





Hadoop3.1.3安装和单机/伪分布式配置

需积分: 0 38 浏览量
更新于2024-06-21
收藏 10.77MB DOC 举报
实验项目名称: Hadoop3.1.3安装和单机/伪分布式配置
一、 实验目的和要求
Hadoop3.1.3安装和单机/伪分布式配置
二、 实验原理
1.Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分 布式即单 Java 进程,方便进行调试。
2. Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
### Hadoop3.1.3安装与单机/伪分布式配置知识点详解
#### 一、实验目的和要求
- **掌握Hadoop3.1.3的安装与配置**:包括单机模式和伪分布式模式。
- **理解Hadoop的工作原理**:特别是其在不同模式下的运行机制。
- **熟悉Hadoop的常用操作**:如文件上传、数据处理等。
#### 二、实验原理
##### 1. Hadoop单机配置(非分布式)
- **定义**:Hadoop的默认模式是非分布式模式,即本地模式。在这种模式下,所有的Hadoop进程都在同一个Java进程中运行。
- **特点**:
- 方便进行调试。
- 单进程运行,便于快速测试代码。
- **适用场景**:适用于开发阶段,进行简单的功能验证和调试。
##### 2. Hadoop伪分布式配置
- **定义**:Hadoop可以在单个节点上以伪分布式模式运行,这意味着虽然只有一个物理节点,但是不同的Hadoop组件(如NameNode和DataNode)会分别运行在不同的Java进程中。
- **特点**:
- 模拟了分布式环境。
- 有助于测试和调试Hadoop应用程序。
- **适用场景**:适合于小型测试环境,能够模拟部分分布式特性,进行初步的功能性和性能测试。
#### 三、主要仪器设备、试剂或材料
- **操作系统**:Ubuntu 18.04 64位。
