Python正则表达式操作指南 - Ubuntu中文
http://wiki.ubuntu.org.cn/index.php?title=Python正则表达式操作指南&variant=zh-hans[2011-8-10 14:05:18]
[编辑]
[
编辑]
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。Python 1.5之前版本则是通过 regex 模块提供 Emacs 风格的模式。Emacs 风格
模式可读性稍差些,而且功能也不强,因此编写新代码时尽量不要再使用 regex 模块,当然偶尔你还是可能在老代码里发现其踪影。
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。使用这个小型语言,
你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。然后你可以问诸如“这个字符串匹配
该模式吗?”或“在这个字符串中是否有部分匹配该模式呢?”。你也可以使用 RE 以各种方式来修改或分割字符串。
正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。在高级用法中,也许还要仔细留意引擎是如何执行给定 RE ,如何以特定方式编写
RE 以令生产的字节码运行速度更快。本文并不涉及优化,因为那要求你已充分掌握了匹配引擎的内部机制。
正则表达式语言相对小型和受限(功能有限),因此并非所有字符串处理都能用正则表达式完成。当然也有些任务可以用正则表达式完成,不过最终表达式会变
得异常复杂。碰到这些情形时,编写 Python 代码进行处理可能反而更好;尽管 Python 代码比一个精巧的正则表达式要慢些,但它更易理解。
简单模式
我们将从最简单的正则表达式学习开始。由于正则表达式常用于字符串操作,那我们就从最常见的任务:字符匹配 下手。
有关正则表达式底层的计算机科学上的详细解释(确定性和非确定性有限自动机),你可以查阅编写编译器相关的任何教科书。
字符匹配
大多数字母和字符一般都会和自身匹配。例如,正则表达式 test 会和字符串“test”完全匹配。(你也可以使用大小写不敏感模式,它还能让这个 RE 匹
配“Test”或“TEST”;稍后会有更多解释。)
这个规则当然会有例外;有些字符比较特殊,它们和自身并不匹配,而是会表明应和一些特殊的东西匹配,或者它们会影响到 RE 其它部分的重复次数。本文很
大篇幅专门讨论了各种元字符及其作用。
这里有一个元字符的完整列表;其含义会在本指南余下部分进行讨论。
