实验背景
HDFS 是大数据其他组件的基础,Hive 的数据存储在 HDFS 中,Mapreduce、Spark 等计算数据也存储在 HDFS 中,HBase 的 region 也是存储在 HDFS 中。在 HDFS shell 客户端我们可以实现多种操作,如上传、下载、删除数据,文件系统管理等。掌握 HDFS 的使用对我们更好的理解和掌握大数据大有裨益
实验目的
掌握 HDFS 常用操作。
掌握 HDFS 文件系统管理操作。
【HDFS 分布式文件系统】是大数据处理的基础,它为Hive、MapReduce、Spark等组件提供了数据存储服务。HDFS(Hadoop Distributed File System)设计为在大规模集群环境中运行,具有高容错性和高吞吐量,使得大数据处理变得高效且可靠。
在HDFS的shell客户端中,我们可以进行一系列操作,包括但不限于:
1. **文件操作**:
- **上传文件**:使用`hdfs dfs -put`命令,例如`hdfs dfs -put bigdata.txt /user/text01`,将本地的`bigdata.txt`文件上传到HDFS的`/user/text01`目录。
- **下载文件**:通过`hdfs dfs -copyToLocal`命令,例如`hdfs dfs -copyToLocal /user/text01/bigdata4.txt`,将HDFS的`bigdata4.txt`文件下载到本地。
- **追加文件内容**:使用`hdfs dfs -appendToFile`命令,如`hdfs dfs -appendToFile bigdata3.txt /user/text01/bigdata.txt`,将`bigdata3.txt`内容追加到`bigdata.txt`末尾。
- **合并文件**:通过`hdfs dfs -getmerge`命令,可以将多个文件合并为一个文件,如`hdfs dfs -getmerge /user/text01/* ./merge.txt`。