- **软件工具**:Hadoop 3.1.3。
- **辅助工具**:SSH、Java环境。
#### 四、实验方法与步骤
##### (一) 创建Hadoop用户
- **步骤**:
1. 在Ubuntu系统中创建一个名为`hadoop`的新用户。
2. 设置用户密码。
3. 赋予`hadoop`用户管理员权限。
4. 注销当前用户,使用新创建的`hadoop`用户登录。
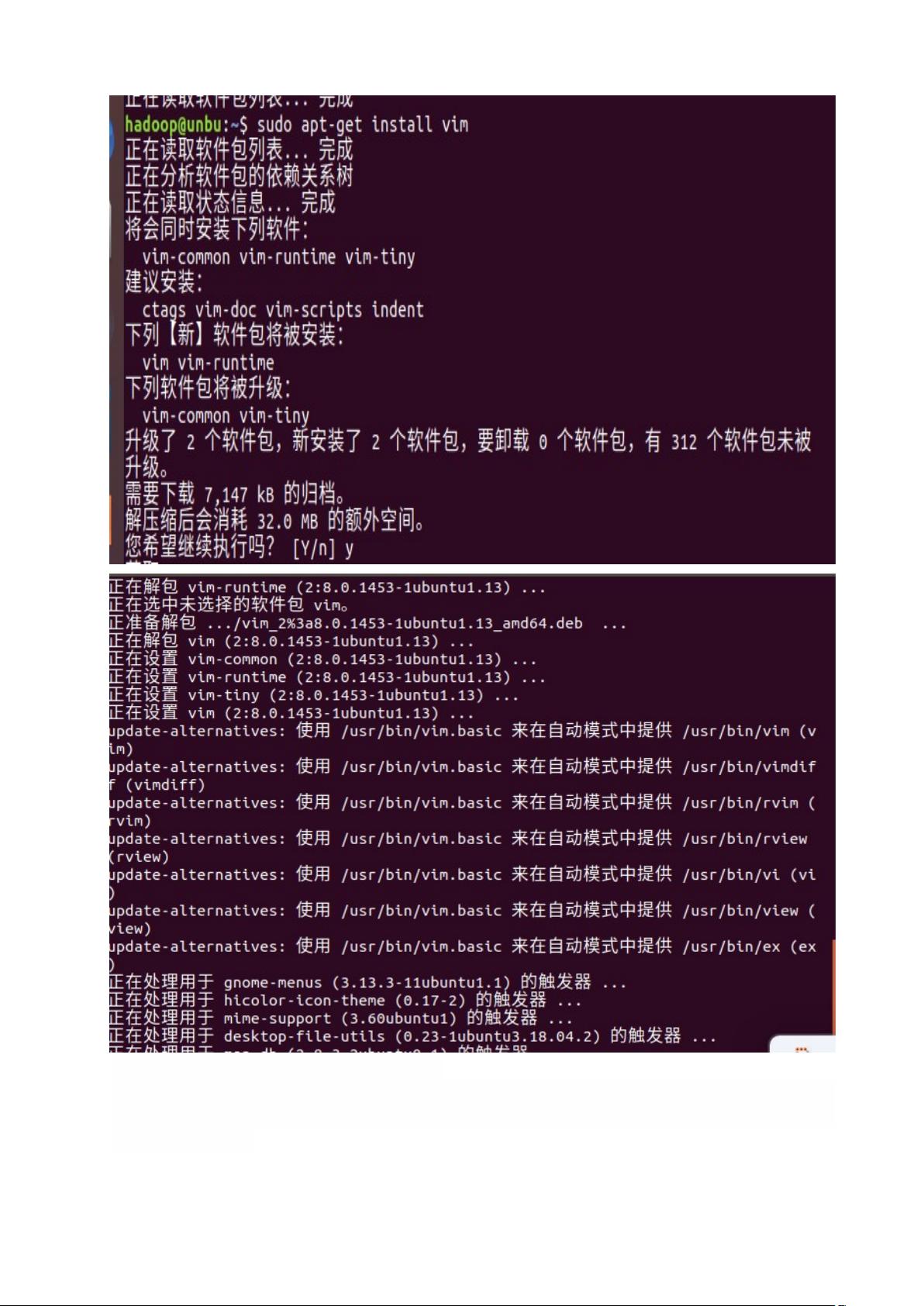
##### (二) 更新APT
- **步骤**:
1. 使用`hadoop`用户登录。
2. 更新APT以确保后续安装的软件版本最新。
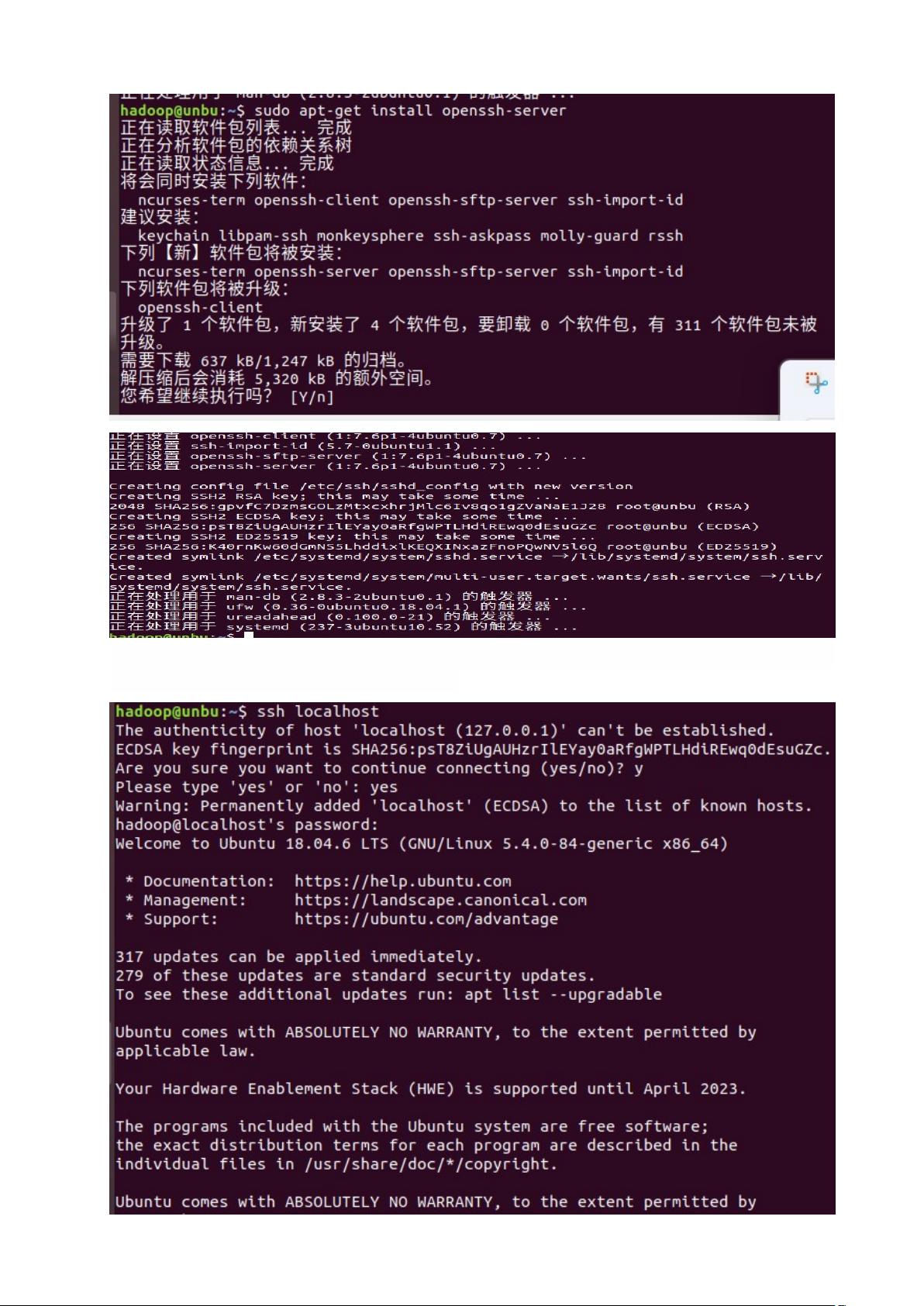
##### (三) 安装SSH、配置SSH无密码登录
- **步骤**:
1. 安装SSH服务器。
2. 配置SSH无密码登录:
- 通过`ssh-keygen`生成密钥。
- 将公钥添加到授权文件中。
- 测试SSH无密码登录功能。
##### (四) 安装Java环境
- **步骤**:
1. 安装Java。
2. 配置JAVA_HOME环境变量。
3. 验证JAVA_HOME设置是否正确。
##### (五) 安装Hadoop 3.1.3
- **步骤**:
1. 将Hadoop安装到`/usr/local/`目录下。
2. 检查Hadoop是否可用。
##### (六) Hadoop单机配置(非分布式)
- **步骤**:
1. 运行示例程序,如grep示例。
2. 观察程序执行结果,验证Hadoop单机模式下的基本功能。
##### (七) Hadoop伪分布式配置
- **步骤**:
1. 修改配置文件`core-site.xml`和`hdfs-site.xml`。
2. 对`core-site.xml`进行配置:
- 设置Hadoop的FS默认文件系统为HDFS。
- 设置HDFS的地址。
