
Coursera机器学习笔记
Coursera机器学习笔记机器学习笔记(〇〇)-目录目录
Coursera机器学习笔记(〇)-目录
Coursera机器学习笔记(一) - 监督学习vs无监督学习
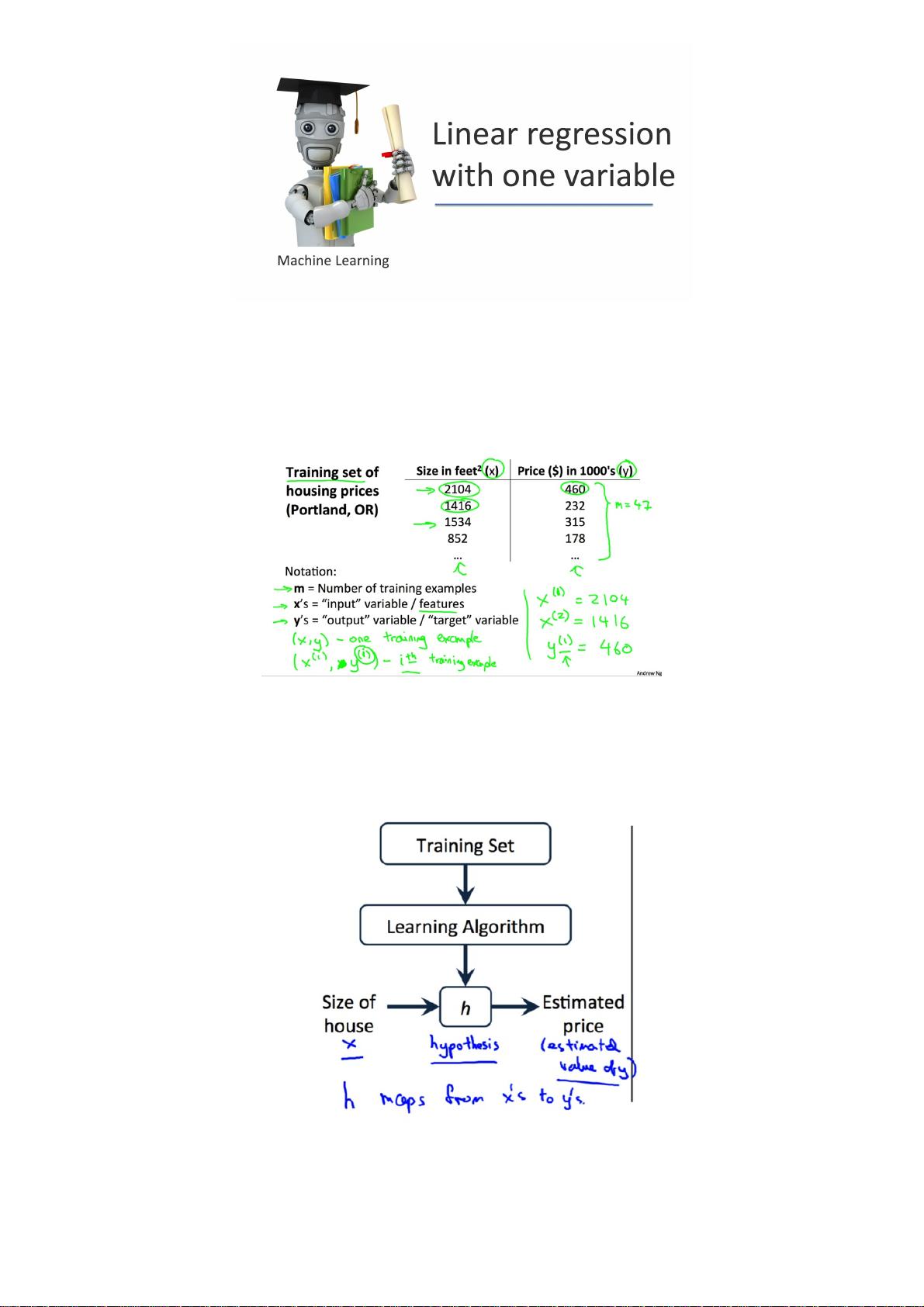
Coursera机器学习笔记(二) - 单变量线性回归
Coursera机器学习笔记(三) - 多变量线性回归
Coursera机器学习笔记(四) - Octave教程
Coursera机器学习笔记(五) - Logistic Regression
Coursera机器学习笔记(六) - 正则化
Coursera机器学习笔记(七) - 来自吴恩达的狗粮和鸡汤
Coursera机器学习笔记(八) - 神经网络(上)
Coursera机器学习笔记(九) - 神经网络(下)
Coursera机器学习笔记(十) - 机器学习经验方法总结
