### Hadoop介绍与核心组件详解
#### Hadoop概述
Hadoop是一种开源软件框架,主要用于分布式存储和处理大规模数据集。其设计目标是为了处理PB级别的数据,并且能够在数千台商用服务器组成的集群上运行。Hadoop的核心优势在于其强大的容错能力和高可扩展性,能够有效地管理大数据。
#### Hadoop的构成组件
Hadoop主要由以下几个关键组件构成:
1. **HDFS(Hadoop Distributed File System)**: 这是Hadoop的分布式文件系统,它将文件分割成多个块(block),每个块默认大小为64MB或128MB,并将这些块分布存储在集群中的不同节点上。为了确保数据的安全性和可靠性,Hadoop默认会在三个不同的节点上存储每个数据块的副本,这一设置可以通过配置文件进行调整。当某个节点发生故障时,HDFS能够自动检测并恢复数据块到其他节点,保证数据的完整性和可用性。
2. **Namenode与Datanode**:
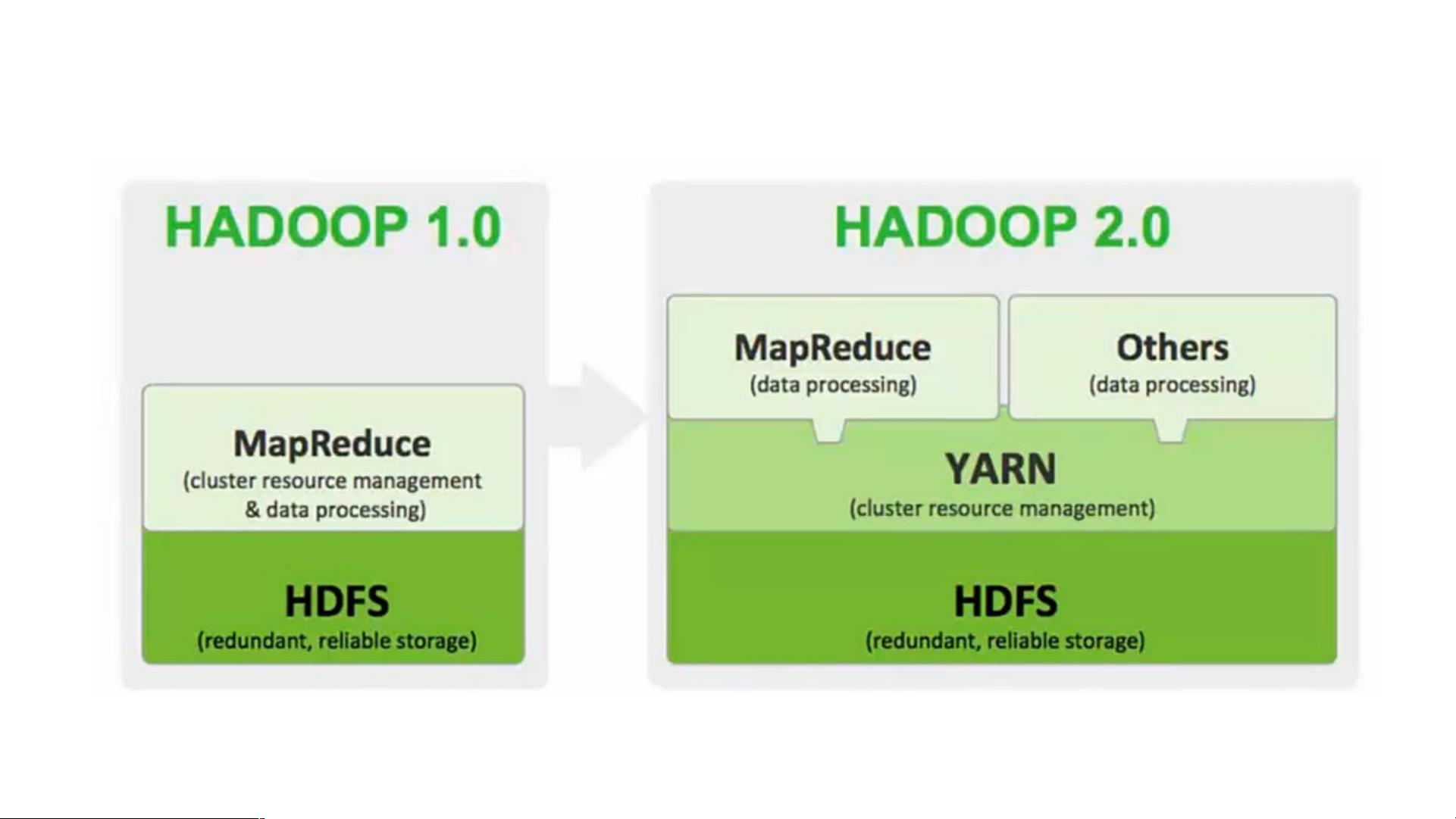
- **Namenode**: 这是HDFS的主节点,负责管理文件系统的命名空间和客户端对文件的访问。在早期版本中,Namenode采用单节点设计,存在单点故障的风险。为了解决这个问题,在Hadoop 2.0中引入了Active-Standby模式,即两个Namenode实例,其中一个处于活动状态处理请求,另一个作为备用节点待命。一旦活动节点出现问题,备用节点可以自动接管服务。
- **Datanode**: 这些是工作节点,负责存储实际的数据块。Datanode会根据Namenode的指令执行数据块的创建、删除等操作。为了提高数据读取效率,Hadoop采用了数据局部性的策略,优先选择离计算任务最近的数据副本进行处理。
3. **MapReduce**: 这是一种编程模型,用于处理和生成大规模数据集。MapReduce框架将数据处理任务分解为Map(映射)和Reduce(归约)两个阶段,能够有效地并行处理大规模数据。MapReduce通过利用Hadoop集群中的多台计算机共同完成计算任务,大大提高了数据处理的速度和效率。
#### Hadoop的特点
- **高容错性**: Hadoop通过在集群中复制数据块来确保数据的可靠性和持久性。即使部分节点出现故障,也不会影响整个系统的稳定运行。