3. 对`hdfs-site.xml`进行配置:
- 设置DataNode的存储位置。
- 设置NameNode的存储位置。
4. 格式化NameNode。
5. 启动Hadoop服务。
#### 五、总结
通过上述步骤,我们不仅完成了Hadoop 3.1.3的安装和配置,还深入理解了Hadoop在单机模式和伪分布式模式下的工作原理。这种实践不仅有助于加深对Hadoop技术栈的理解,还能提高解决实际问题的能力。对于初学者来说,这是一个很好的学习起点,为后续更复杂的分布式环境部署打下了坚实的基础。
实验项目名称: Hadoop3.1.3安装和单机/伪分布式配置
一、 实验目的和要求
Hadoop3.1.3安装和单机/伪分布式配置
二、 实验原理
1.Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分
布式即单 Java 进程,方便进行调试。
2. Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程
来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文
件。
三、 主要仪器设备、试剂或材料
使用 Ubuntu 18.04 64 位 作为系统环境。
装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做一些必备工作。
四、 实验方法与步骤
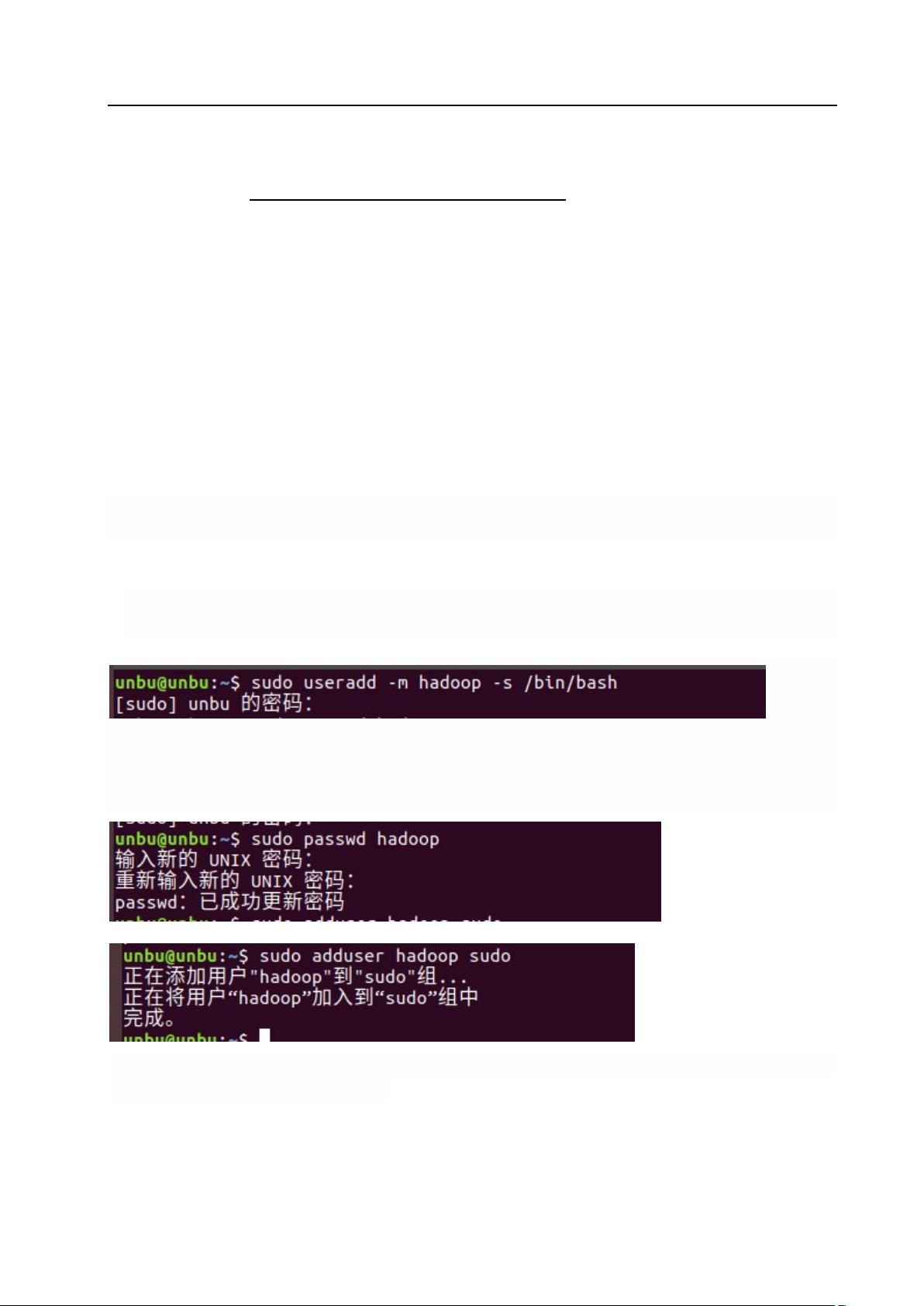
(一)创建hadoop用户
1.安装 Ubuntu 的时候不是用的 "hadoop" 用户,需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
2.使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
并为 hadoop 用户增加管理员权限,方便部署
