

大数据课程复习题
1. 大数据的定义
大数据,指的是所涉及的资料量规模巨大到无法通过目前的主流软件工具,在合理
时间内达到撷(xie2)取、管理、处理、并整理成为帮助企业经营决策更积极目的的资
讯。
2. 大数据的三个特点
3Vs:
-Volume(大量)数据量大,从 TB 级别跃升到 PB 级别
-Variety(多样)数据类型繁多
·非结构化:文本、图形、声音等
·半结构化:日志
·结构化数据:行列规整的表单数据
·多结构化数据:以上三种类型混合的数据
-Velocity(高速)数据的时效性,数据仅在一个短暂的时间范围有价值。
3. Hadoop 项目起始于 2002 年,创始人是 Doug Cutting
4. Hadoop 的两个核心组成部分
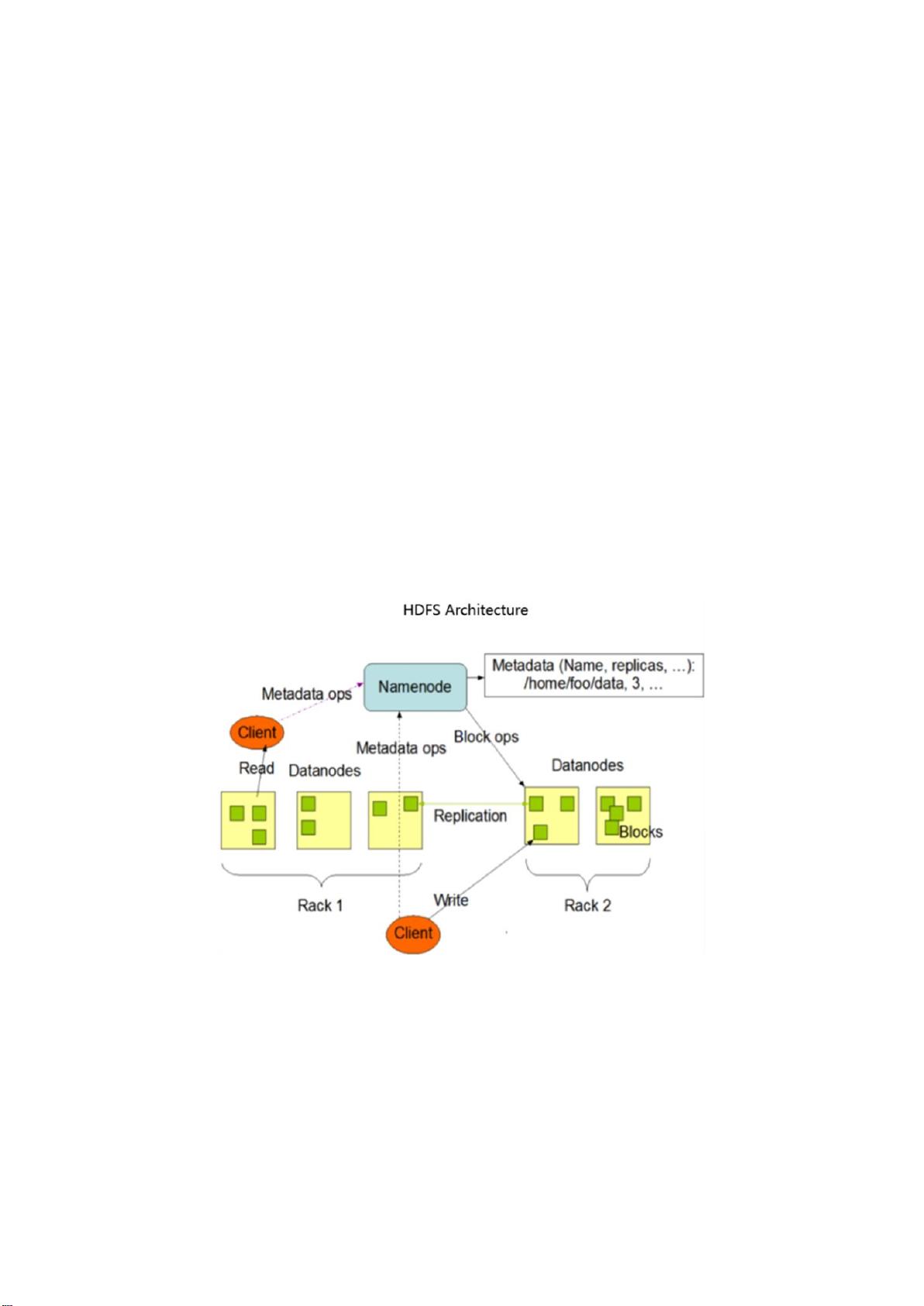
-分布式文件系统——HDFS(Nutch Distributed File System)
·数据被分割成小块存于上千的节点上
-分布式数据处理架构——MapReduce
·MapReduce 在数据节点上处理,降低 I/O 成本
·MapReduce 只是一个软件架构,充分灵活,是开发者易于实现多种多样的应用程序。
5. Hadoop 的优点
-高可靠性
·Hadoop 按位存储和处理数据的能力值得人们信赖。
-高扩展性
·Hadoop 是在可用的计算机集簇间分配数据并完成计算业务的,这些集簇可以方便地
扩展到数以千计的节点中。
-高效性
·Hadoop 能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速
度非常快。
-高容错性
Hadoop 能够自动的保存数据的多个副本,并且能够自动将失败的任务重新分配。
-低成本
·与一体机、商用数据仓库等相比,Hadoop 是开源的,项目的软件成本因此会大大降
低。
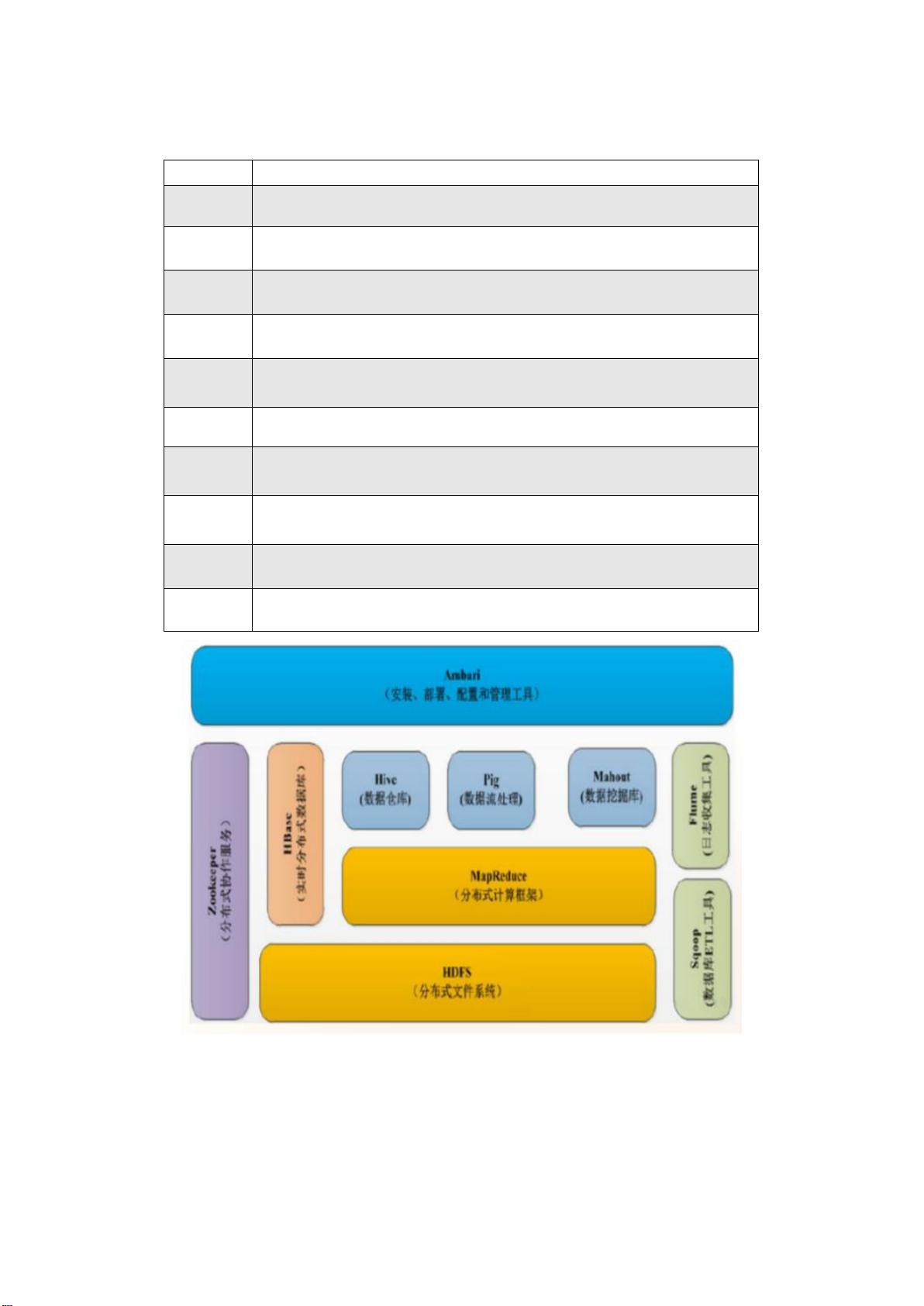
6. Hadoop 生态系统构成

