
# 基于网络嵌入和语义表征的作者名消歧
Biendata竞赛平台 “OAG–WhoIsWho“赛道一 第一名解决方案
队伍名:cnic
比赛数据链接:https://www.biendata.xyz/competition/aminer2019/
If this code helps you, please cite the following paper:
Qiao, Ziyue, Yi Du, Yanjie Fu, Pengfei Wang, and Yuanchun Zhou. "[Unsupervised Author Disambiguation using Heterogeneous Graph Convolutional Network Embedding.](https://ieeexplore.ieee.org/abstract/document/9005458)" In 2019 IEEE International Conference on Big Data (Big Data), pp. 910-919. IEEE, 2019.
## 摘要
在许多领域中,同名消歧一直被视为一个很有意义但具有挑战性的问题,如文献管理,社交网络分析等。对论文同名作者的消歧是指利用论文的信息,如标题,作者,作者机构,摘要,关键词等,通过一些方法将论文分配到正确的作者档案中。目前已经有很多研究者针对同名作者消歧问题提出了解决方法,这些方法主要包括利用论文信息进行基于规则的匹配,或者利用表示学习方法,对论文信息进行表征学习,然后利用聚类方法,如层次聚类,DBSCAN等对这些表征向量进行聚类,使得相似的论文聚成一簇,不相似的论文被分到不同的簇中。本文提出了一种高效的作者名消歧方法,使用基于元路径随机游走的异质网络嵌入方法和基于word2vec的语义表征学习方法学习论文的表征向量,并使用基于DBSCAN与规则匹配结合的聚类方法将论文划分给不同的作者。
## 1.整体思路
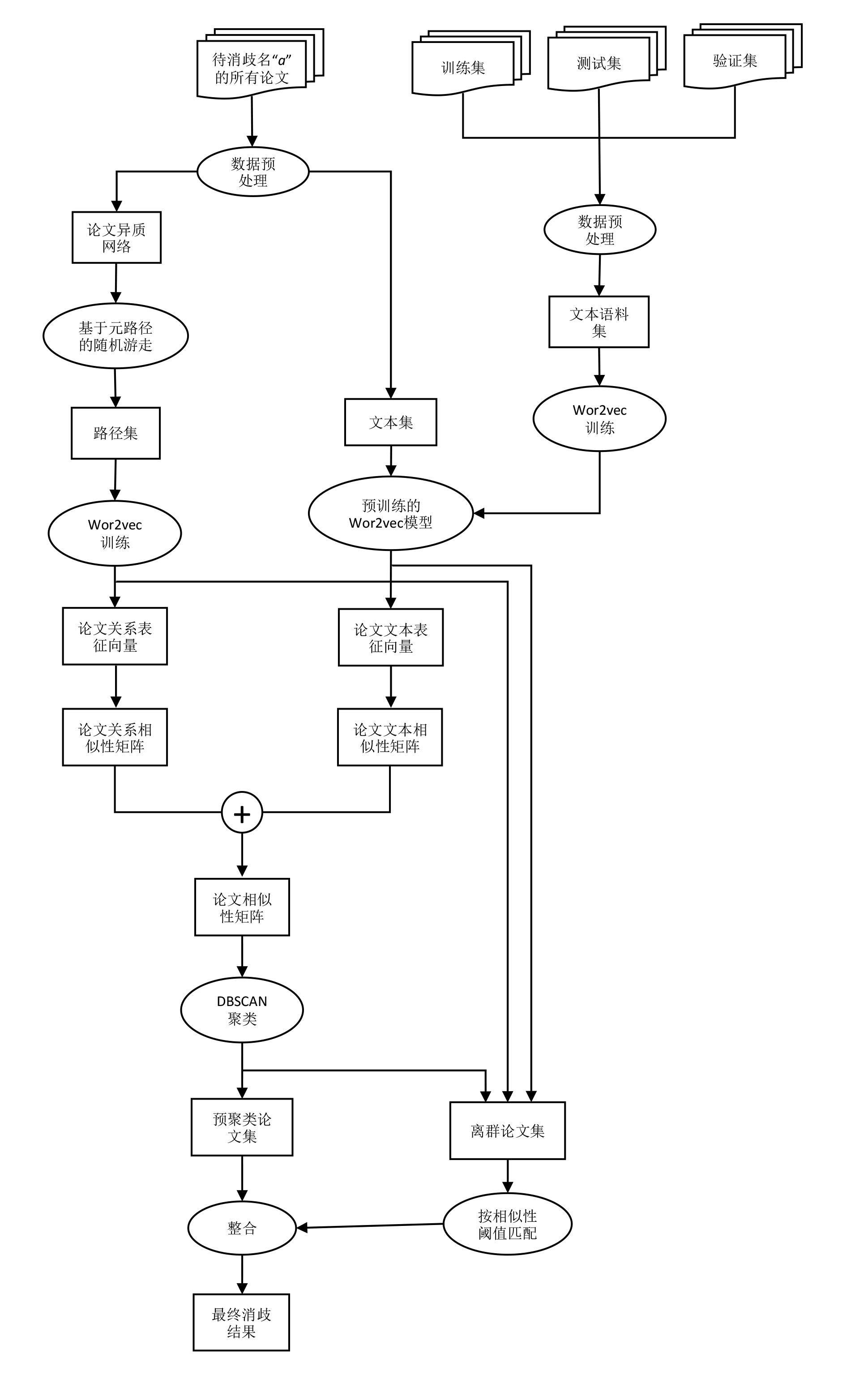
对于某个需要消歧的名字,根据其所有论文之间的关系信息和论文文本信息求出论文表征向量,进而求出论文之间的两两相似度,得到论文相似性矩阵,使用聚类算法和基于相似度阈值的匹配方法将论文划分为不同的簇,则每个簇代表一个特定作者的论文集。
我们的方法的整体框架如下:
## 2.特征分析
我们把该问题看作是对一个论文集的聚类任务,且不指定聚类簇个数,即K值。
