

河北师范大学软件学院
网络爬虫
1. 实验目标
1. 熟悉网络爬虫的相关概念及实现网络爬虫的相关流程。
2. 了解 WebCollector 框架的基本原理。
3. 熟练掌握在 Eclipse 项目中配置使用 WebCollector 爬虫。
2. 前提条件
1. 正确安装和配置 Java 开发环境。
2. 了解网络爬虫的相关知识
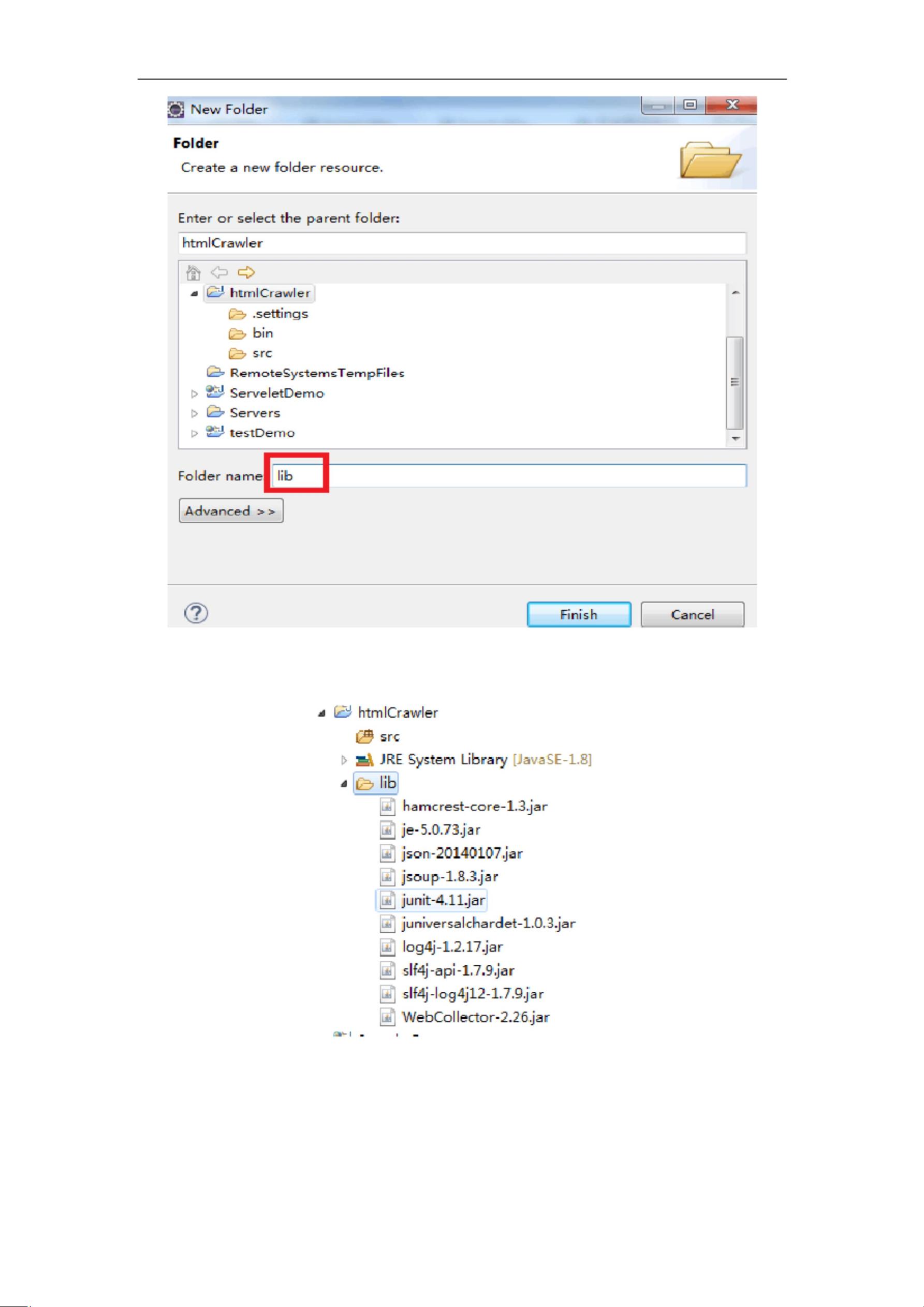
3. 进入 WebCollector 官方网站下载所需 jar 包。
3. 实验任务及完成标准
本次实验通过 WebCollector 框架实现一个简单的聚焦网络爬虫。用户可根据自己的需求