2. **目录管理**:
- **创建目录**:使用`hdfs dfs -mkdir`命令,例如`hdfs dfs -mkdir /user/text01`,创建名为`text01`的目录。
- **删除文件或目录**:`hdfs dfs -rm`用于删除文件,如`hdfs dfs -rm /user/text01/bigdata5.txt`;若需删除目录,需连同其内容一起删除,可以使用`-r`选项。
- **移动和复制文件**:`hdfs dfs -mv`命令用于在HDFS内部移动文件,而`hdfs dfs -cp`则用于复制文件,支持重命名操作。
3. **文件系统信息查询**:
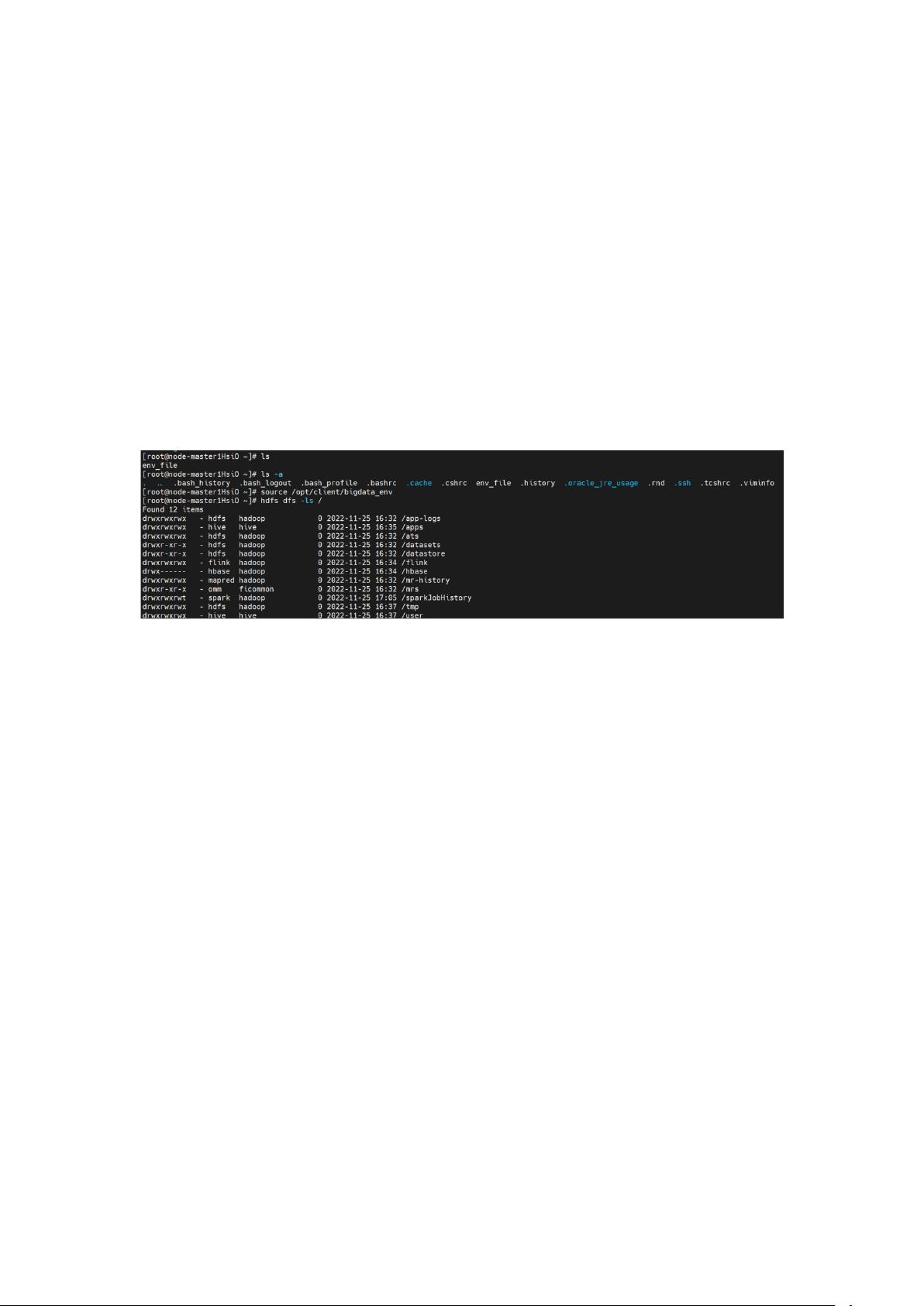
- **查看文件列表**:使用`hdfs dfs -ls`命令,如`hdfs dfs -ls /`,列出指定目录下的文件和子目录。
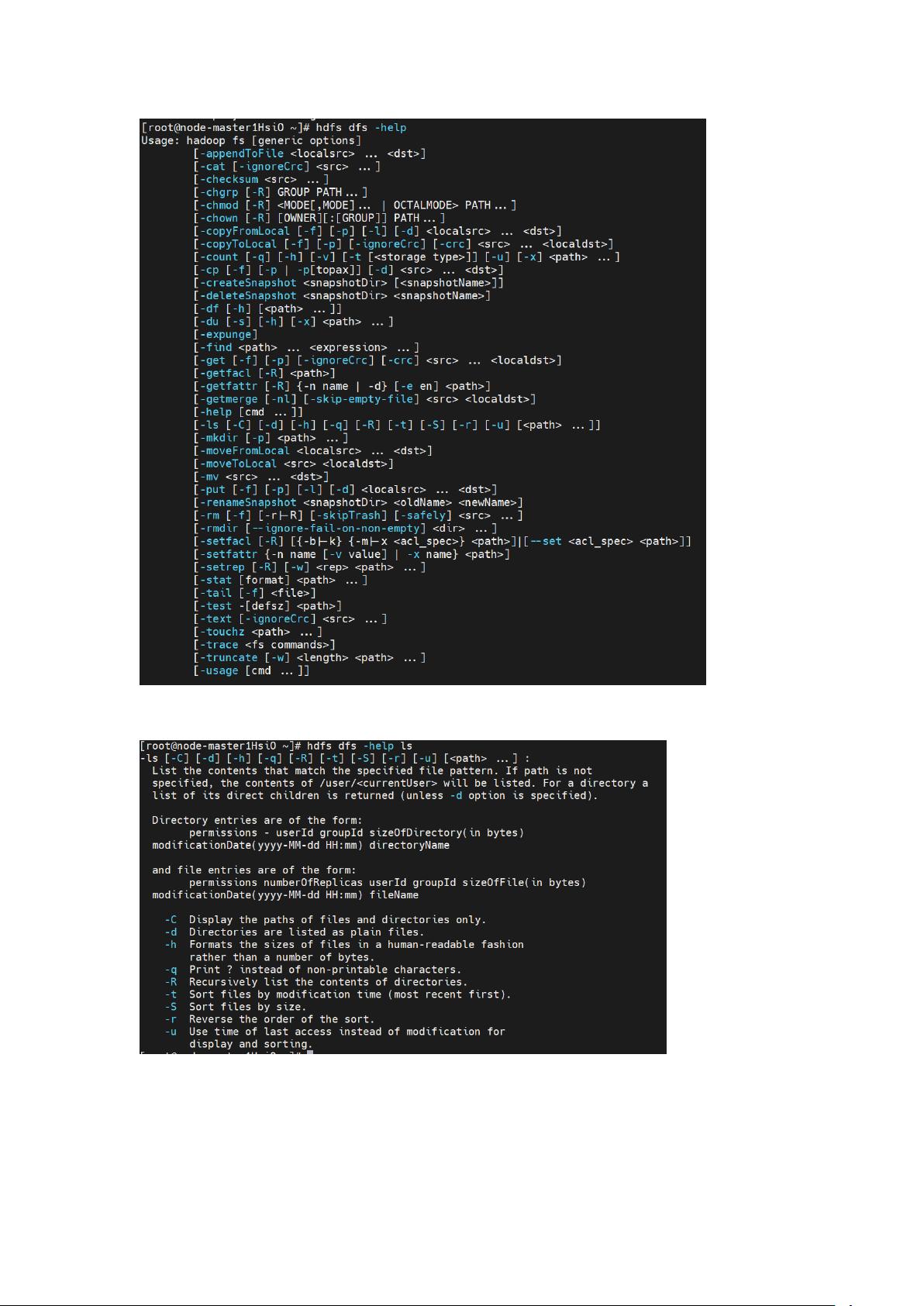
- **查看帮助文档**:通过`hdfs dfs -help`获取命令帮助,如`hdfs dfs -help ls`查看`ls`命令的用法。
- **文件大小统计**:`hdfs dfs -du`命令用于计算文件或目录的大小,`-s`选项用于显示总计,`-h`使输出以人类可读的格式显示。
- **可用空间查询**:`hdfs dfs -df`命令提供文件系统的总空间、已用空间和可用空间信息。
- **文件节点计数**:`hdfs dfs -count`命令统计指定目录下的文件和子目录的数量。
掌握这些基本操作对于理解和应用HDFS至关重要,它们构成了大数据分析与处理流程的基础。了解和熟练运用HDFS的shell客户端,可以有效地管理和操作存储在HDFS中的大数据,从而提升整个大数据处理系统的效率和可靠性。