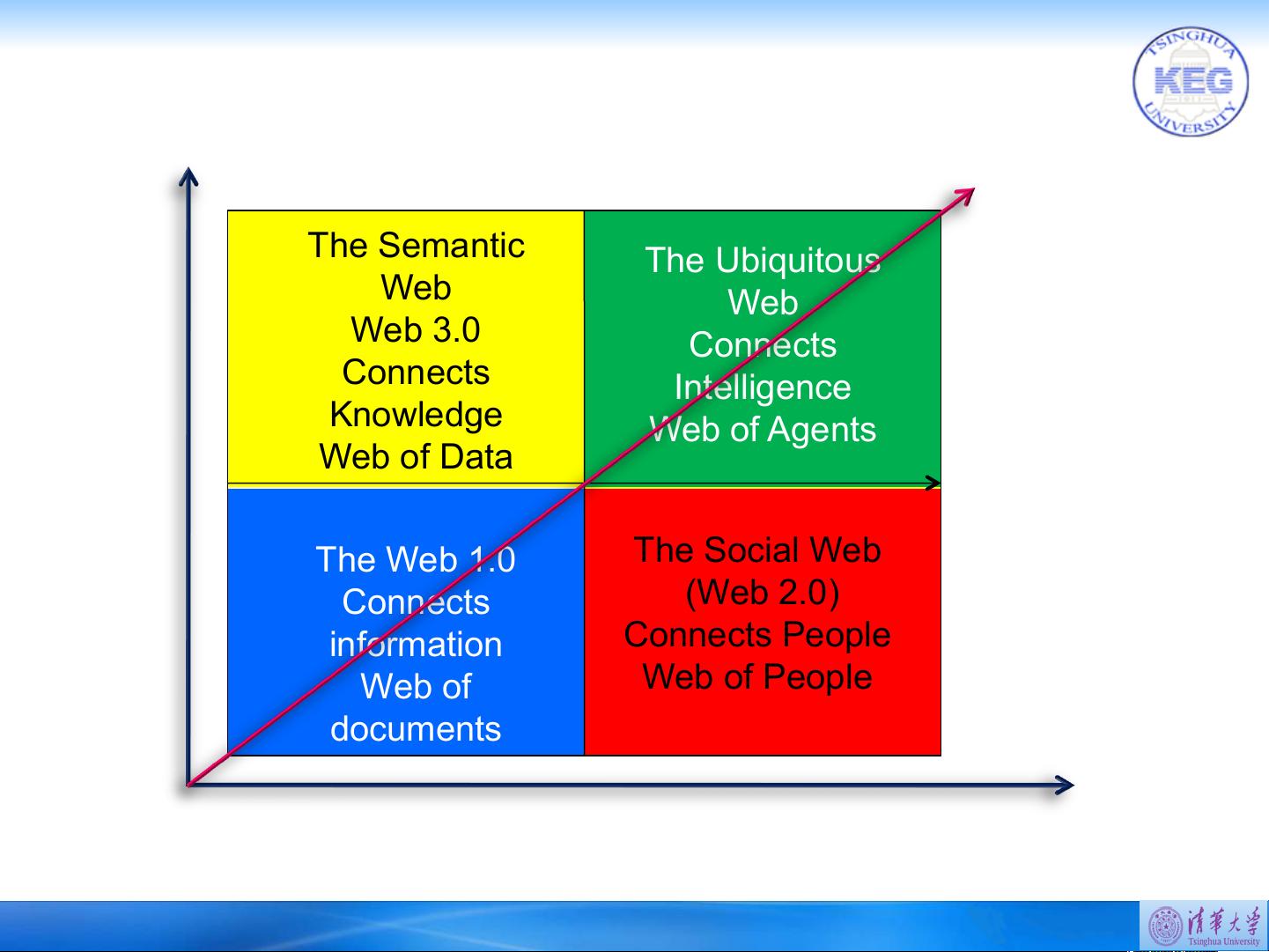
5
Philosophy of ontology
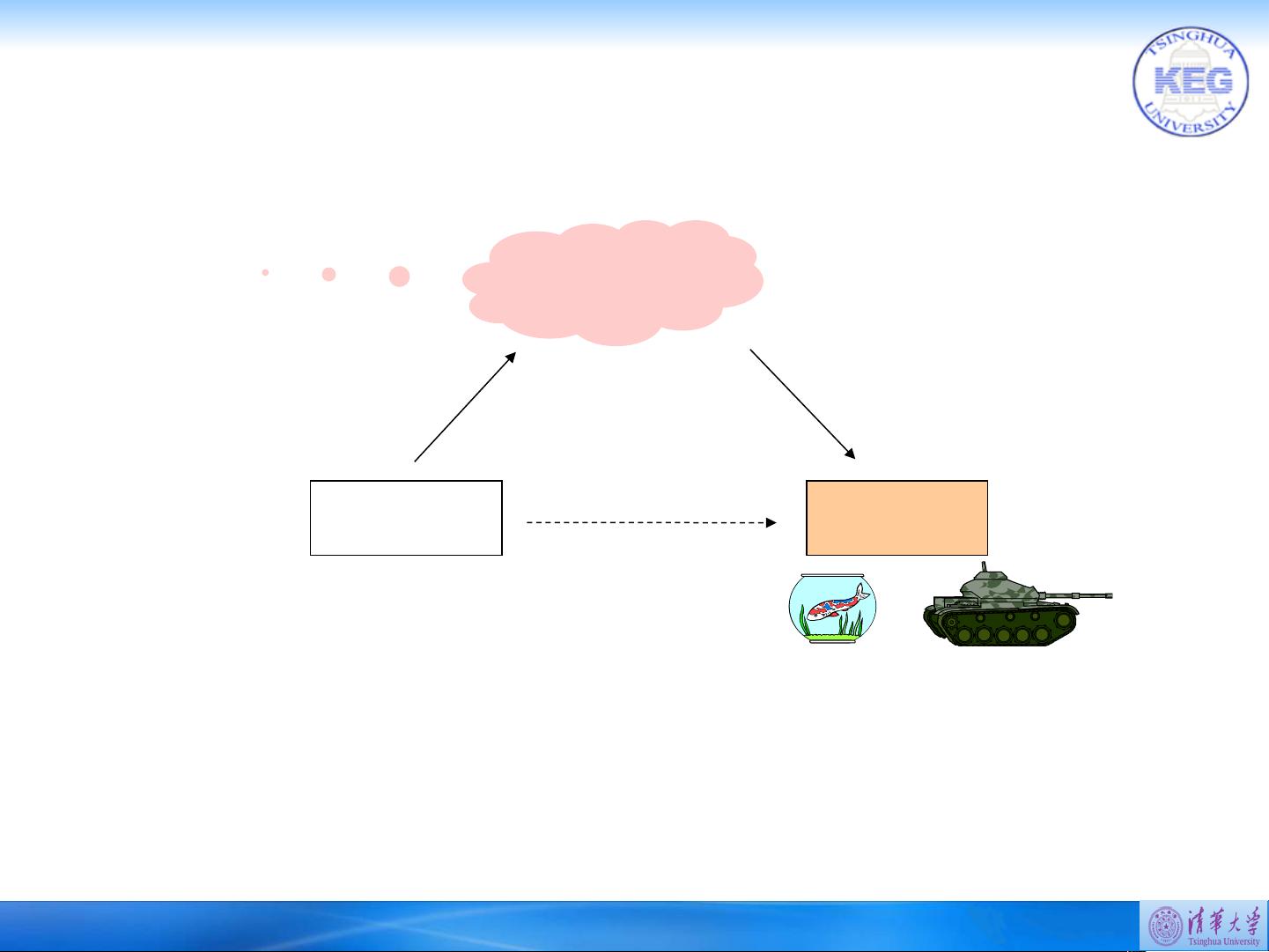
! Concept triangle
“Tank“
Referent Form
Stands
for
Relates to
activates
Concept
[Ogden, Richards,
1923]
?
Ontology is the philosophical study of the nature of being, becoming,
existence, or reality, as well as the basic categories of being and
their relations. --- Wikipedia