

Speeding up packet I/O in virtual machines
Luigi Rizzo, Giuseppe Lettieri, Vincenzo Maffione,
Universit`a di Pisa, Italy
rizzo@iet.unipi.it, http://info.iet.unipi.it/∼luigi/vale/
Abstract
Most of the work on VM network performance has fo-
cused so far on bulk TCP traffic, which covers classical
applications of virtualization. Following popular wis-
dom (and perhaps bad initial experience with de vice
emula tion), completely new “paravirtualized de vices”
(Xenfront, virtio, vmxnet) have been designed and im-
plemented to improve network throughput.
We expect virtualization to become widely used also
for different workloads: packet switching devices and
middleboxes, Software Defined Networks, etc.. These
applications involve very high packet rates that are
problematic not only for the hypervisor (which emulates
network interface s) but also for the host itself (which
switches packets between guests and physical NICs).
In this paper we provide three main results. First, we
demonstrate how rates of millions of packets pe r second
can be achieved even within VMs, with limited but tar-
geted modifications on device drivers, hypervisors and
the host’s virtual switch. Secondly we show that em-
ulation of conventional NICs (e.g., Intel e1000) is per-
fectly capable of achieving such packet rates, without
requiring completely different device models. Finally,
we provide sets of modifications for various use cases
(acting only on the guest, or only on the host, or on
both) and depending on the configuration a nd use case
we can improve the network throughput of a VM by 20
times or more.
These results are important because they enable a
new set of applications within virtual machines. In par-
ticular, our prototype implementation achieves guest-
to-guest speeds of over 1 Mpps with short frames (and
6 Gbit/s with 1500-byte frames) using a conventional
e1000 device, and socket-based sender/receivers. This
is the same speed that we experience running the OS
on bare metal, and a ten-fold speedup over the per-
formance of the original e1000 emula tion, and slightly
better than virtio. Furthermore, we re ach over 5 Mpps
when guests use the ne tma p API.
Our work requires only small changes to device
drivers (about 100 lines, both for FreeBSD and Linux
version of e1000), similarly small modifications to the
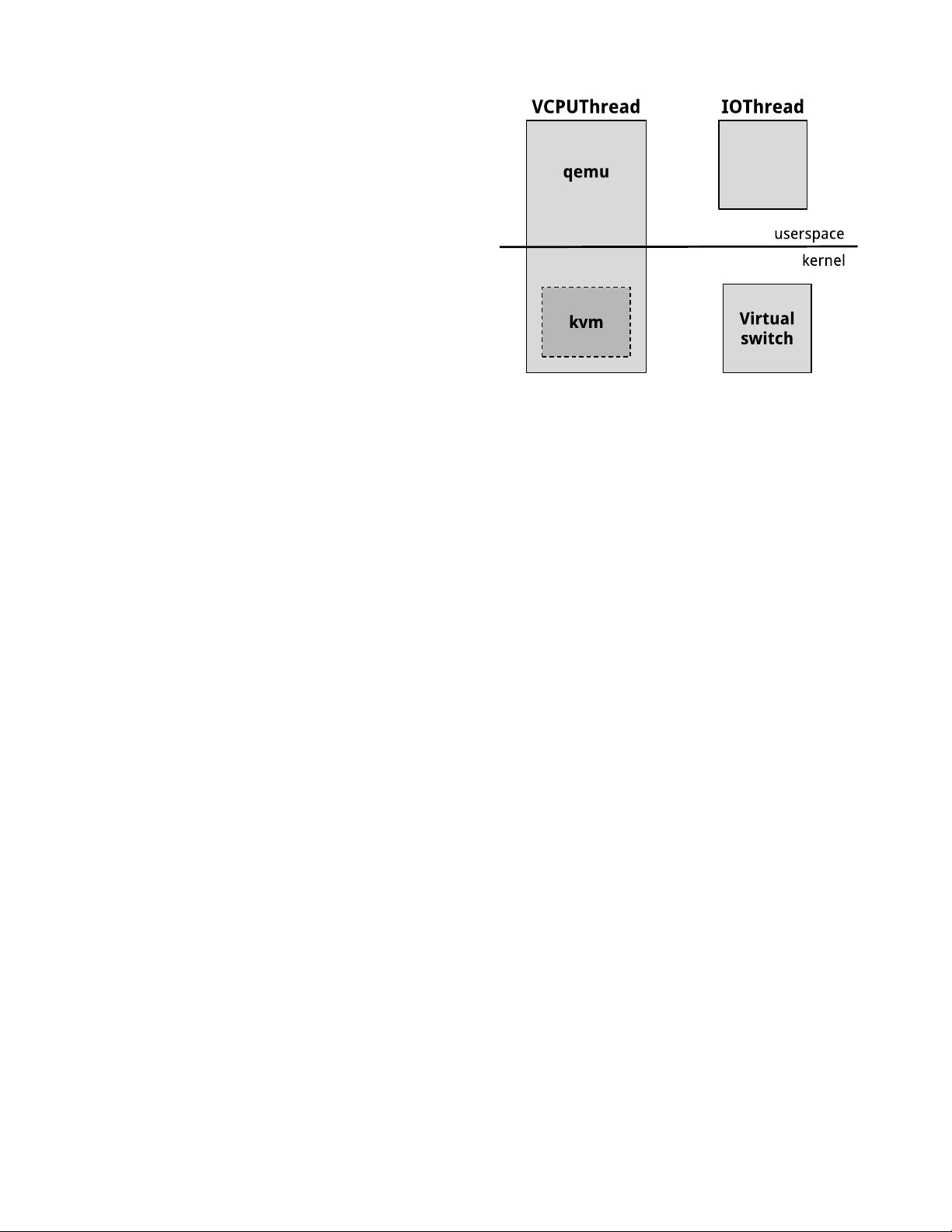
hypervisor (we have a qemu prototype available) and
the use of the VALE sw itch as a network backend. Rel-
evant changes are being incorporated in FreeBSD and
distributed as patches fo r QEMU/Linux.
1. INTRODUCTION
Virtualization is a technology in heavy demand to
implement server consolidation, improve service avail-
ability, and make efficient use of the many cores present
in today’s CPUs. Of course, users want to exploit the
features offered by this new platform without losing too
much (or possibly, anything) of the performance achiev-
able on traditional, dedicated hardware (bare metal).
Over time, ingenious software solutions [5], and later
hardware support [13, 3], have mostly filled the gap for
CPU performance. Likewise, performance for storage
peripherals and bulk network traffic is now comparable
between VMs and bare metal, especially when I/O can
be coerced to use large blocks (e.g. through TSO/RSC)
and limited transaction rates (e.g., say less than 50 K
trans/s).
However a class of applications, made relevant by the
rise of Software Defined Networking (SDN), still strug-
gles under virtualization. Software router s, s w itches,
firewalls and other middleboxes, need to deal with very
high packet rates (millions per second) that are not
amenable to reduction through the usual Network In-
terface Card (NIC) offloading techniques. The “direct
mapping” of portions of vir tualization-aware NICs to
individual VMs can provide some relief, but it has scal-
ability and flexibility constraints.
We then decided to explore solutions to let VMs deal
with millions of packets per second without requiring
special hardware, or imposing massive changes to OSes
or hype rvisors. In this paper we discuss the general
problem of network per formance in virtual machines,
identifying the main causes of performance loss c om-
pared to bare metal, and design and experiment with a
comprehensive set of mechanisms to fill the performance
gap.
Our contribution: in detail, we i) emulate inter rupt
moderation, ii) implement “Send Combining”, a driver-
1
剩余11页未读,继续阅读
资源评论













