
pandas 基本知识
【基本概念】
1、Series 对象用来保存单列数据,DataFrame 对象用来保存多列数据,可以认为是多个 Series 对象的
组合,每一列都是一个 Series 对象。
2、索引又叫标签、标题,是每一行和每一列的标记,通过列索引 columns 和行索引 index 可以用来查
看和修改数据的值,索引值本身也可以修改。
3、每个函数都有自己的必选参数和可选参数(不写为默认值),绝大多数函数默认对列数据进行处理,
会生成一个新对象来保存结果,不直接修改原对象的值。
说明:本文中,
可选参数用斜体字表示
。
默认库已导入:import pandas as pd
一、对象的创建
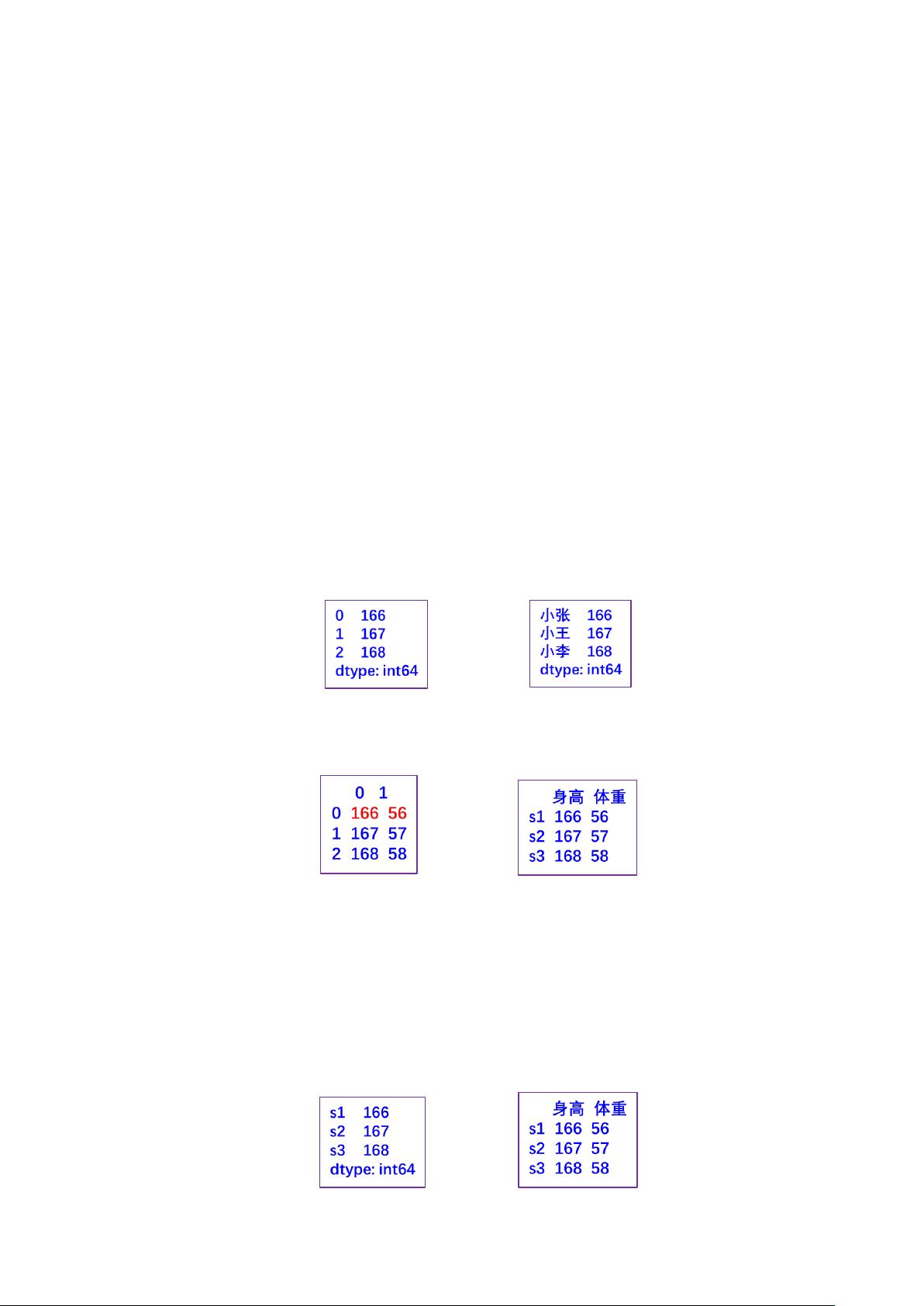
1、把列表转换为对象(一维列表创建 Series 对象,二维列表创建 DataFrame 对象)
要点:
1、列表中的一个元素对应着图中的一行数据,用 index 属性和 columns 参数可以指定行列索引。
2、Series 对象只有行索引,没有列索引,不指定索引时,默认索引都是 0、1、2、3 …
例:
s1=pd.Series([166,167,168])
s2=pd.Series([166,167,168],
index=[“小张”,“小王”,“小李"]
)
s1 s2
df1=pd.DataFrame([ [166,56], [167,57], [168,58] ])
df2=pd.DataFrame([ [166,56], [167,57], [168,58]],
index=["s1","s2","s3"],columns=["身高","体重"]
)
df1 df2
2、把字典转换为对象
要点:
1、Series 对象中,键代表行索引,键值代表行数据
2、DataFrame 对象中,键代表列索引,键值代表一列数据。
例:
s3=pd.Series(“s1”:166,“s2”:167,“s3":168)
df3=pd.DataFrame({"身高":[166,167,168],"体重":[56,57,58]},
index=["s1","s2","s3"]
)
s3 df3

qq_15378927
- 粉丝: 0
- 资源: 1









最新资源
- C语言为什么经久不衰?从嵌入式到操作系统,揭秘底层开发的王者语言.pdf
- C语言头文件设计原则:避免重复包含与模块化编程技巧.pdf
- C语言文件操作全攻略:加密存储+异常处理最佳实践.pdf
- C语言文件操作全攻略:从文本读写到二进制序列化.pdf
- C语言位运算实战指南:状态标志、掩码与位域的精妙用法.pdf
- C语言文件操作实战:从文本读写到CSV解析的完整案例库.pdf
- C语言项目实战:手把手教你开发通讯录管理系统.pdf
- C语言项目实战:从零开发学生管理系统.pdf
- C语言项目实战:学生成绩管理系统开发全流程.pdf
- C语言效率优化技巧:从时间复杂度分析到代码重构实战.pdf
- C语言效率革命:VSCode配置+自动化编译的终极工作流.pdf
- C语言新手必看!从HelloWorld到循环结构,手把手避开17个语法陷阱.pdf
- C语言新手必踩的10大坑:段错误、野指针与缓冲区溢出全解析.pdf
- C语言新手必看!17个编译警告背后的致命隐患.pdf
- C语言新手必看:分号漏写、括号不匹配?10分钟掌握语法细节自查表.pdf
- C语言性能优化秘籍:从寄存器变量到汇编级调优.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0