

1
Deep Sentence Embedding Using Long
Short-Term Memory Networks: Analysis and
Application to Information Retrieval
Hamid Palangi, Li Deng, Yelong Shen, Jianfeng Gao, Xiaodong He, Jianshu Chen, Xinying Song,
Rabab Ward
Abstract—This paper develops a model that addresses
sentence embedding, a hot topic in current natural lan-
guage processing research, using recurrent neural networks
(RNN) with Long Short-Term Memory (LSTM) cells. The
proposed LSTM-RNN model sequentially takes each word
in a sentence, extracts its information, and embeds it into
a semantic vector. Due to its ability to capture long term
memory, the LSTM-RNN accumulates increasingly richer
information as it goes through the sentence, and when it
reaches the last word, the hidden layer of the network
provides a semantic representation of the whole sentence.
In this paper, the LSTM-RNN is trained in a weakly
supervised manner on user click-through data logged by a
commercial web search engine. Visualization and analysis
are performed to understand how the embedding process
works. The model is found to automatically attenuate the
unimportant words and detects the salient keywords in
the sentence. Furthermore, these detected keywords are
found to automatically activate different cells of the LSTM-
RNN, where words belonging to a similar topic activate the
same cell. As a semantic representation of the sentence,
the embedding vector can be used in many different
applications. These automatic keyword detection and topic
allocation abilities enabled by the LSTM-RNN allow the
network to perform document retrieval, a difficult language
processing task, where the similarity between the query and
documents can be measured by the distance between their
corresponding sentence embedding vectors computed by
the LSTM-RNN. On a web search task, the LSTM-RNN
embedding is shown to significantly outperform several
existing state of the art methods. We emphasize that the
proposed model generates sentence embedding vectors that
are specially useful for web document retrieval tasks. A
comparison with a well known general sentence embedding
method, the Paragraph Vector, is performed. The results
show that the proposed method in this paper significantly
outperforms it for web document retrieval task.
Index Terms—Deep Learning, Long Short-Term Mem-
ory, Sentence Embedding.
I. INTRODUCTION
H. Palangi and R. Ward are with the Department of Electrical and
Computer Engineering, University of British Columbia, Vancouver,
BC, V6T 1Z4 Canada (e-mail: {hamidp,rababw}@ece.ubc.ca)
L. Deng, Y. Shen, J.Gao, X. He, J. Chen and X. Song are
with Microsoft Research, Redmond, WA 98052 USA (e-mail:
{deng,jfgao,xiaohe,yeshen,jianshuc,xinson}@microsoft.com)
L
EARNING a good representation (or features) of
input data is an important task in machine learning.
In text and language processing, one such problem is
learning of an embedding vector for a sentence; that is, to
train a model that can automatically transform a sentence
to a vector that encodes the semantic meaning of the
sentence. While word embedding is learned using a
loss function defined on word pairs, sentence embedding
is learned using a loss function defined on sentence
pairs. In the sentence embedding usually the relationship
among words in the sentence, i.e., the context informa-
tion, is taken into consideration. Therefore, sentence em-
bedding is more suitable for tasks that require computing
semantic similarities between text strings. By mapping
texts into a unified semantic representation, the embed-
ding vector can be further used for different language
processing applications, such as machine translation [1],
sentiment analysis [2], and information retrieval [3].
In machine translation, the recurrent neural networks
(RNN) with Long Short-Term Memory (LSTM) cells, or
the LSTM-RNN, is used to encode an English sentence
into a vector, which contains the semantic meaning of
the input sentence, and then another LSTM-RNN is
used to generate a French (or another target language)
sentence from the vector. The model is trained to best
predict the output sentence. In [2], a paragraph vector
is learned in an unsupervised manner as a distributed
representation of sentences and documents, which are
then used for sentiment analysis. Sentence embedding
can also be applied to information retrieval, where the
contextual information are properly represented by the
vectors in the same space for fuzzy text matching [3].
