2018-02-14 新闻内容爬虫【上学时做论文自己爬新闻数据,原谅我自己懒发的图片】
需积分: 5 196 浏览量
2024-02-26
09:41:19
上传
评论
收藏 750KB PDF 举报

2018-02-14 新闻内容爬虫
爬虫过的站点:
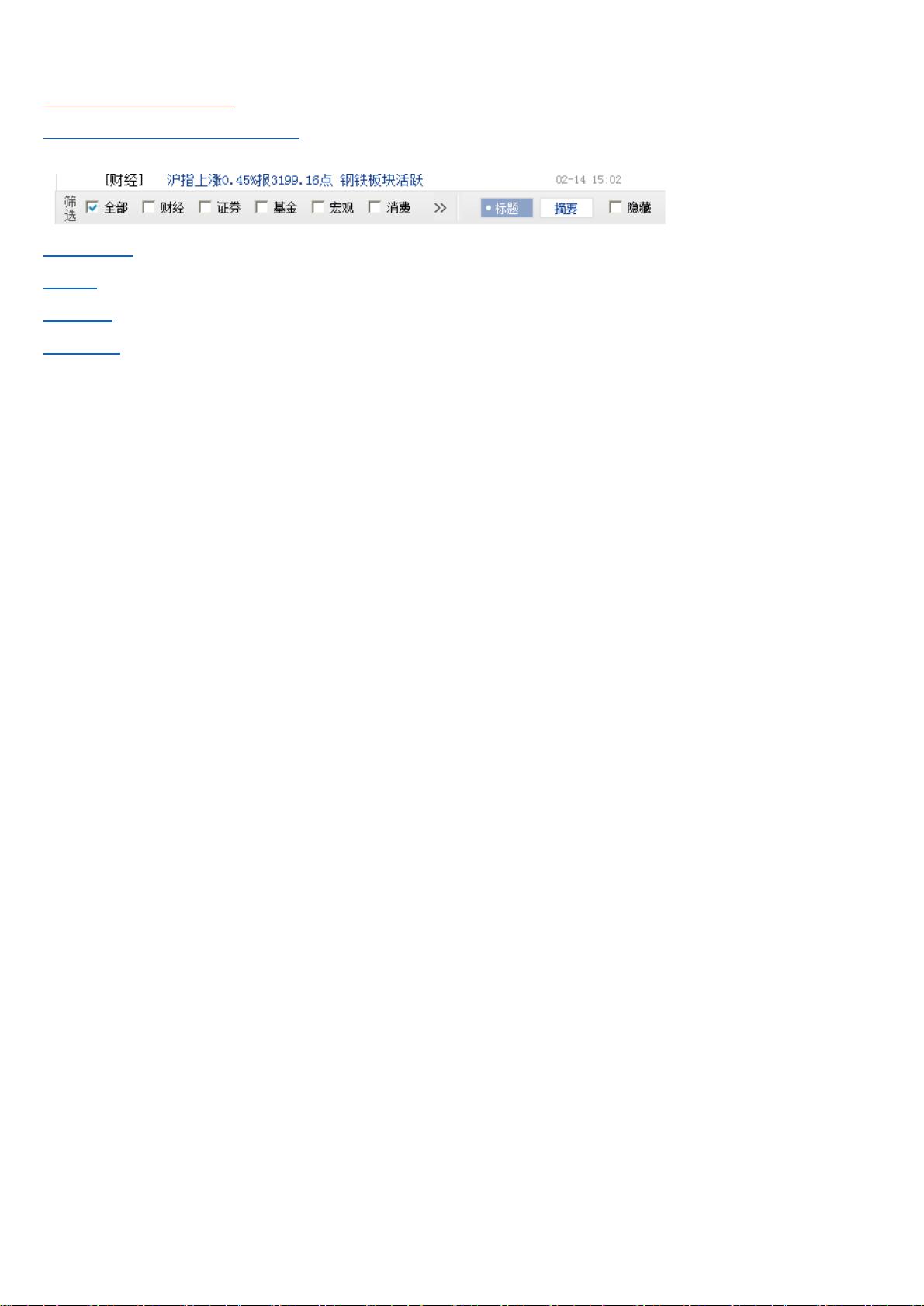
1QQ新闻
1,准备爬取滚动新闻页面
2 通过F12 开发工具查找发现,动态获取数据url
3 获取数据格式,
注意:请求页面时,必须加头部信息
4 页面内容解析
5 评论获取
评论页面
评论数据
6 注意
2 新浪
1 准备爬取滚动页面
2 滚动页面类别,只是部分,往后和的url 基本都不更新了
3 动态获取滚动页面数据
4 获取的动态页面新闻条目
5 获取评论内容
3 网易新闻
1 滚动新闻
2 页面内容爬取,
3 获取评论内容

剩余19页未读,继续阅读
资源评论













