思路:
## 效果演示:
### 1. 手机APP:

### 2. PC端软件:

## Step-1 调用PaddleOCR进行文本检测
```python
!pip install shapely
!pip install pyclipper
```
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Collecting shapely
[?25l Downloading https://mirror.baidu.com/pypi/packages/98/f8/db4d3426a1aba9d5dfcc83ed5a3e2935d2b1deb73d350642931791a61c37/Shapely-1.7.1-cp37-cp37m-manylinux1_x86_64.whl (1.0MB)
[K |████████████████████████████████| 1.0MB 13.1MB/s eta 0:00:01
[?25hInstalling collected packages: shapely
Successfully installed shapely-1.7.1
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Collecting pyclipper
[?25l Downloading https://mirror.baidu.com/pypi/packages/1a/2f/ba30c6fe34ac082232a89f00801ea087c231d714eb200e8a1faa439c90b5/pyclipper-1.2.0-cp37-cp37m-manylinux1_x86_64.whl (126kB)
[K |████████████████████████████████| 133kB 12.5MB/s eta 0:00:01
[?25hInstalling collected packages: pyclipper
Successfully installed pyclipper-1.2.0
```python
from PIL import Image, ImageDraw, ImageFont
from numpy import random
import paddlehub as hub
import numpy as np
import paddle.fluid as fluid
class Detector(object):
def __init__(self):
# 加载移动端预训练模型
# self.ocr = hub.Module(name='chinese_ocr_db_crnn_mobile')
# 服务端可以加载大模型,效果更好
self.ocr = hub.Module(name='chinese_ocr_db_crnn_server')
def feedCap(self, np_images, vis=True):
results = self.ocr.recognize_text(
# 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
images=[np_images],
use_gpu=True, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
visualization=False, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.5)
img = Image.fromarray(np_images[:, :, [2, 1, 0]])
draw = ImageDraw.Draw(img) # 图片上打印
txt = []
for result in results:
data = result['data']
for infomation in data:
if vis:
for i in range(5):
pos = [(v[0]+i, v[1]+i)
for v in infomation['text_box_position']]
draw.polygon(pos, outline=(0, 255, 0))
txt.append(infomation['text'])
# img = np.array(img)[:, :, [2, 1, 0]]
return img, txt
```
创建实例并查看图像
```python
import os
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
img = cv2.imread('21.jpg')
plt.imshow(img[:, :, [2, 1, 0]])
```
使用OCR模型进行文本检测和识别
```python
ocr_model = Detector()
result, txt = ocr_model.feedCap(img)
plt.imshow(result)
plt.show()
print(txt)
```
[32m[2020-11-04 10:05:29,624] [ INFO] - Installing chinese_ocr_db_crnn_server module[0m
[32m[2020-11-04 10:05:29,627] [ INFO] - Module chinese_ocr_db_crnn_server already installed in /home/aistudio/.paddlehub/modules/chinese_ocr_db_crnn_server[0m
[32m[2020-11-04 10:05:30,104] [ INFO] - Installing chinese_text_detection_db_server module-1.0.2[0m
[32m[2020-11-04 10:05:30,107] [ INFO] - Module chinese_text_detection_db_server-1.0.2 already installed in /home/aistudio/.paddlehub/modules/chinese_text_detection_db_server[0m

['正新鸡排', '遇见', '见', '天派', '天派', '元', 'Bh!', '31G元', '有爱就是', '超大派', '正新', '12元', '正新鸡排', '正新鸡排', '门市价18元', '再饮科1']
## Step-2 使用百度地图API爬取店铺名称(正样本)
这一步需要首先在百度地图开放平台注册并且申请API

### 使用Python接口爬取店铺名
```python
import requests
from tqdm import tqdm
def baidu_map_search():
# 注册->新建应用 http://
毕设&课程作业_基于PaddleOCR和深度学习的企业实体识别.zip

版权申诉
72 浏览量
2024-01-16
16:54:12
上传
评论
收藏 661KB ZIP 举报
 毕设&课程作业_基于PaddleOCR和深度学习的企业实体识别.zip (7个子文件)
毕设&课程作业_基于PaddleOCR和深度学习的企业实体识别.zip (7个子文件)  Graduation Design
Graduation Design  main.ipynb 565KB
main.ipynb 565KB 21.jpg 84KB
21.jpg 84KB dict_file.txt 36KB test_file.txt 31KB train_file.txt 415KB training.jpg 40KB README.md 19KB
dict_file.txt 36KB test_file.txt 31KB train_file.txt 415KB training.jpg 40KB README.md 19KB资源评论













