
MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning
Zechun Liu
1
Haoyuan Mu
2
Xiangyu Zhang
3
Zichao Guo
3
Xin Yang
4
Tim Kwang-Ting Cheng
1
Jian Sun
3
1
Hong Kong University of Science and Technology
2
Tsinghua University
3
Megvii Technology
4
Huazhong University of Science and Technology
Abstract
In this paper, we propose a novel meta learning ap-
proach for automatic channel pruning of very deep neural
networks. We first train a PruningNet, a kind of meta net-
work, which is able to generate weight parameters for any
pruned structure given the target network. We use a sim-
ple stochastic structure sampling method for training the
PruningNet. Then, we apply an evolutionary procedure to
search for good-performing pruned networks. The search is
highly efficient because the weights are directly generated
by the trained PruningNet and we do not need any fine-
tuning at search time. With a single PruningNet trained
for the target network, we can search for various Pruned
Networks under different constraints with little human par-
ticipation. Compared to the state-of-the-art pruning meth-
ods, we have demonstrated superior performances on Mo-
bileNet V1/V2 and ResNet. Codes are available on https:
//github.com/liuzechun/MetaPruning.
1. Introduction
Channel pruning has been recognized as an effective
neural network compression/acceleration method [32, 22, 2,
3, 21, 52] and is widely used in the industry. A typical prun-
ing approach contains three stages: training a large over-
parameterized network, pruning the less-important weights
or channels, finetuning or re-training the pruned network.
The second stage is the key. It usually performs iterative
layer-wise pruning and fast finetuning or weight reconstruc-
tion to retain the accuracy [17, 1, 33, 41].
Conventional channel pruning methods mainly rely
on data-driven sparsity constraints [28, 35], or human-
designed policies [22, 32, 40, 25, 38, 2]. Recent AutoML-
style works automatically prune channels in an iterative
mode, based on a feedback loop [52] or reinforcement
learning [21]. Compared with the conventional pruning
This work is done when Zechun Liu and Haoyuan Mu are interns at
Megvii Technology.
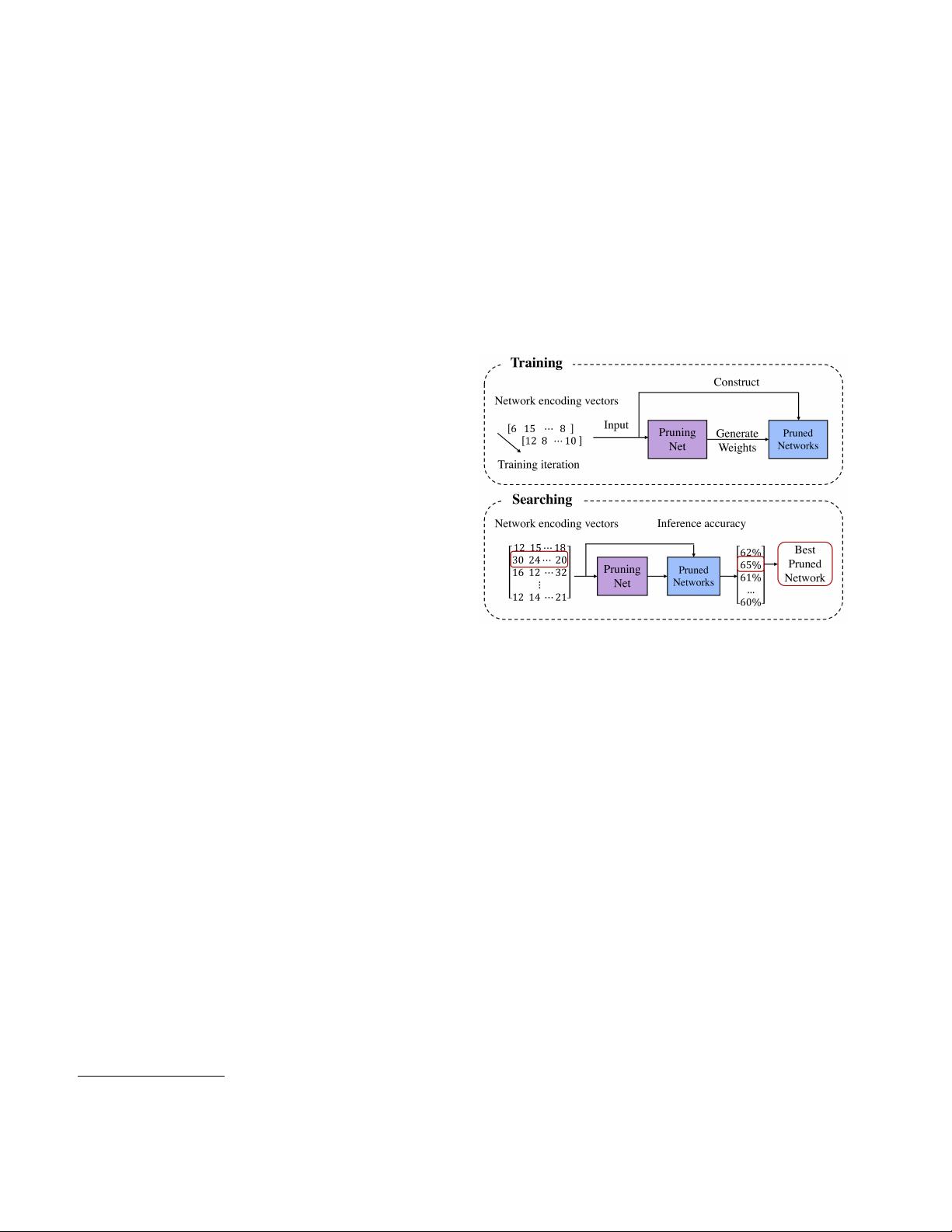
Figure 1. Our MetaPruning has two steps. 1) training a Prun-
ingNet. At each iteration, a network encoding vector (i.e., the
number of channels in each layer) is randomly generated. The
Pruned Network is constructed accordingly. The PruningNet takes
the network encoding vector as input and generates the weights
for the Pruned Network. 2) searching for the best Pruned Net-
work. We construct many Pruned Networks by varying network
encoding vector and evaluate their goodness on the validation data
with the weights predicted by the PruningNet. No finetuning or
re-training is needed at search time.
methods, the AutoML methods save human efforts and can
optimize the direct metrics like the hardware latency.
Apart from the idea of keeping the important weights in
the pruned network, a recent study [36] finds that the pruned
network can achieve the same accuracy no matter it inher-
its the weights in the original network or not. This finding
suggests that the essence of channel pruning is finding good
pruning structure - layer-wise channel numbers.
However, exhaustively finding the optimal pruning struc-
ture is computationally prohibitive. Considering a network
with 10 layers and each layer contains 32 channels. The
possible combination of layer-wise channel numbers could
be 32
10
. Inspired by the recent Neural Architecture Search
(NAS), specifically One-Shot model [5], as well as the
weight prediction mechanism in HyperNetwork [15], we
arXiv:1903.10258v3 [cs.CV] 14 Aug 2019

