Python爬虫入门:如何爬取招聘网站并进行分析
需积分: 50 173 浏览量
2018-06-13
12:14:30
上传
评论 30
收藏 1021KB PDF 举报


0 前言
工作之余,时常会想能做点什么有意思的玩意。互联网时代,到处都是互联网思维,
大数据、深度学习、人工智能,这些新词刮起一股旋风。所以笔者也赶赶潮流,买
了本 Python 爬虫书籍研读起来。
网络爬虫,顾名思义就是将互联网上的内容按照自己编订的规则抓取保存下来。理
论上来讲,浏览器上只要眼睛能看到的网页内容都可以抓起保存下来,当然很多网
站都有自己的反爬虫技术,不过反爬虫技术的存在只是增加网络爬虫的成本而已,
所以爬取些有更有价值的内容,也就对得起技术得投入。
1 案例选取
人有 1/3 的时间在工作,有一个开心的工作,那么 1/3 的时间都会很开心。所以我
选取招聘网站来作为我第一个学习的案例。
前段时间和一个老同学聊天,发现他是在从事交互设计(我一点也不了解这是什么
样的岗位),于是乎,我就想爬取下前程无忧网(招聘网_人才网_找工作_求职_上
前程无忧)上的交互设计的岗位需求:
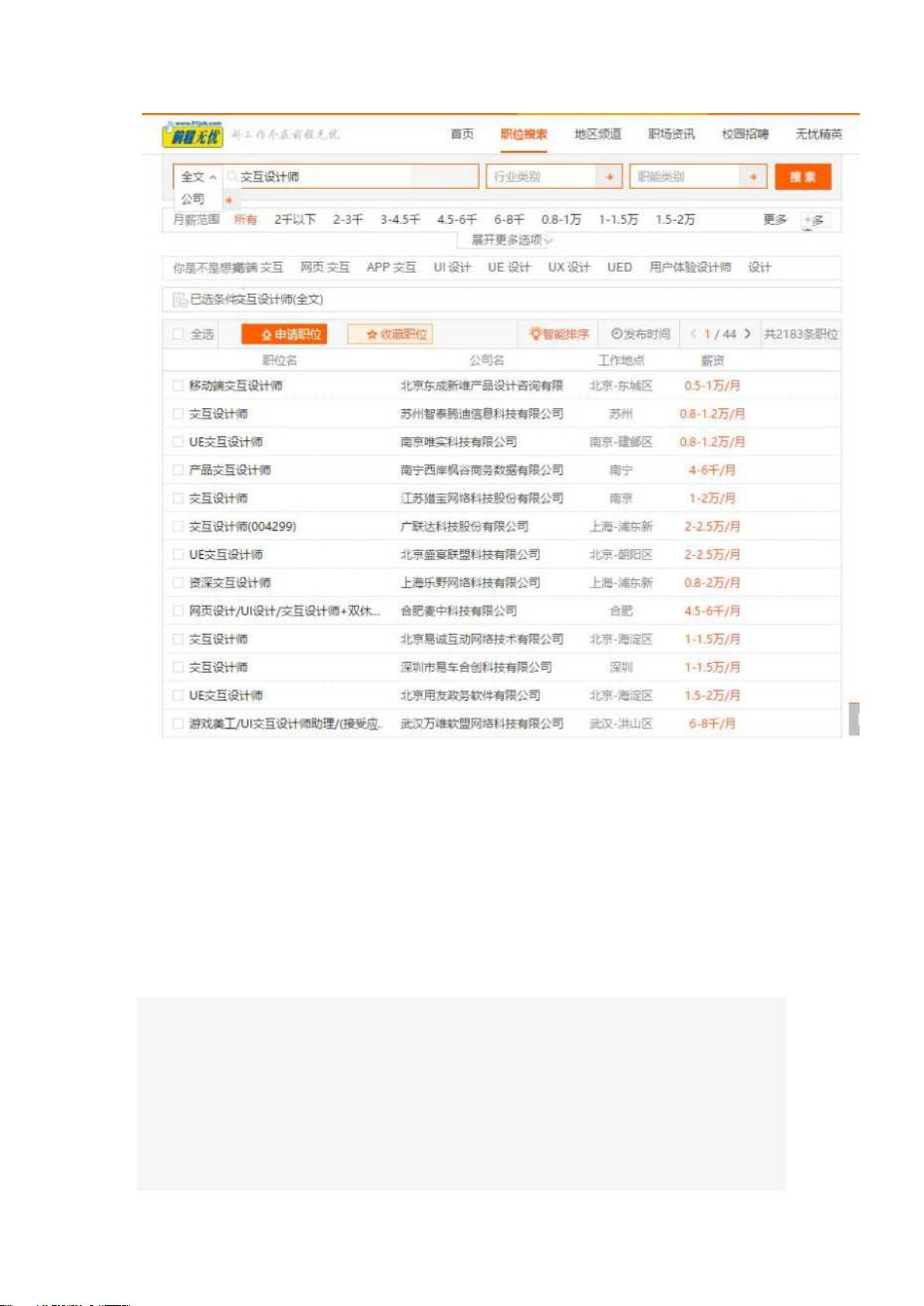
剩余14页未读,继续阅读
资源评论













