
AlphaGoZero-它的工作原理和原因
2017年11月2日由蒂姆
2016年3月,DeepMind的AlphaGo成为第一个击败顶级人类Go玩家的AI。这
个版本的AlphaGo-AlphaGoLee--在训练过程中使用了世界上最好的玩家的
大量Go游戏。几天前发布了一篇新论文,详细介绍了一个新的神经网络--
-AlphaGoZero--它不需要人类展示如何玩Go。它不仅优于所有以前的Go玩
家,无论是人类还是机器,只需要三天的训练时间就可以。本文将解释它的工作
原理和原因。
蒙特卡洛树搜索
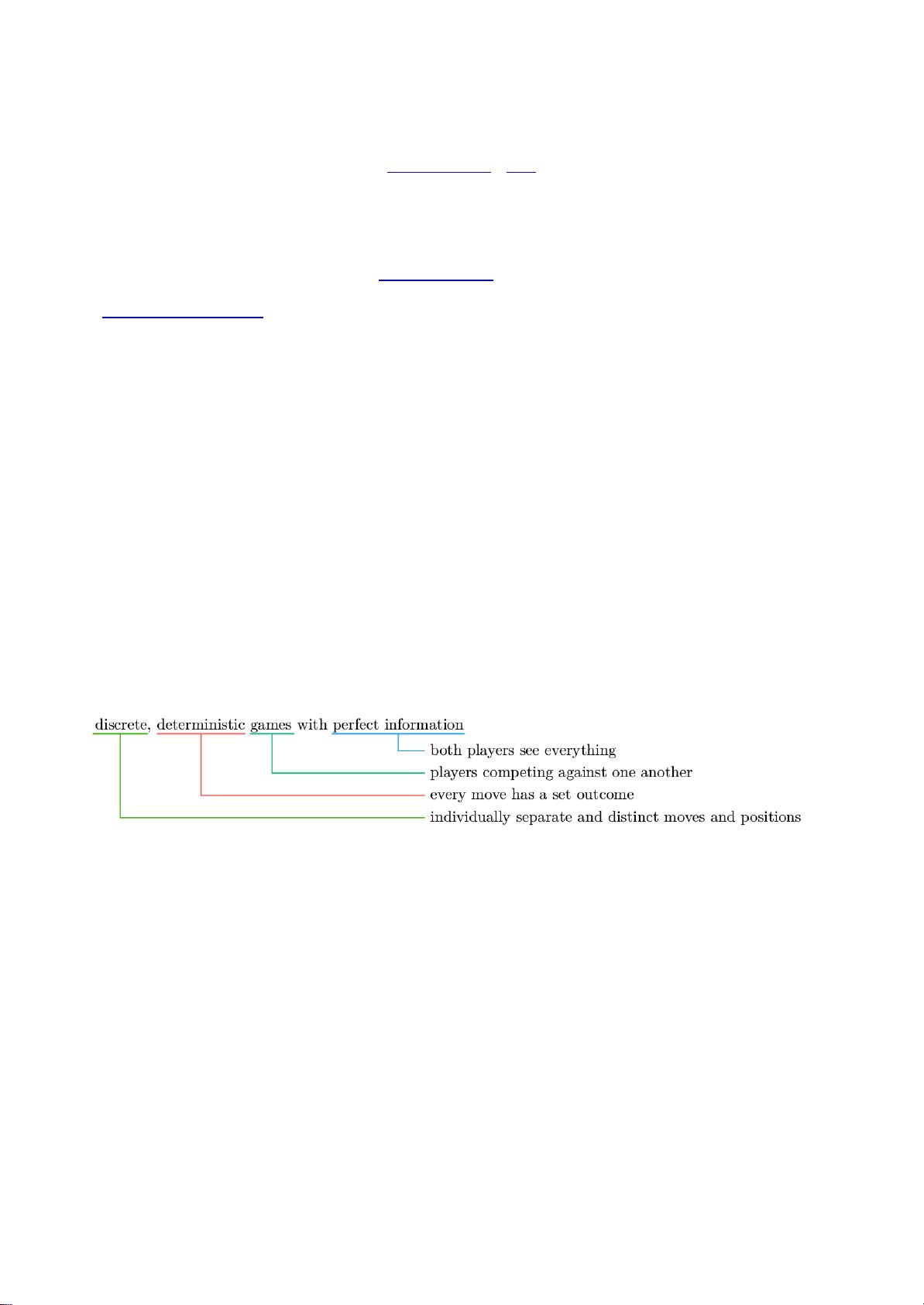
用于编写机器人以播放具有完美信息的离散确定性游戏的转向算法是蒙特卡罗树
搜索(MCTS)。玩Go,象棋或棋子等游戏的机器人可以通过尝试所有游戏,
然后检查对手的所有可能响应,之后所有可能的移动等等来确定它应该做出什么
样的移动。对于像Go这样的游戏数量移动尝试增长非常快。
蒙特卡罗树搜索将根据其认为的优势选择性地尝试移动,从而将其精力集中在最
有可能发生的移动上。
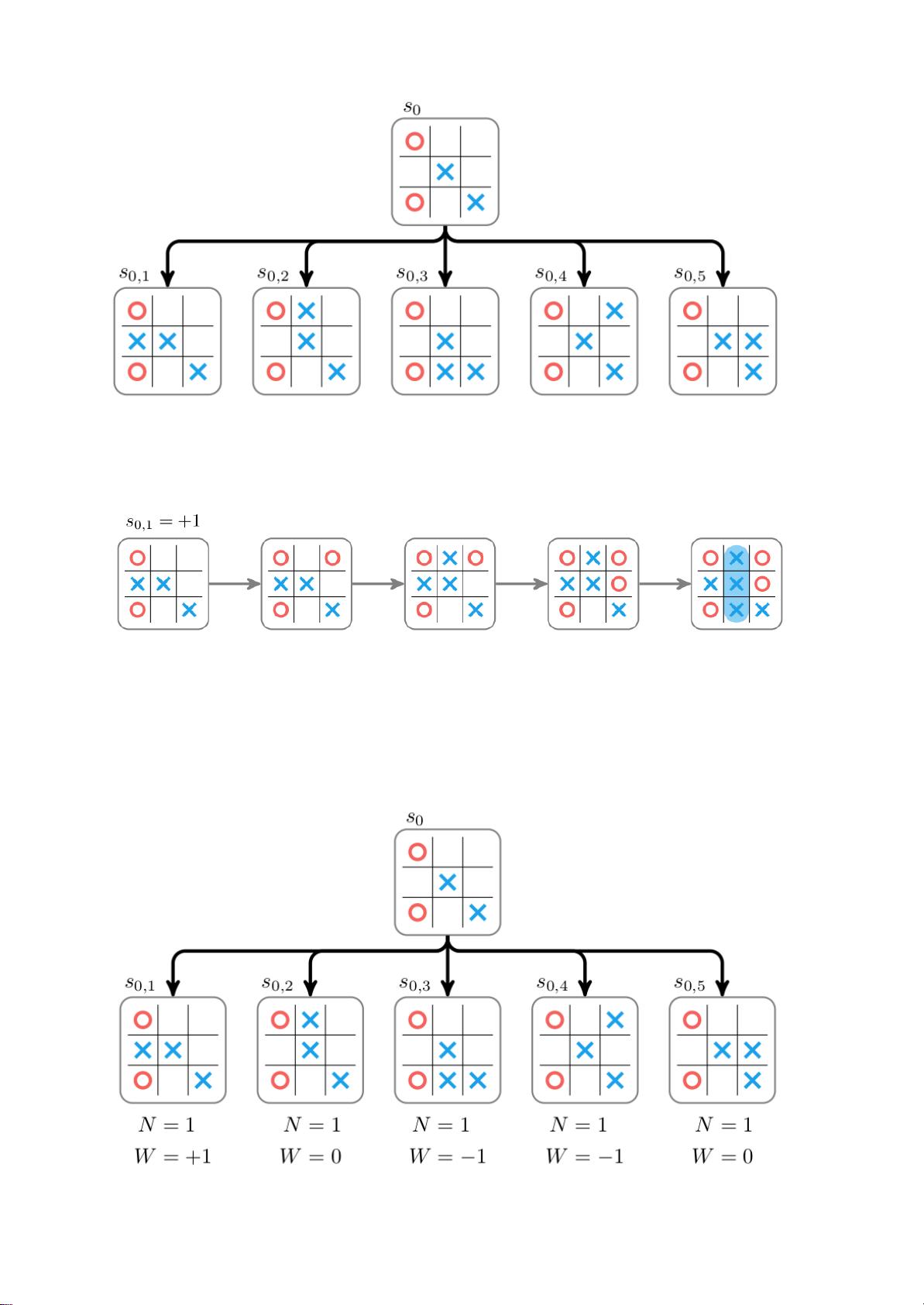
从技术上讲,该算法的工作原理如下。游戏进行中处于初始状态小号0,轮到玩
了。机器人可以从一组动作A中进行选择。蒙特卡罗树搜索以一个由s的单个
