
算术编码用 c 语言实现
(2010-07-07 23:43:59)
转载
标签:
杂谈
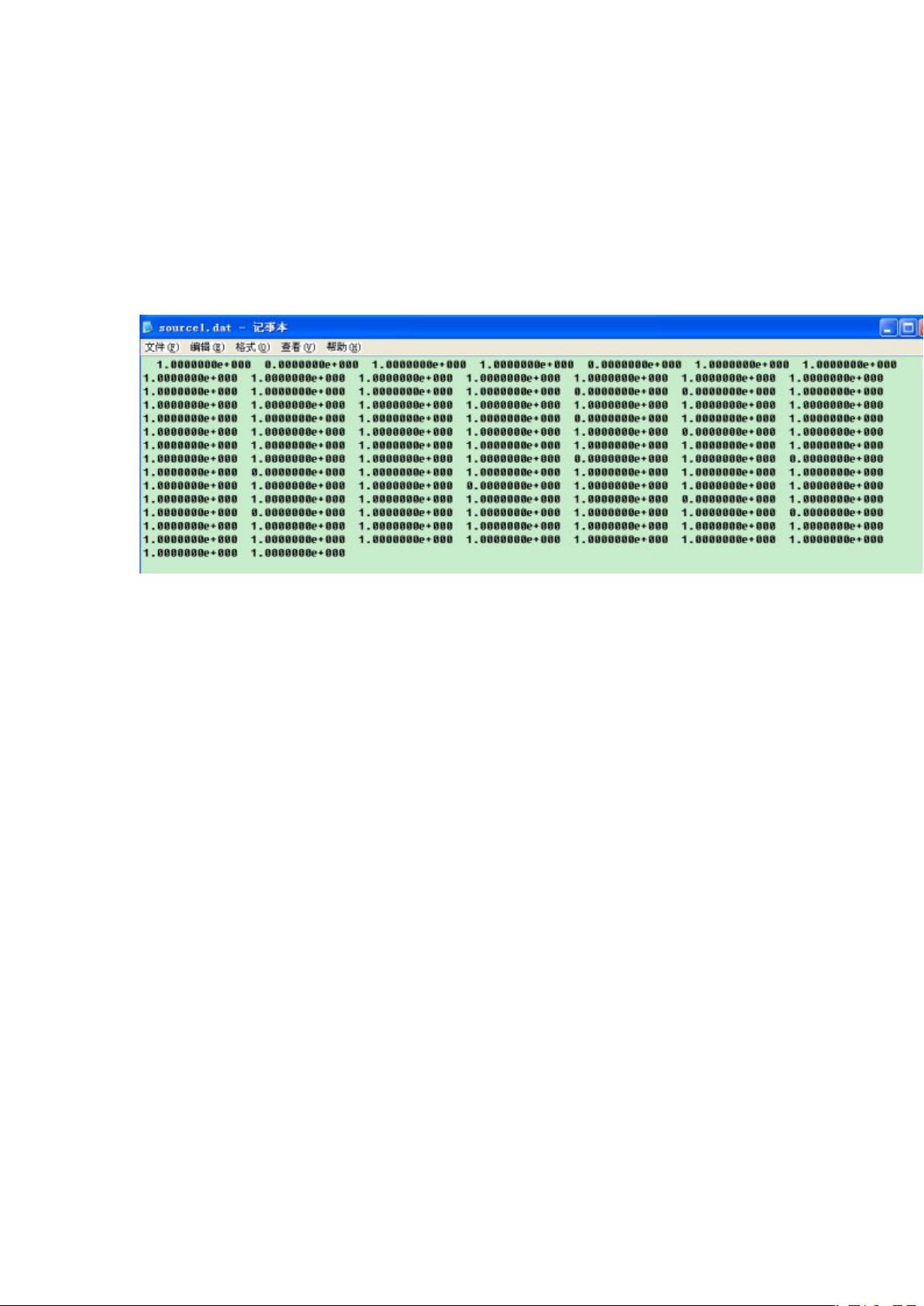
描述:在 source1.dat 文件中有 100 个数据,其中,0 的概率为 1/8,1 的概率为 7/8.用算术
编码进行压缩。
程序如下:
//============================================================================
// Name : suanshcoding.cpp
// Author : 朗月清风
// Version :1.0
// Copyright : All rights Reserved by 2010
// Description : 从 source1.dat 文件中读取信息,即 100 个 0、1 码,完成算术编码,并给
// 出了译码及验证。
// Department :upc
//============================================================================
#include<stdio.h>
#include<math.h>
#define max 100
void main()
{
FILE *fp;
int i=0;
int n;
long double high;//上限
long double low;//下限
long double d;//间距
long double buf[max]; //大数组,暂存读取的数据
long double decode[max]; //存解码后的结果
资源评论


omyligaga
- 粉丝: 87
- 资源: 2万+









最新资源
- coco.names 文件
- (源码)基于Spring Boot和Vue的房屋租赁管理系统.zip
- (源码)基于Android的饭店点菜系统.zip
- (源码)基于Android平台的权限管理系统.zip
- (源码)基于CC++和wxWidgets框架的LEGO模型火车控制系统.zip
- (源码)基于C语言的操作系统实验项目.zip
- (源码)基于C++的分布式设备配置文件管理系统.zip
- (源码)基于ESP8266和Arduino的HomeMatic水表读数系统.zip
- (源码)基于Django和OpenCV的智能车视频处理系统.zip
- (源码)基于ESP8266的WebDAV服务器与3D打印机管理系统.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