- **高可扩展性**: Hadoop可以在不同规模的集群上部署,轻松地从几台服务器扩展到数千台服务器,只需简单地添加更多的机器即可。
- **成本效益**: Hadoop可以在廉价的商品硬件上运行,显著降低了构建大型数据处理平台的成本。
- **灵活性**: Hadoop不仅可以处理结构化数据,还可以处理半结构化和非结构化数据,为用户提供更广泛的应用场景。
#### Hadoop的不同发行版
市场上存在多种Hadoop的发行版本,包括Apache Hadoop、Cloudera CDH以及Hortonworks HDP等。这些发行版虽然基于相同的Apache Hadoop核心,但在附加功能和服务方面有所不同:
- **Apache Hadoop**: 这是最原始的Hadoop版本,由Apache Software Foundation维护和支持,具有较高的灵活性和自定义能力。
- **Cloudera CDH**: Cloudera提供了一个免费版和一个企业版,后者包含了更多的管理工具和服务支持。企业版仅提供试用期,适合需要高级技术支持的企业级应用。
- **Hortonworks HDP**: Hortonworks的产品都是完全开源的,这意味着用户可以自由地使用和修改其代码。这使得Hortonworks成为了那些希望在开源环境中构建自己的解决方案的开发者的首选。
#### Apache Ambari
Apache Ambari是一个基于Web的工具,用于简化Hadoop集群的安装、配置和管理过程。Ambari支持Hadoop HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop等多种Hadoop生态系统中的组件。此外,Ambari还提供了一系列的监控和诊断工具,帮助用户更好地理解和优化集群的性能。通过Ambari提供的集群状态仪表盘,管理员可以轻松地查看集群的整体健康状况、资源使用情况以及各种应用程序的状态。
Hadoop不仅是一个强大的大数据处理平台,而且随着技术的发展和生态系统的不断完善,它已经成为现代数据分析和处理不可或缺的一部分。无论是初学者还是经验丰富的专业人士,掌握Hadoop的基本原理和核心组件都是非常重要的。