剩余9页未读,继续阅读
资源评论


librahfacebook
- 粉丝: 198
- 资源: 2









最新资源
- 基于SpringBoot+Vue的的医院药品管理系统设计与实现(Java毕业设计,附源码,部署教程).zip
- 基于SpringBoot+Vue的的游戏交易系统(Java毕业设计,附源码,部署教程).zip
- 基于SpringBoot+Vue的影院订票系统的设计与实现(Java毕业设计,附源码,部署教程).zip
- 基于SpringBoot+Vue的影院订票系统的设计与实现2(Java毕业设计,附源码,部署教程).zip
- 基于SpringBoot+Vue的的医院药品管理系统设计与实现2(Java毕业设计,附源码,部署教程).zip
- 基于HAL库STM32F407的大彩TFT彩屏串口通信程序 STM32F4xx.7z
- 基于java的健身房管理系统的设计与实现+vue(Java毕业设计,附源码,数据库,教程).zip
- 基于java和mysql的多角色学生管理系统+jsp(Java毕业设计,附源码,数据库,教程).zip
- 基于Java的图书管理系统+jsp(Java毕业设计,附源码,数据库,教程).zip
- 基于Java语言校园快递代取系统的设计与实现+jsp(Java毕业设计,附源码,数据库,教程).zip
- 基于SpringBoot+Vue的的信息技术知识竞赛系统的设计与实现2(Java毕业设计,附源码,部署教程).zip
- 基于SpringBoot+Vue的的信息技术知识赛系统的设计与实现2(Java毕业设计,附源码,部署教程).zip
- 基于SpringBoot+Vue的的信息技术知识赛系统的设计与实现(Java毕业设计,附源码,部署教程).zip
- 基于spring框架的中小企业人力资源管理系统的设计及实现+jsp(Java毕业设计,附源码,数据库,教程).zip
- 基于jsp的精品酒销售管理系统+jsp(Java毕业设计,附源码,数据库,教程).zip
- 基于SpringBoot+Vue的的小学生身体素质测评管理系统设计与实现(Java毕业设计,附源码,部署教程).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


