Mining the Web 2
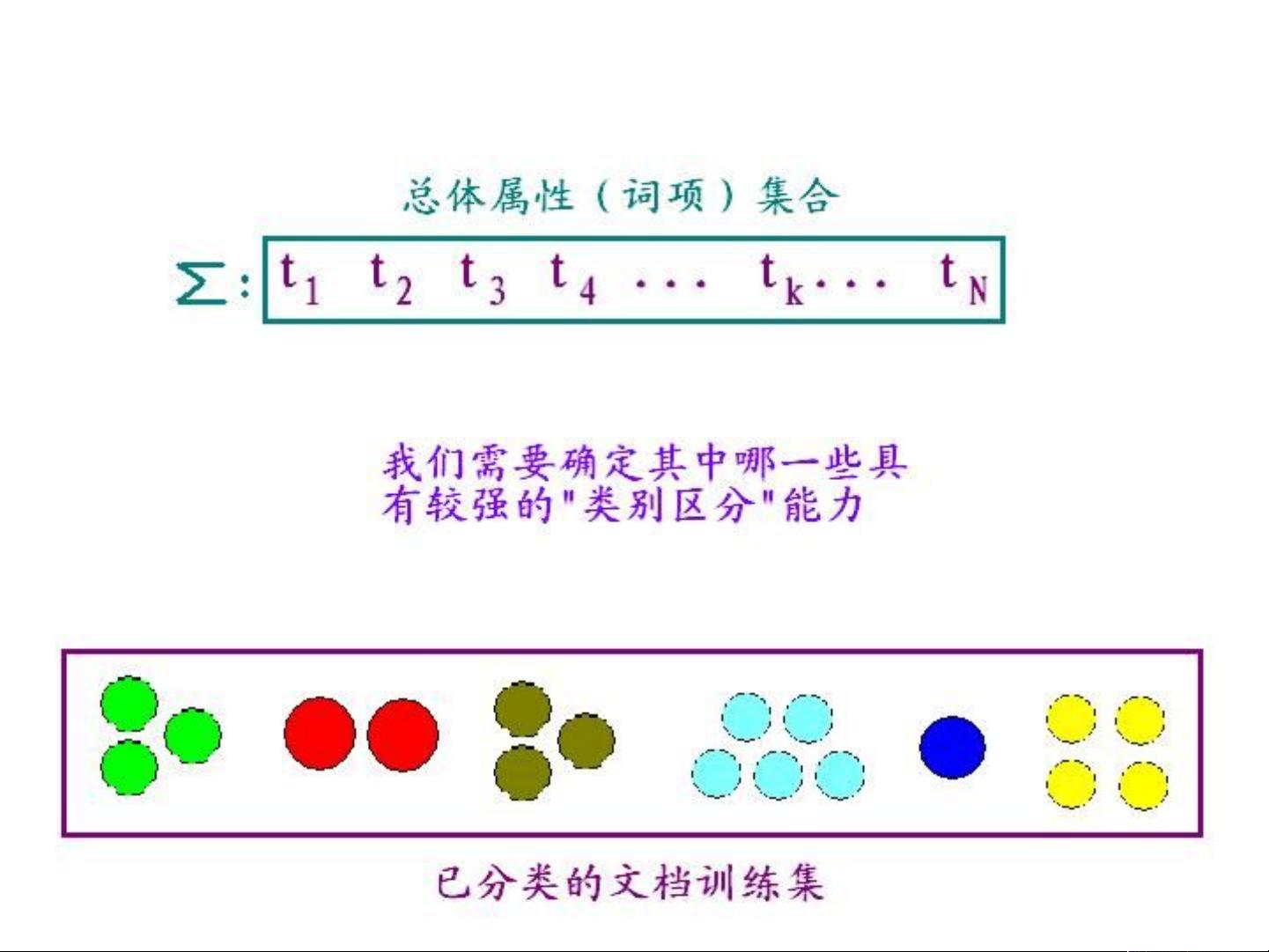
特征选取
Feature selection, dimension reduction
《 Mining the Web 》 , section 5.5
《 Modeling the Internet and the
Web 》, section 4.6.4
“Machine Learning in Automated Text
Categorization”, sections 5.3, 5.4, 5.5
“A Comparative Study on Feature
Selection in Text Categorization” by
Yiming Yang and Jan Pedersen