
Deep Neural Networks for YouTube Recommendations
Paul Covington, Jay Adams, Emre Sargin
Google
Mountain View, CA
{pcovington, jka, msargin}@google.com
ABSTRACT
YouTube represents one of the largest scale and most sophis-
ticated industrial recommendation systems in existence. In
this paper, we describe the system at a high level and fo-
cus on the dramatic performance improvements brought by
deep learning. The paper is split according to the classic
two-stage information retrieval dichotomy: first, we detail a
deep candidate generation model and then describe a sepa-
rate deep ranking model. We also provide practical lessons
and insights derived from designing, iterating and maintain-
ing a massive recommendation system with enormous user-
facing impact.
Keywords
recommender system; deep learning; scalability
1. INTRODUCTION
YouTube is the world’s largest platform for creating, shar-
ing and discovering video content. YouTube recommenda-
tions are responsible for helping more than a billion users
discover personalized content from an ever-growing corpus
of videos. In this paper we will focus on the immense im-
pact deep learning has recently had on the YouTube video
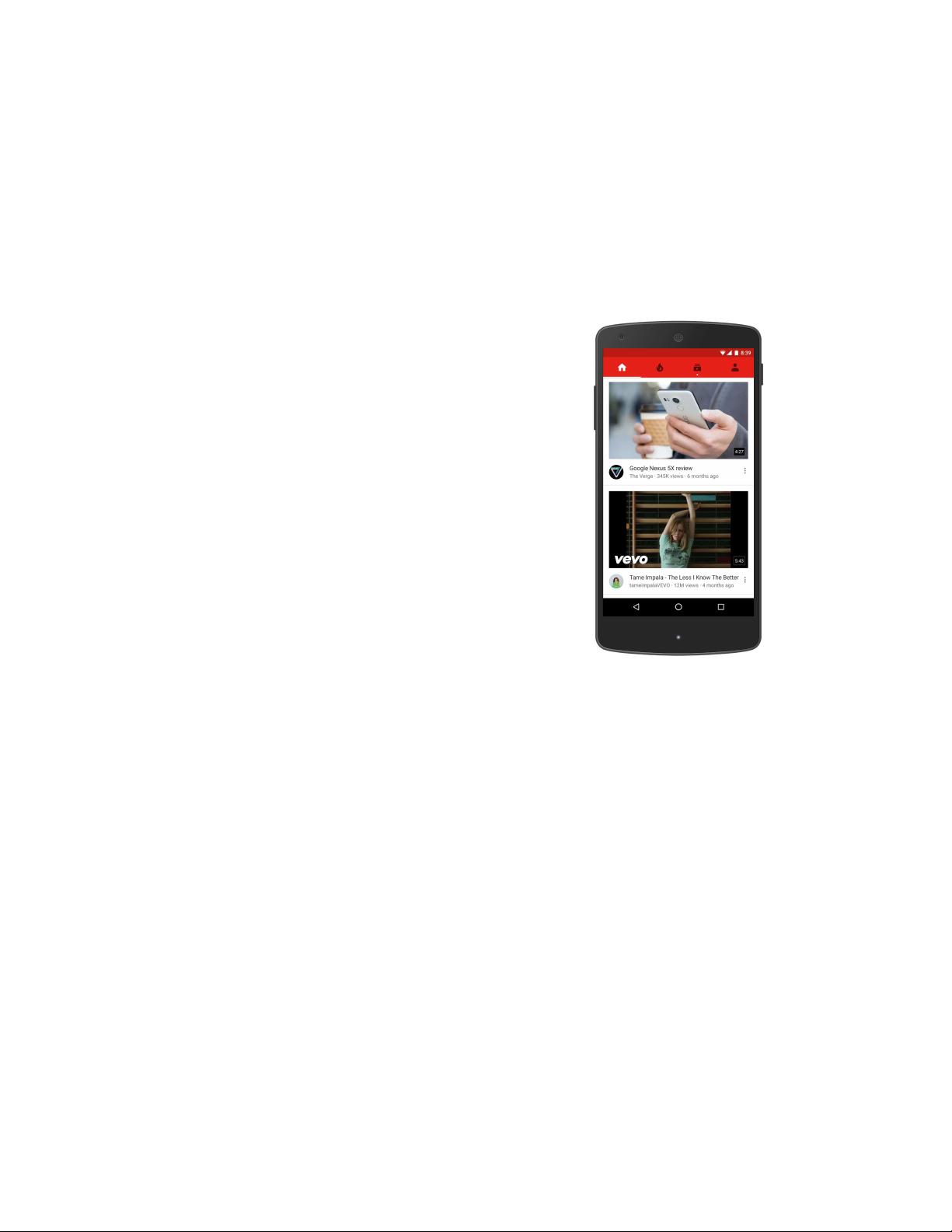
recommendations system. Figure 1 illustrates the recom-
mendations on the YouTube mobile app home.
Recommending YouTube videos is extremely challenging
from three major perspectives:
• Scale: Many existing recommendation algorithms proven
to work well on small problems fail to operate on our
scale. Highly specialized distributed learning algorithms
and efficient serving systems are essential for handling
YouTube’s massive user base and corpus.
• Freshness: YouTube has a very dynamic corpus with
many hours of video are uploaded per second. The
recommendation system should be responsive enough
to model newly uploaded content as well as the lat-
est actions taken by the user. Balancing new content
Permission to make digital or hard copies of part or all of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for third-party components of this work must be honored.
For all other uses, contact the owner/author(s).
RecSys ’16 September 15-19, 2016, Boston , MA, USA
c
2016 Copyright held by the owner/author(s).
ACM ISBN 978-1-4503-4035-9/16/09.
DOI: http://dx.doi.org/10.1145/2959100.2959190
Figure 1: Recommendations displayed on YouTube
mobile app home.
with well-established videos can be understood from
an exploration/exploitation perspective.
• Noise: Historical user behavior on YouTube is inher-
ently difficult to predict due to sparsity and a vari-
ety of unobservable external factors. We rarely ob-
tain the ground truth of user satisfaction and instead
model noisy implicit feedback signals. Furthermore,
metadata associated with content is poorly structured
without a well defined ontology. Our algorithms need
to be robust to these particular characteristics of our
training data.
In conjugation with other product areas across Google,
YouTube has undergone a fundamental paradigm shift to-
wards using deep learning as a general-purpose solution for
nearly all learning problems. Our system is built on Google
Brain [4] which was recently open sourced as TensorFlow [1].
TensorFlow provides a flexible framework for experimenting
with various deep neural network architectures using large-
scale distributed training. Our models learn approximately
one billion parameters and are trained on hundreds of bil-
lions of examples.
In contrast to vast amount of research in matrix factoriza-
剩余7页未读,继续阅读
资源评论