节点组成的树开始0。该节点扩展通过尝试每一个动作一个∈一并为每个动作
构建相应的子节点。下面我们展示一个tic-tac-toe游戏的扩展:
剩余10页未读,继续阅读
资源评论


深宜
- 粉丝: 0
- 资源: 27









最新资源
- 基于Comsol三次谐波的物理现象,大子刊NC复现报告:手性BIC超表面下的远场偏振与手性透射图示分析-电场、二维能带图解读及Q因子图展现所见即所得的光学效应 ,平面手征超表面研究:连续介质中的三次
- 人工智能&深度学习:LSTM 文本分类实战 - 基于 THUCNews 数据集的 Python 源码资源(源码+数据集+说明)
- MATLAB程序专为非全向移动机器人设计的扩展卡尔曼滤波(EKF)数据处理工具箱,精准融合ADS-B与GPS数据,高效状态估计解决方案,MATLAB程序优化:非全向移动机器人EKF状态估计与飞行数据处
- 简易图像处理软件,与PS工具类似
- iOS swift工具类使用
- AR.js 完整资源包,可以完整的引用
- 西门子PLC与三台欧姆龙温控器通讯程序:实现温度控制及监控,支持轮询通讯与故障恢复功能,PLC与触摸屏集成设置温度,支持扩展及详细注释 ,西门子PLC与三台欧姆龙温控器通讯程序:实现温度控制及监控,支