首先,分析每篇论文的特征,论文的特征包含title, abstract, author, venue, organization, year, keyword. 我们把这些特征划分为两种类型,一种是语义特征,一种是离散特征。
语义特征指的是可以具有语义信息的文本特征,例如title, abstract, keyword,这些文本可以使用语义表征学习模型如word2vec等转化为文本语义向量。在后续的实验中,我们认为venue, organization, year也具有弱语义信息。
离散特征指的是本身的文本信息没有很大的价值,例如author,作者名称本身的语义并没有作用,一个作者只有在两篇文章中同时出现时才有作用,这表示两篇论文有一个共同作者,则它们之间的相似性较大。因此我们把这类特征成为离散特征,只能用来转换为论文间的关系。在后续的实验中,我们发现organization也属于离散特征,因为其中的有些词如地名可以用来搭建论文之间的关系。
具体实施上,我们定义author, organization为离散特征,定义title, venue, organization, year, keyword为语义特征。
基于以上两种特征的认识,我们的思路是使用语义特征学习论文的文本表征向量,利用离散特征来构建论文之间的关系,如有共同作者关系,有机构相似性关系,以此构建论文网络,通过网络嵌入学习方法来学习论文的关系表征向量。再使用聚类算法对论文进行聚类。
## 3.论文表征学习
这部分我们介绍如何学习论文的两种表征向量。
### 3.1 论文关系表征学习
此部分的作用是学习到每个论文的关系表征向量。可以看作是先搭建论文异质网络,然后利用网络嵌入的方法学习到每个论文节点的表示向量。本部分用到的特征有author和organization。
网络嵌入(Network Embedding)模型尤其是异质网络嵌入模型已经有了很多研究成果,我们使用的网络嵌入模型主要参考DeepWalk[1]和Metapath2vec[2]。
#### 3.1.1 异质网络构建
对于每一个需要消歧的名字,将其对应的所有的论文之间的关系抽取出来,构建出一个论文异质网络,如图1所示。这个异质网络包含一种类型的节点:论文(每篇论文代表一个节点),两种类型的边:CoAuthor,CoOrg。