我们首先考察的元字符是"[" 和 "]"。它们常用来指定一个字符类别,所谓字符类别就是你想匹配的一个字符集。字符可以单个列出,也可以用“-”号分隔的两个
给定字符来表示一个字符区间。例如,[abc] 将匹配"a", "b", 或 "c"中的任意一个字符;也可以用区间[a-c]来表示同一字符集,和前者效果一致。如果你只想
匹配小写字母,那么 RE 应写成 [a-z].
元字符在类别里并不起作用。例如,[akm$]将匹配字符"a", "k", "m", 或 "$" 中的任意一个;"$"通常用作元字符,但在字符类别里,其特性被除去,恢复成普
通字符。
你可以用补集来匹配不在区间范围内的字符。其做法是把"^"作为类别的首个字符;其它地方的"^"只会简单匹配 "^"字符本身。例如,[^5] 将匹配除 "5" 之外
的任意字符。
也许最重要的元字符是反斜杠"\"。 做为 Python 中的字符串字母,反斜杠后面可以加不同的字符以表示不同特殊意义。它也可以用于取消所有的元字符,这样
你就可以在模式中匹配它们了。举个例子,如果你需要匹配字符 "[" 或 "\",你可以在它们之前用反斜杠来取消它们的特殊意义: \[ 或 \\。
一些用 "\" 开始的特殊字符所表示的预定义字符集通常是很有用的,象数字集,字母集,或其它非空字符集。下列是可用的预设特殊字符:
这样特殊字符都可以包含在一个字符类中。如,[\s,.]字符类将匹配任何空白字符或","或"."。
本节最后一个元字符是 . 。它匹配除了换行字符外的任何字符,在 alternate 模式(re.DOTALL)下它甚至可以匹配换行。"." 通常被用于你想匹配“任何字
符”的地方。
重复
正则表达式第一件能做的事是能够匹配不定长的字符集,而这是其它能作用在字符串上的方法所不能做到的。 不过,如果那是正则表达式唯一的附加功能的话,
那么它们也就不那么优秀了。它们的另一个功能就是你可以指定正则表达式的一部分的重复次数。
我们讨论的第一个重复功能的元字符是 *。* 并不匹配字母字符 "*";相反,它指定前一个字符可以被匹配零次或更多次,而不是只有一次。
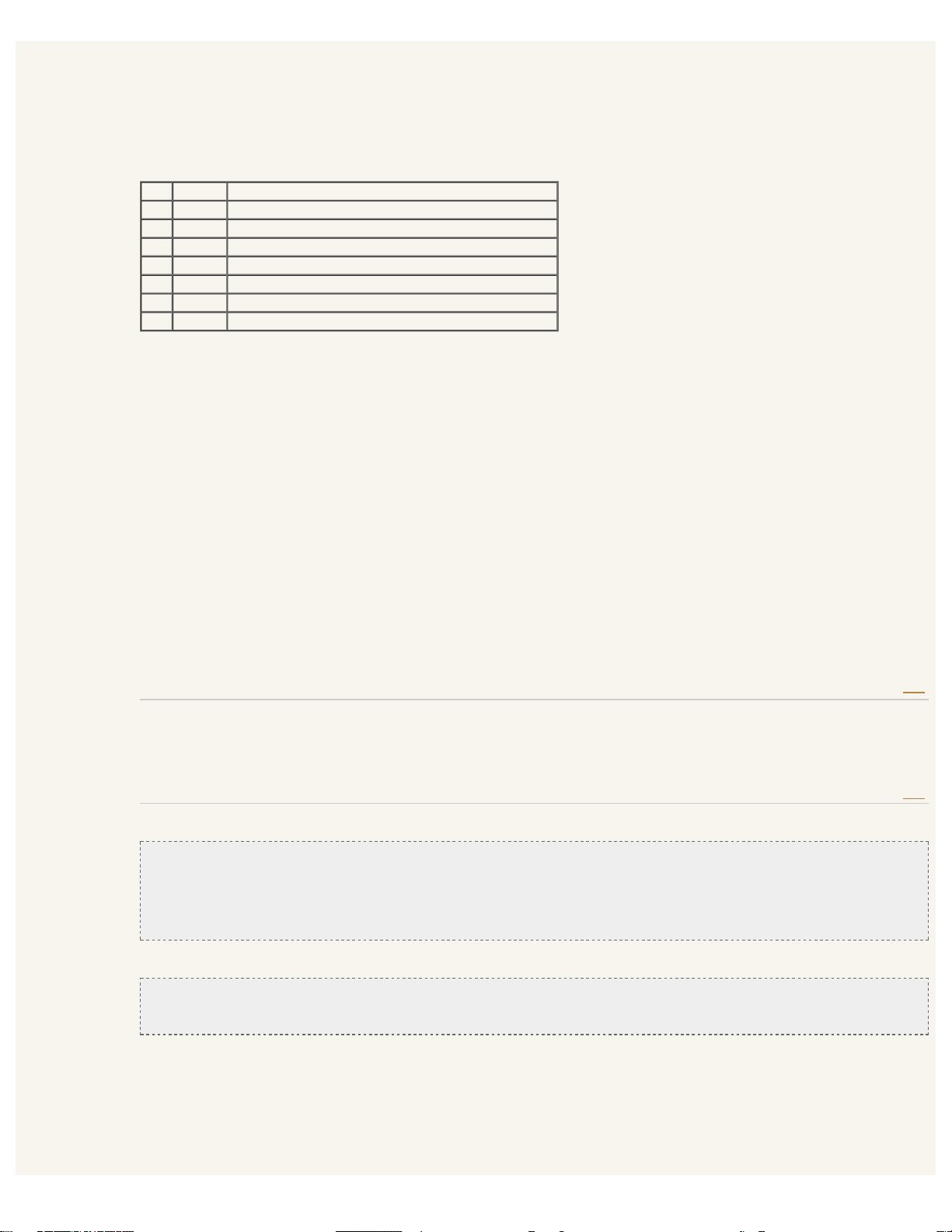
. ^ $ * + ? { [ ] \ | ( )
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]。



 raymentblog2012-07-21还可以,但是案例不够多。
raymentblog2012-07-21还可以,但是案例不够多。











