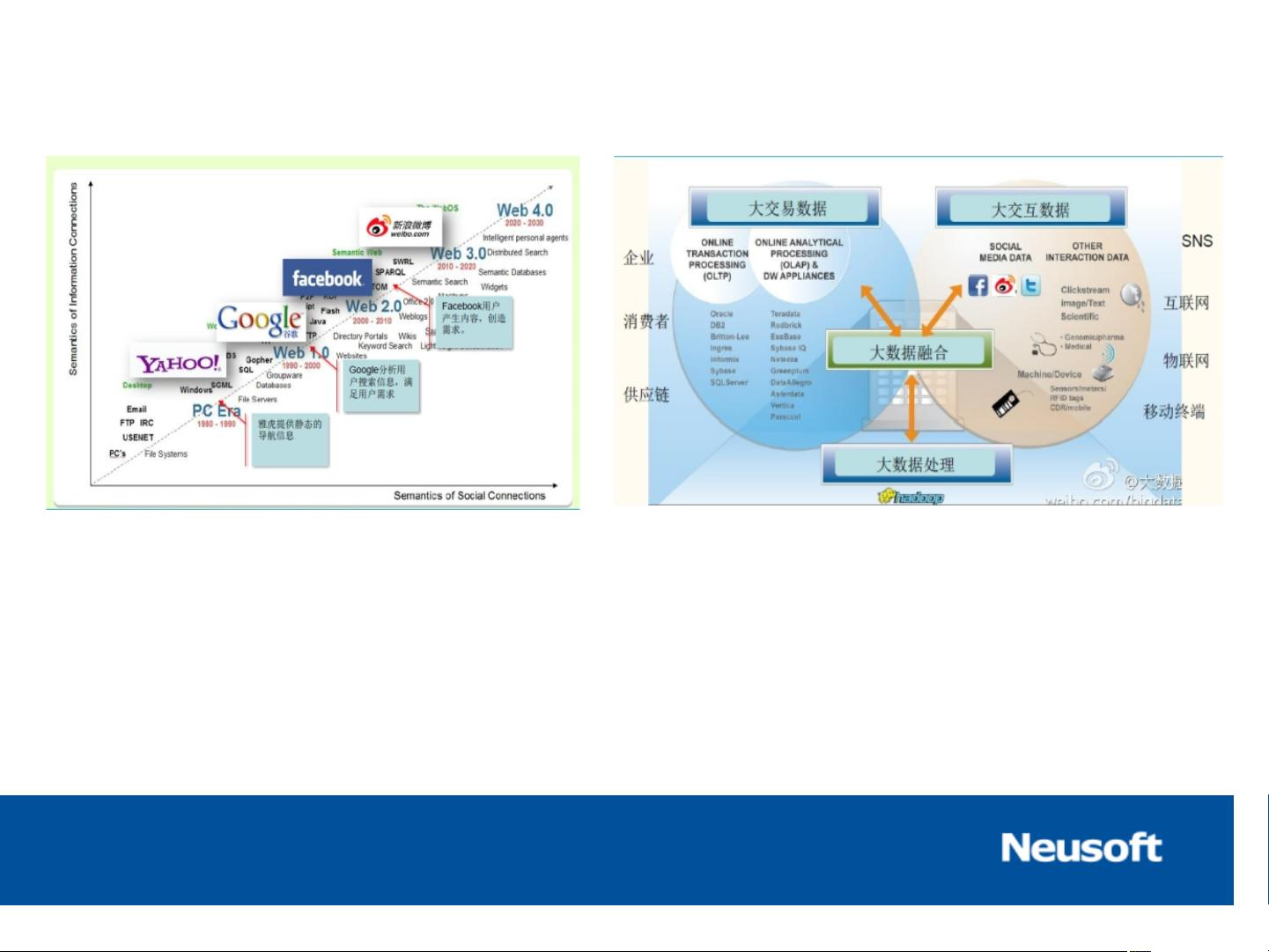
基于Hadoop的大数据应用分析 大数据背景介绍: 大数据定义为:为了更经济地从高频率获取的、大容量的、不同结构和类型的数据中获取价值,而设计的新一代架构和技术。 IDC定义大数据为:高性能、高并发读写、huge storage、高scalability和高可用性。 Hadoop体系架构: Hadoop是一个用Java语言实现的软件框架,在由大量计算机组成的集群中运行海量数据的分布式计算。Hadoop是项目的总称,主要由分布式存储(HDFS)和分布式计算(MapReduce)组成。 基于Hadoop的大数据产品分析: Hadoop的优点包括可扩展、经济、可靠、高效等。Hadoop的设计目的是为了处理海量数据,提供高性能、高并发读写、高scalability和高可用性。 大数据和云计算的关系: 大数据和云计算是紧密相连的。云计算是大数据的IT基础,大数据需要云计算作为基础架构,才能高效运行。 大数据云计算: 大数据云计算是指使用云计算技术来处理和分析大数据。云计算提供了高度可扩展的IT基础设施,能够支持大数据的存储、处理和分析。 大数据市场分析: 根据IDC的预测,全球大数据市场2015年将达170亿美元规模,市场发展前景很大。中国大数据市场也在快速增长,2012年达到4.7亿元,2013年大数据市场将迎来增速为138.3%的飞跃,到2016年,整个市场规模逼近百亿。 大数据主要应用技术——Hadoop: Hadoop是新一代的架构和技术,因为有利于并行分布处理“大数据”而备受重视。Hadoop可以让应用程序支持上千个节点和PB级别的数据。 Hadoop核心组件: Hadoop核心组件包括HDFS、MapReduce、Pig、Hive、ZooKeeper、HBase等。 HDFS(分布式文件系统): HDFS是Hadoop的核心组件之一,提供了高容错性和高吞吐量的数据访问。HDFS由NameNode、DataNode和Client组成。NameNode负责管理文件系统的命名空间,集群配置信息,存储块的复制。DataNode是文件存储的基本单元,存储文件块在本地文件系统中。Client是需要获取分布式文件系统文件的应用程序。 MapReduce(分布式计算): MapReduce是Hadoop的核心组件之一,提供了高性能的分布式计算能力。MapReduce由Map和Reduce两个阶段组成。Map阶段将任务分解成小任务,而Reduce阶段将结果汇总。 基于Hadoop的大数据应用分析: 基于Hadoop的大数据应用分析包括大数据背景介绍、Hadoop体系架构、大数据产品分析、大数据和云计算的关系等。 大数据应用建议: 大数据应用建议包括大数据背景介绍、Hadoop体系架构、大数据产品分析、大数据和云计算的关系等。 大数据和Hadoop是紧密相连的。大数据需要Hadoop作为基础架构,才能高效运行。Hadoop提供了高性能、高并发读写、高scalability和高可用性的IT基础设施,能够支持大数据的存储、处理和分析。
剩余45页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~