Python数据挖掘项目开发实战_用决策树预测NBA获胜球队_编程案例实例详解课程教程.pdf
版权申诉

3.1 加载数据集 31
1
2
3
4
5
12
6
7
8
9
10
11
用决策树预测获胜球队
本章介绍另一种分类算法——决策树,用它预测NBA篮球赛的获胜球队。比起其他算法,决
策树有很多优点,其中最主要的一个优点是决策过程是机器和人都能看懂的,我们使用机器学习
到的模型就能完成预测任务。正如我们将在本章讲到的,决策树的另一个优点则是它能处理多种
不同类型的特征。
本章主要内容有:
用pandas库加载、处理数据
决策树
随机森林
对真实数据集进行数据挖掘
创建新特征,用强有力的框架对其进行测试
3.1 加载数据集
本章将介绍怎样预测NBA获胜球队。如果你看过NBA,可能知道比赛中两支球队比分咬得
很紧,难分胜负,有时最后一分钟才能定输赢,因此预测赢家很难。很多体育赛事都有类似的特
点,预期的大赢家也许当天被另一支队伍给打败了。
以往很多对体育赛事预测的研究表明,正确率因体育赛事而异,其上限在70%~80%之间。
体育赛事预测多采用数据挖掘或统计学方法。
3.1.1 采集数据
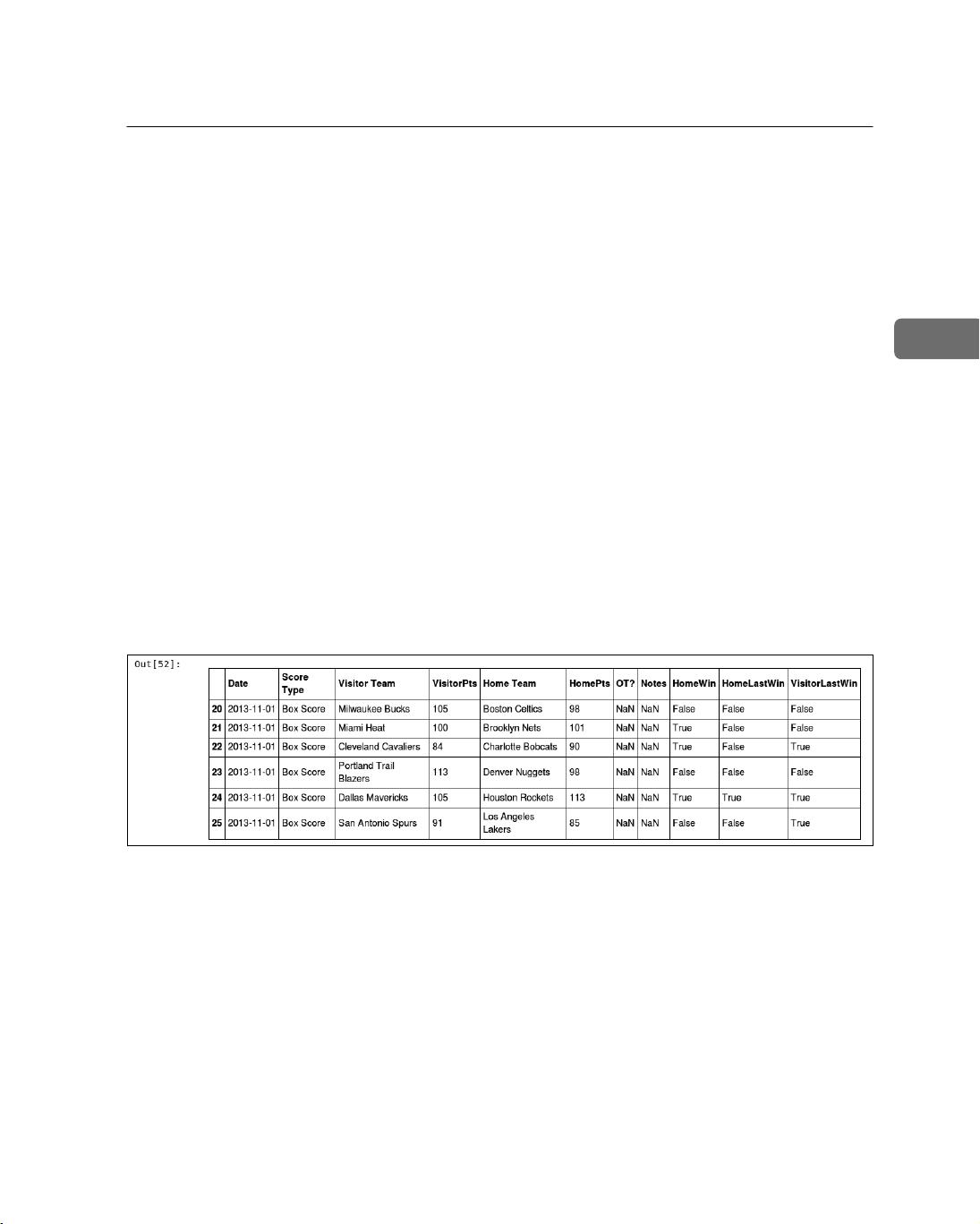
我们将使用NBA 2013
—
2014赛季的比赛数据。http://Basketball-Reference.com网站提供了NBA
及其他赛事的大量资料和统计数据。请按以下方法下载数据。
(1) 在浏览器中打开http://www.basketball-reference.com/leagues/NBA_2014_games.html。
(2) 点击标题Regular Season旁边的Export按钮。



剩余34页未读,继续阅读













- 1
- 2
前往页