- 这份文档的内容并非技术性文章,而是一段歌词片段,无法按照技术文档的要求生成标准标题 若需要总结,该文档包含了一段歌词,表达了关于期待与未知相遇的主题 但由于内容不足以及非技术性质,无法提供更详细总
- .safetensors转换成.GGUF所需工具cmake
- 三相光伏并网逆变器仿真:PV升压逆变并网系统中的电压电流双环控制与SVPWM策略研究,三相光伏并网逆变器仿真研究:PV光伏boost升压逆变并网系统之电压外环与电流内环SVPWM控制机制探讨,三相光伏
- 《基于信捷PLC的7轴伺服插补联动设备的设计与实现-喷涂机程序与牵引示教功能》,信捷PLC驱动7轴伺服插补联动设备-XD5-48T6-E牵引示教功能与喷涂机程序解析,信捷PLC7轴伺服插补联动XD
- MPC模型预测控制:从原理到代码实现,涵盖双积分、倒立摆、车辆运动学与动力学跟踪控制系统的详细文档与编程实践,MPC模型预测控制原理到代码实现:双积分、倒立摆、车辆运动学与动力学跟踪控制案例详解,mp
- 车路协同C-V2X港口应用分析
- gradle-6.1.1.zip资源下载
- 用dockerfile打包带有nginx-monitor-vts模块的nginx镜像
- .safetensors转换成.GGUF所需工具ccache
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