CoAuthor代表两个论文之间有共同作者(不包含需要消歧的名字),边上的度代表拥有共同作者的个数。例如如果两篇论文之间有共同作者,那么就在它们之间构建一条关系名为CoAuthor 的边,同时这条边具有共同作者数目的属性,如果有1个共同作者,这个关系的权重就为1,如果有2个共同作者,那么权重就为2,以此类推。
CoOrg代表两个论文中待消歧名字的机构的相似性关系,边上的度代表两个机构共词的数量。例如,两个论文的机构有相同出现的词,且这个词不是停用词,那么就在它们之间构建一条CoOrg的边,这边相应的也有数目的权重,如果有一个共现词,那么权重值为1,如果有两个共现词,那么权重为2,以此类推。要注意的是我们只使用了待消歧名字的机构信息。
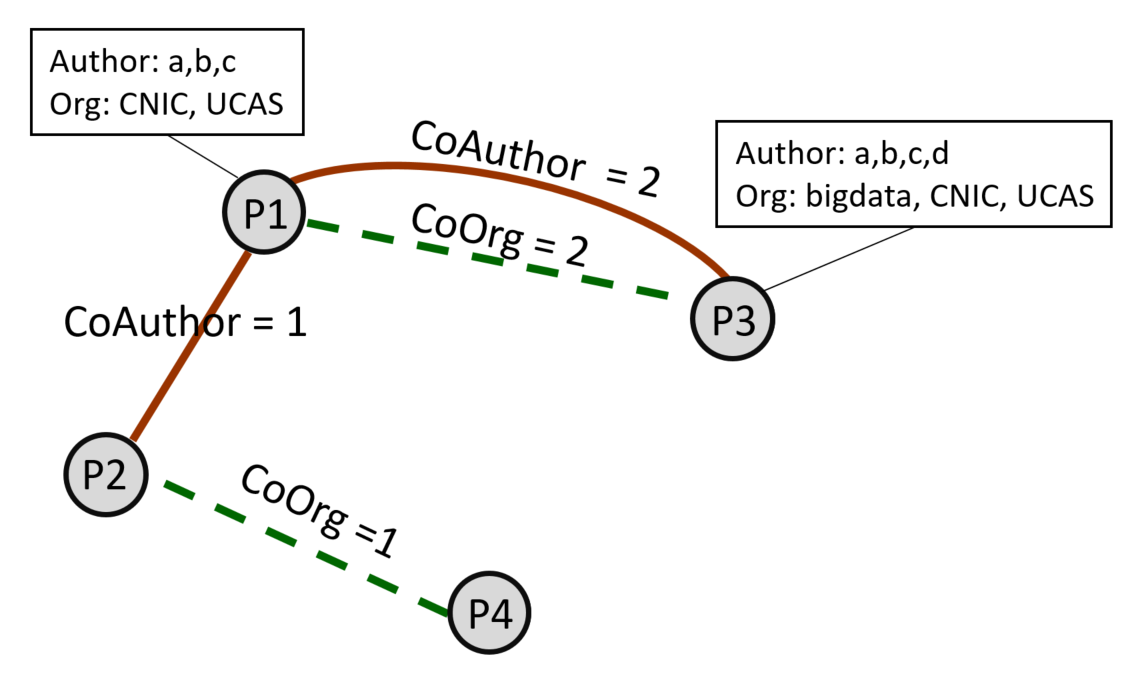
图1. 论文异质网络示意图。其中a是待消歧作者名,Org代表a所属的机构。
#### 3.1.2 基于元路径的随机游走
构建完上述论文异质网络,我们使用基于元路径的随机游走生成由论文id组成路径,把这些路径作为word2vec的输入,最后得到每个论文id对应的关系表征向量。
具体来说,在论文异质网络中轮流选择每一节点,以该节点为初始节点,在节点之间的边进行随机游走,把游走的路径保存下来作为word2vec的训练语料库[1]。基于元路径的随机游走的意思是在边上随机游走时,并不是完全随机的,而是由元路径指导的[2]。
规定在随机游走的过程中,按照p1CoAuthorp2CoOrgp3这样的元路径顺序进行游走,每一次游走过程中,按照当前元路径规定的某种类型的边选择下一个节点,随机选取一个通过该类型边与当前节点相连的节点作为下一个节点,在每一条长路径中,重复采样若干次这样的元路径,即前一条元路径的最后一个节点作为下一条元路径的第一个节点。最终迭代直到达到一定的次数(代码中的定义为walklenth),则另选一个节点作为开始节点进行游走,最终生成若干这样的长路径,每个路径点是论文的id,并将每个长路径按行存储,生成训练语料库。
同时,在某个节点在元路径指导下朝着某类型的边随机选择下一个节点游走的过程中,会考虑到边的权值,权值越大,说明两个节点的关系越密切,00那么节点沿着这条关系跳转的概率就越大,我们规定该概率与权重是正比例关系。例如,上图中,若p1为当前节点,下一跳的关系是CoAuthor,那么与p1有该关系的两个节点分别是p2和p3,根据它们之间该边的权值,那么从p1游走到p2的概率是1/3,游走到p3的概率是2/3。