3.注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选
择刚创建的 hadoop 用户进行登陆

剩余15页未读,继续阅读
查看更多
2016-04-12 上传
2022-07-28 上传
2014-11-14 上传
2019-11-06 上传
103 浏览量
2022-11-05 上传
2022-05-19 上传
2022-05-20 上传
107 浏览量
187 浏览量
102 浏览量
2016-04-12 上传
2022-08-08 上传
187 浏览量
197 浏览量
184 浏览量
资源评论

- #完美解决问题
- #运行顺畅
- #内容详尽
- #全网独家
- #注释完整

mmmmmmiii
- 粉丝: 60
- 资源: 1









最新资源
- 小程序开发基础教程:从零开始搭建项目
- SpringCloud微服务架构实战基础教程
- Hadoop与Spark大数据处理基础教程
- 考研冲刺阶段计算机编程高效复习基础教程
- Python数据分析与可视化基础教程
- 数据集的构建与应用基础教程
- 数据库开发实战:从零搭建图书管理系统基础教程
- (源码)基于Jekyll框架的个人博客系统.zip
- (源码)基于Node.js的离线包生成工具.zip
- (源码)基于 React 和 Express 的日式点心购物网站后台管理系统.zip
- (源码)基于STM32和FreeRTOS的LED灯闪烁控制系统.zip
- (源码)基于物联网的自动化窗帘系统.zip
- (源码)基于MicroPython的STM32H743开发板支持项目.zip
- (源码)基于Arduino和蓝牙控制的Mecanum轮车辆平台Autotant.zip
- (源码)基于HTML和JavaScript的Web样式获取工具.zip
- (源码)基于微信小程序开发框架的社区管理平台.zip






















