【数据分析与数据挖掘课程 R语言数据挖掘实战教程 第3章 决策树分类模型】深入讲解了使用R语言实现决策树分类模型的过程及其在不同领域的应用。决策树是一种直观的机器学习算法,常用于分类任务,它通过一系列的判断规则形成一棵树状结构,以帮助我们理解数据并做出预测。
在引言部分,作者通过幽默的例子“如何找男朋友”来引出数据决策的重要性,随后给出一个具体案例来阐述决策树的应用,强调了决策树在现实世界的广泛应用,如银行的贷款风险评估、电信行业的客户流失预测、互联网的垃圾邮件识别、电商的商品评价分析以及医疗领域中的治疗方案选择等。
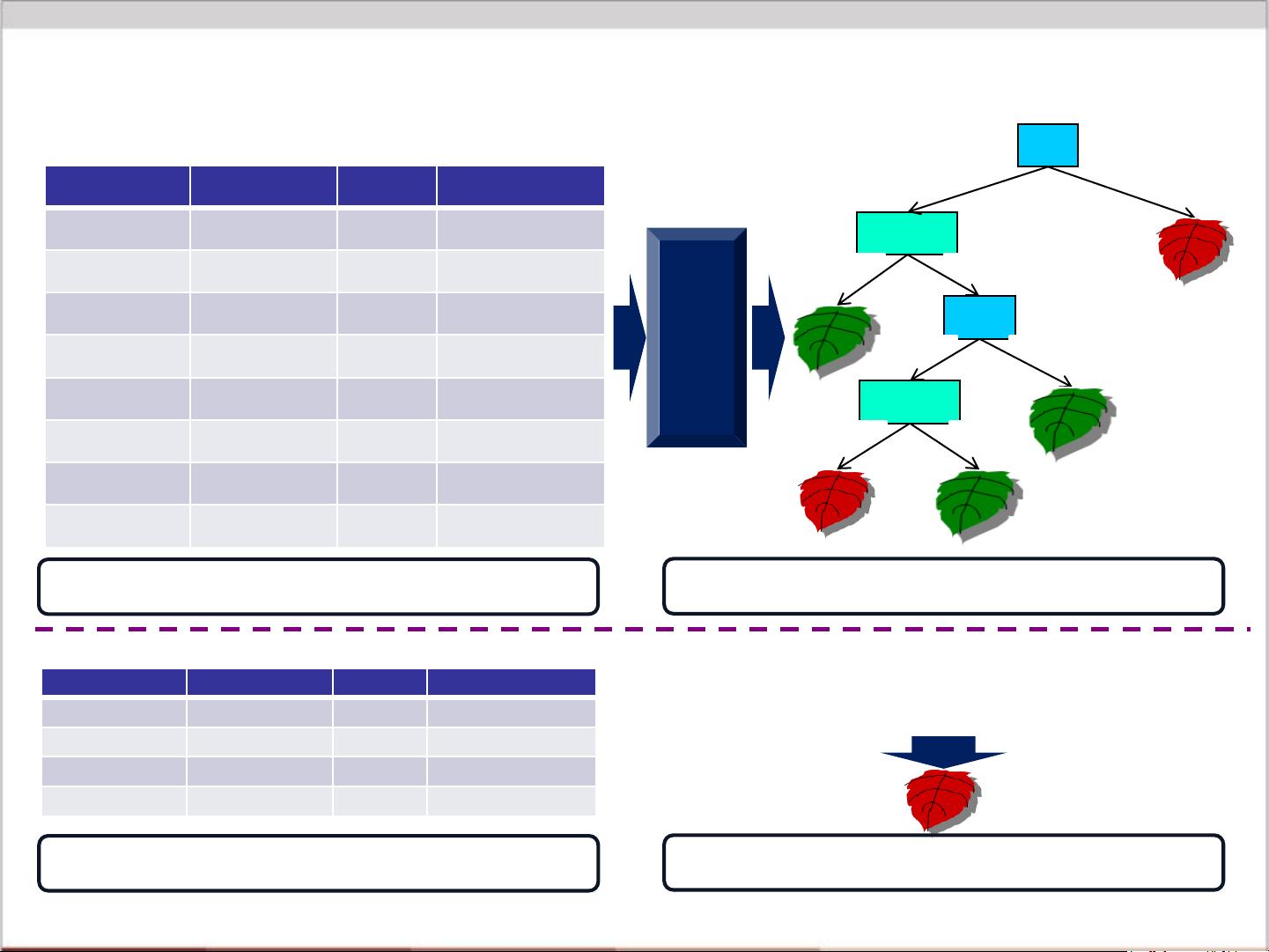
决策树分类算法的核心在于选择最优特征进行分割,以最大化信息增益或基尼不纯度等准则。算法大致分为以下几步:
1. 从所有训练样本开始,如果所有样本属于同一类别,树生长结束。
2. 否则,选择能最好区分样本的特征作为分割点。
3. 根据特征的取值创建分支,继续对子集进行划分。
4. 这一过程递归进行,直到满足停止分裂的条件,如分支主要类别占比超过阈值、叶节点样本数低于设定值或达到最大树深度。
在模型效果评估方面,通常使用测试集来验证模型的泛化能力,通过准确率、精确率、召回率、F1分数等指标来衡量模型性能。此外,交叉验证也是评估模型稳定性的重要手段。
R语言提供了许多包来实现决策树,如`rpart`包。实战环节会指导读者如何使用R语言构建决策树模型,包括数据预处理、模型构建、结果可视化和模型优化等步骤。例如,通过训练集训练模型,然后用测试集评估模型的预测效果,如示例中的Sandy Jones、Bill Lee等人的贷款风险预测。
然而,决策树也存在一些常见问题,如过拟合(模型过于复杂,对训练数据拟合过度)、欠拟合(模型过于简单,无法捕捉数据的复杂性)以及对缺失值和异常值敏感等。解决这些问题的对策可能包括剪枝、调整树的复杂度参数、使用随机森林或梯度提升树等集成方法。
决策树是一种强大的工具,它以易于理解的方式处理复杂的数据分类问题。在R语言中,通过理解和实践,我们可以有效地构建和应用决策树模型,解决各种实际问题,并通过不断迭代和优化提升模型的预测性能。