在某些情况下,有些关系对于一些论文来说是缺失的,例如某个论文中所有的作者并没有出现在其他任意一个论文的作者列表中,那么对它来说CoAuthor这个关系是缺少的,当出现这种情况时,就采用更灵活的策略,即根据元路径中当前缺失关系的下一个关系游走,对于上面说的那篇论文来说,就转而根据它的CoOrg关系进行游走。
这样,每一轮选择图中的每个节点为起始点开始随机游走,�
 2019 Biendata竞赛平台“OAG–WhoIsWho 同名消歧竞赛 赛道一”消歧比赛,第一名解决方案 .zip (2个子文件)
2019 Biendata竞赛平台“OAG–WhoIsWho 同名消歧竞赛 赛道一”消歧比赛,第一名解决方案 .zip (2个子文件)  Name-Disambiguation-Biendata--master
Name-Disambiguation-Biendata--master  rw+w2v.ipynb 451KB README.md 19KB
rw+w2v.ipynb 451KB README.md 19KB资源评论


学术菜鸟小晨
- 粉丝: 2w+
- 资源: 5610









最新资源
- 基于ssh员工管理系统
- 5G SRM815模组原理框图.jpg
- T型3电平逆变器,lcl滤波器滤波器参数计算,半导体损耗计算,逆变电感参数设计损耗计算 mathcad格式输出,方便修改 同时支持plecs损耗仿真,基于plecs的闭环仿真,电压外环,电流内环
- 毒舌(解锁版).apk
- 显示HEX、S19、Bin、VBF等其他汽车制造商特定的文件格式
- 操作系统实验 Ucore lab5
- 8bit逐次逼近型SAR ADC电路设计成品 入门时期的第三款sarADC,适合新手学习等 包括电路文件和详细设计文档 smic0.18工艺,单端结构,3.3V供电 整体采样率500k,可实现基
- 操作系统实验 ucorelab4内核线程管理
- 脉冲注入法,持续注入,启动低速运行过程中注入,电感法,ipd,力矩保持,无霍尔无感方案,媲美有霍尔效果 bldc控制器方案,无刷电机 提供源码,原理图
- Matlab Simulink#直驱永磁风电机组并网仿真模型 基于永磁直驱式风机并网仿真模型 采用背靠背双PWM变流器,先整流,再逆变 不仅实现电机侧的有功、无功功率的解耦控制和转速调节,而且能实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