剩余16页未读,继续阅读
资源评论


ywmzxysjdsjlcf
- 粉丝: 262
- 资源: 28









最新资源
- A4 彩机常见问题.pdf
- A3 机器常见问题.pdf
- 非表单形式文件上传和下载
- 500kW储能变流器(PCS) 采用T型三电平模块,结构三维、控制电路、驱动电路,全部的BOM,型式试验报告等全部资料 没有程序源码,本交付的资料与本描述一致,未提及的可能没有
- 免费拆解:快手无人直播,新手小白如何0基础上手,详细教程.mp4
- 大数据实验6数据和python源代码.7z
- 千川投流实操指南:付费基本功千川应用投放篇进阶篇素材创作问题诊断.mp4
- 千川投流实战课:0-1打品思路,涵盖思维打法、数据分析与人群包实操教学.mp4
- ctf攻防挑战赛基础工具包,基础必备,种类齐全
- 变频器资料:英威腾CHE100-2406变频器资料,应用文档 非常适合学习 资料属于文档
- 轻松制作创业类视频。一天被动加精准创业粉500+(附素材).mp4
- 基于自适应代理辅助的多目标进化算法框架(ASA-MOEA/D)求解昂贵约束优化问题
- 大数据(选修)期末复习资料.7z
- 非线性结构分析中的弧长法:原理、实现与应用
- 十年 一遇 市场机遇,明确指引方向,转换思维,坚定执行,方能不被时代....mp4
- 视频号【灵狐赛道2.0】一条视频三种收益 100%原创 小白三天收益破百.mp4
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