定制网络爬虫,设定待爬取的网址、爬取网页的数量、爬取网页的内容等。通过对该实例的
详细介绍来探讨网络爬虫的原理及在实际生活中的应用。
在此实例的基础上,学生需要独立完成更为复杂的聚焦网络爬虫,来爬取更有意义的内
容。具体要求见“4 扩展内容”。
3.1 建立应用程序项目
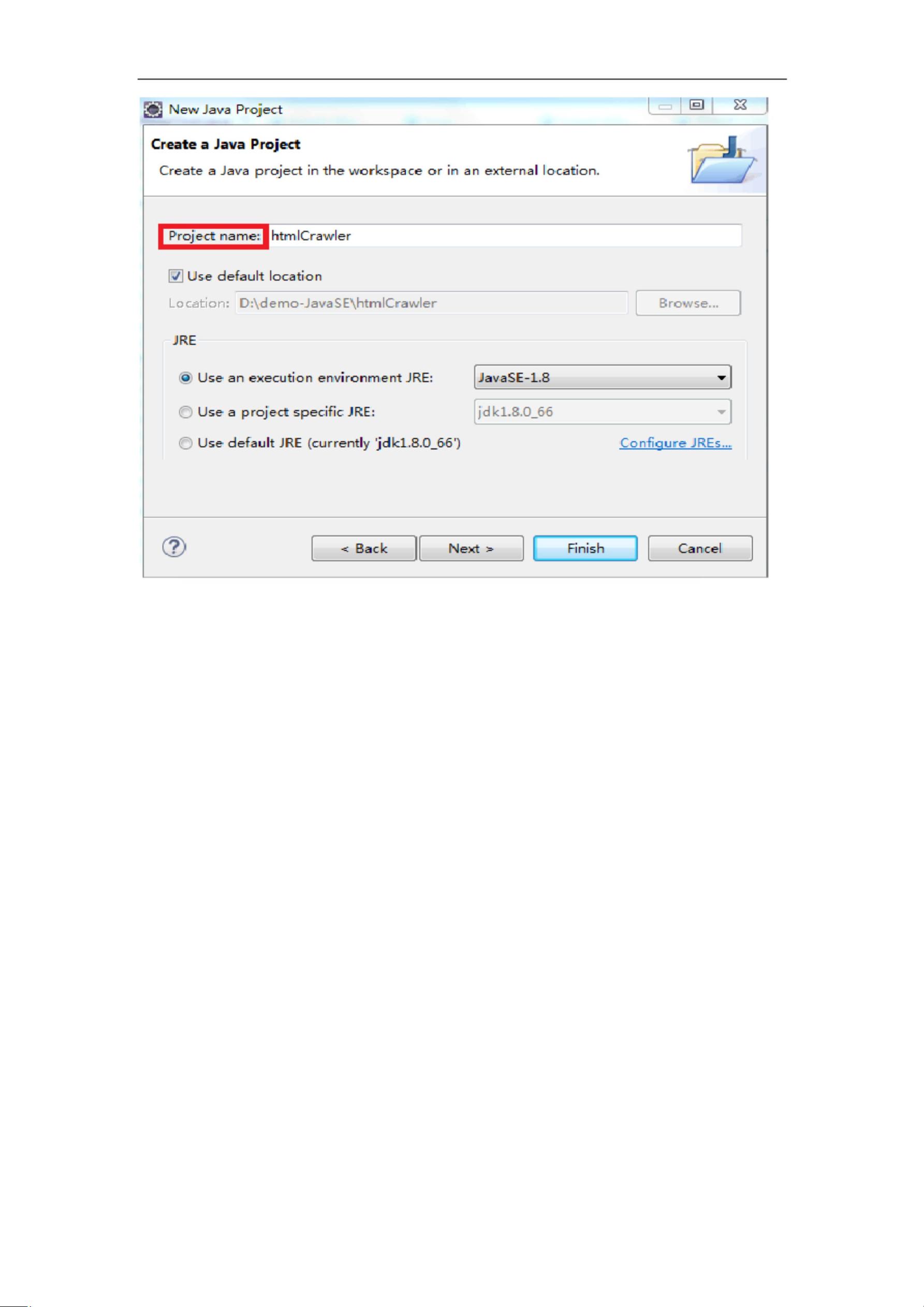
打开 eclipse,创建本次实验项目 htmlCrawler〔【File】->【New】->【Java Project】
〕如图 1 所示。
1
剩余11页未读,继续阅读
资源评论













