

Speeding Up Multi-Relational Data Mining
Anna Atramentov, Vasant Honavar
Artificial Intelligence Research Laboratory,
Computer Science Department, Iowa State University,
226 Atanasoff Hall, Ames, IA 50011-1040, USA,
{anjuta, honavar}@cs.iastate.edu
Abstract
We present a general approach to speeding up a
family of multi-relational data mining algorithms
that construct and use selection graphs to obtain the
information needed for building predictive mod-
els (e.g., decision tree classifiers) from relational
database. Preliminary results of our experiments
suggest that the proposed method can yield 1-2 or-
ders of magnitude reductions in the running time
of such algorithms without any deterioration in
the quality of results. The proposed modifications
enhance the applicability of multi-relational data
mining algorithms to significantly larger relational
databases that would otherwise be not feasible in
practice.
1 Introduction
Recent advances in high throughput data acquisition, digital
storage, and communications technologies have made it pos-
sible to gather very large amounts of data in many scientific
and commercial domains. Much of this data resides in rela-
tional databases. Even when the data repository is not a rela-
tional database, it is often convenient to view heterogeneous
data sources as if they were a collection of relations
[
Reinoso-
Castillo, 2002
]
for the purpose of extracting and organizing
information from multiple sources. Thus, the task of learning
from relational data has begun to receive significant attention
in the literature
[
Blockeel, 1998; Knobbe et al., 1999a; Fried-
man et al., 1999; Koller, 1999; Krogel and Wrobel, 2001;
Getoor, 2001; Kersting and De Raedt, 2000; Pfeffer, 2000;
Dzeroski andLavrac, 2001; Dehaspe and Raedt, 1997;Jaeger,
1997; Karalic and Bratko, 1997
]
.
Recently,
[
Knobbe et al., 1999a
]
outlined a general frame-
work for multi-relational data mining which exploits struc-
tured query language (SQL) to gather the information needed
for constructing classifiers (e.g., decision trees) from multi-
relational data. Based on this framework, several algorithms
for multi-relational data mining have been developed. Exper-
iments reported by
[
Leiva, 2002
]
have shown that MRDTL –
a multi-relational decision tree learning algorithm is compet-
itive with other approaches to learning from relational data.
One common feature of all algorithms based on the multi-
relational data mining frameworkproposedby
[
Knobbe et al.,
1999a
]
is their use of selection graphs to query the relevant
databases to obtain the information (e.g., statistics) needed
for constructing a model. Our experiments with MRDTL re-
vealed that the executionof queries encoded by such selection
graphs was a major bottleneck in terms of the running time of
the algorithm. Hence, this paper describes an approach for
significantly speeding up some of the most time consuming
components of such algorithms. Preliminary results of our
experiments suggest that the proposed method can yield one
to two orders of magnitude speedups in the case of MRDTL.
We expect similar speedups to be obtained with other multi-
relational data mining algorithms which construct and use se-
lection graphs.
The rest of the paper is organized as follows: in Section 2
we overview multi-relational data-mining framework, in Sec-
tion 3 we describe the speed up scheme for this framework
and in Section 4 we show the experimental results that we
obtained applying the scheme.
2 Multi-Relational Data Mining
2.1 Relational Databases
A relational database consists of a set of tables D =
{X
1
, X
2
, ...X
n
}, and a set of associations between pairs of
tables. In each table a row represents description of one
record. A column represents values of some attribute for the
records in the table. An attribute A from table X is denoted
by X.A.
Definition 2.1 The domain of the attribute X.A is denoted as
DOM (X.A) and is defined as the set of all different values
that the records from table X have in the column of attribute
A.
Associations between tables are defined through primary
and foreign key attributes in D.
Definition 2.2 A primary key attribute of table X, denoted
as X.ID, has a unique value for each row in this table.
Definition 2.3 A foreign key attribute in table Y refer-
encing table X, denoted as Y.X
ID, takes values from
DOM (X.ID).