Coursera机器学习笔记(十一) - 机器学习系统设计
Coursera机器学习笔记(十二) - SVM
Coursera机器学习笔记(十三) - 非监督学习
Coursera机器学习笔记(十四) - 数据降维
Coursera机器学习笔记(十五) - 异常检测
Coursera机器学习笔记(十六) - 推荐系统
Coursera机器学习笔记(十七) - 大规模机器学习
Coursera机器学习笔记(十八) - Application Example Photo OCR
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------
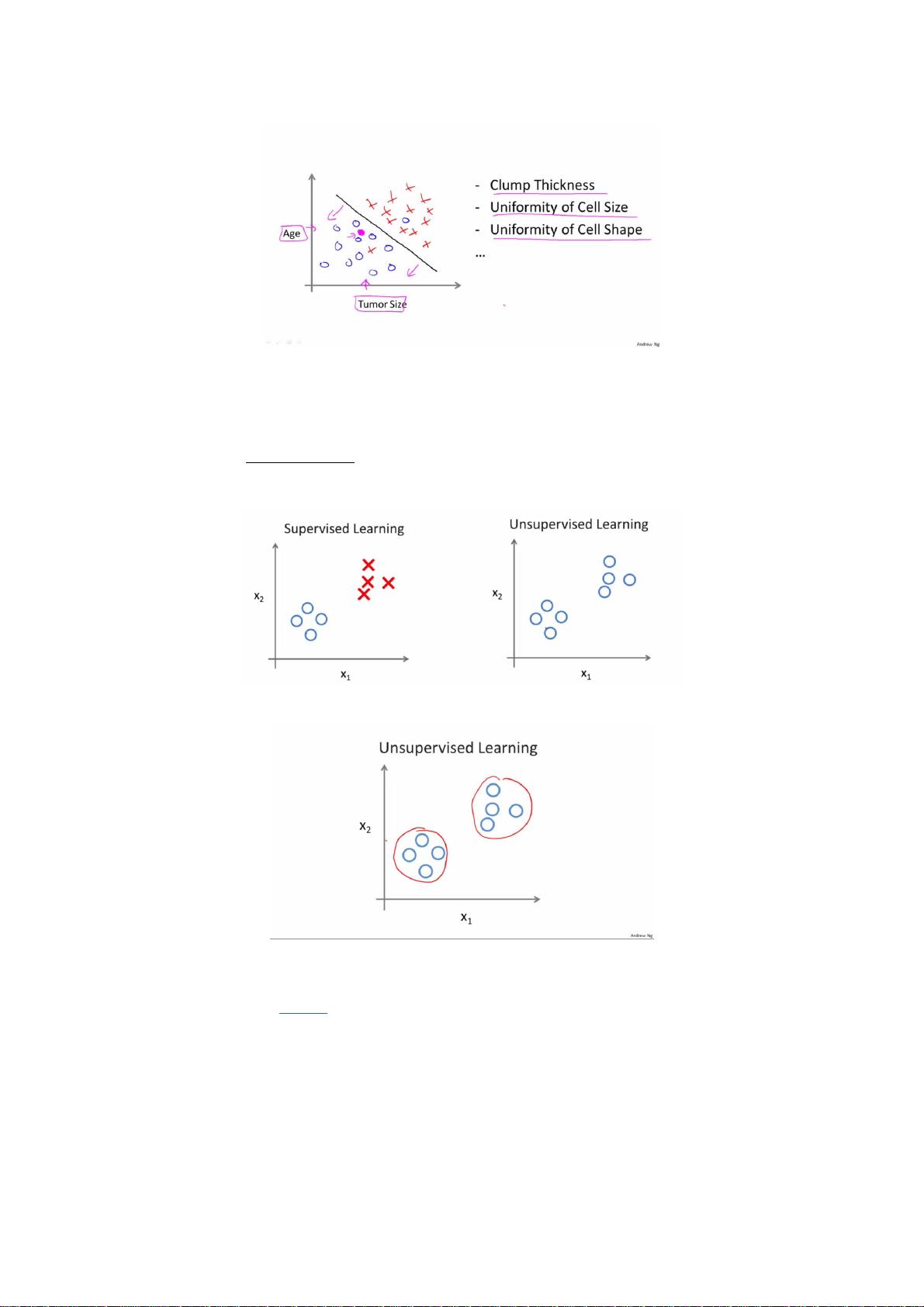
Coursera机器学习笔记机器学习笔记(一一) - 监督学习监督学习vs无监督学习无监督学习


剩余107页未读,继续阅读
资源评论