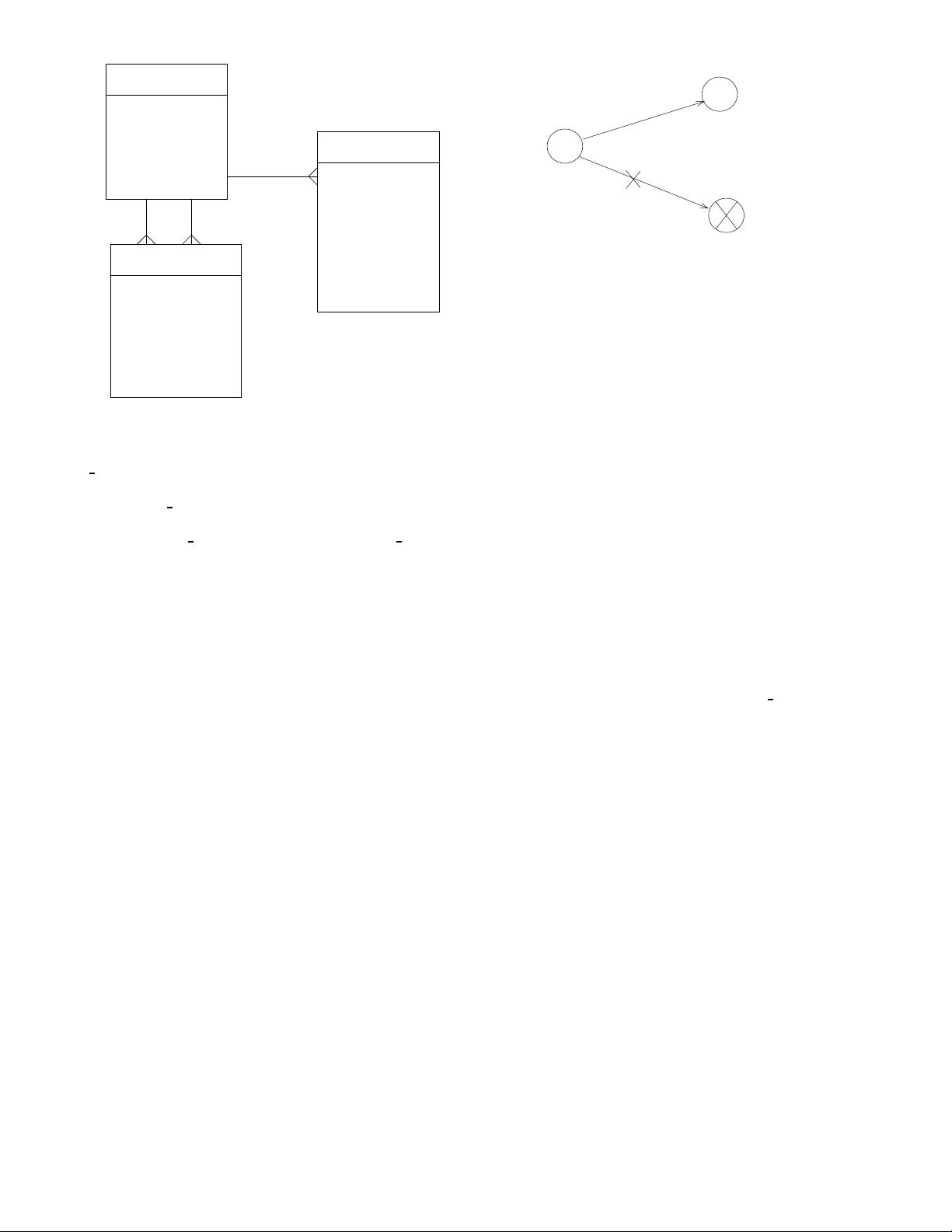
An example of a relational database is shown in Figure
1. There are three tables and three associations between
tables. The primary keys of the tables GENE, COMPO-
SITION, and INTERACTION are: GENE ID, C ID, and
剩余6页未读,继续阅读
资源评论