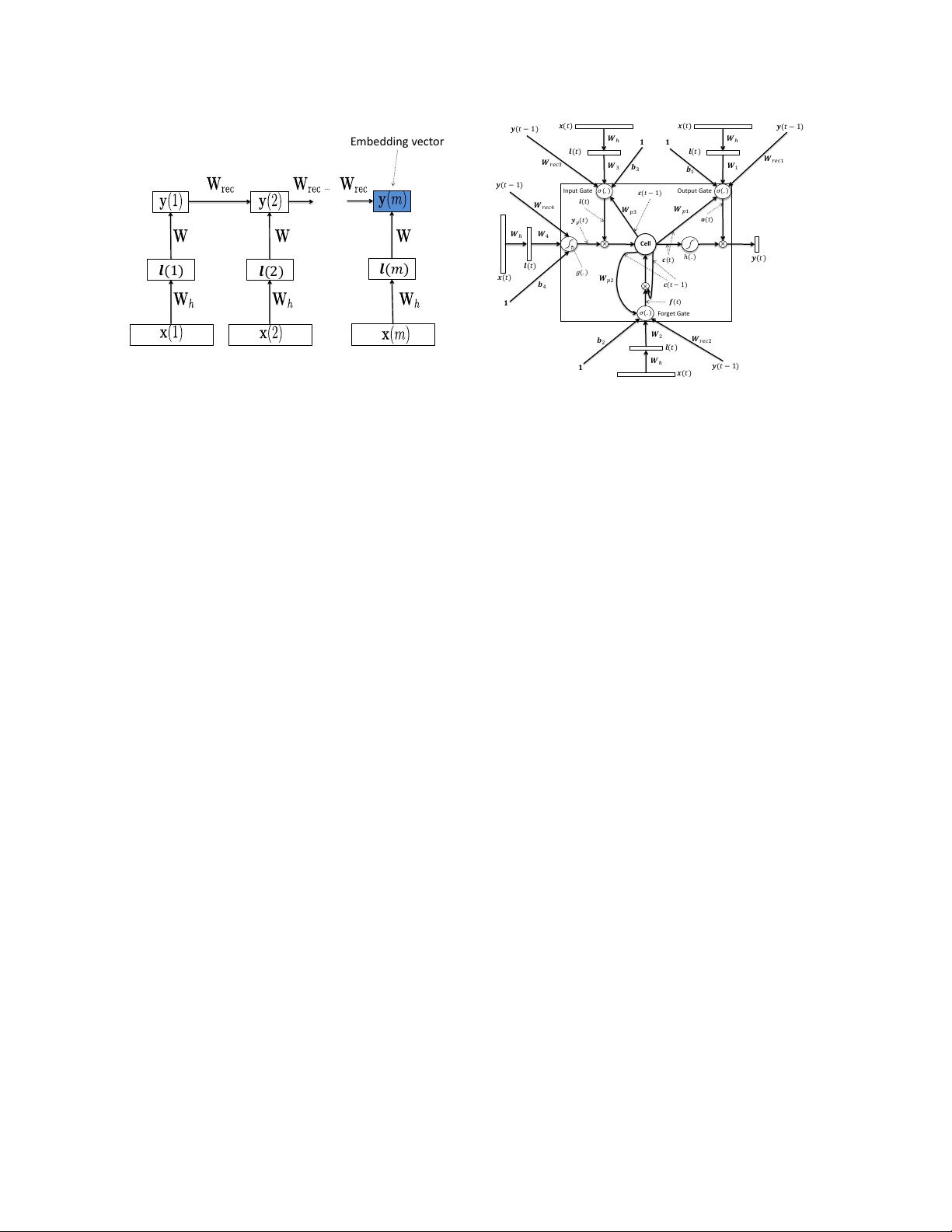
In this paper, we propose to use an RNN to sequen-
tially accept each word in a sentence and recurrently map
it into a latent space together with the historical informa-
tion. As the RNN reaches the last word in the sentence,
the hidden activations form a natural embedding vector
for the contextual information of the sentence. We further
incorporate the LSTM cells into the RNN model (i.e. the
LSTM-RNN) to address the difficulty of learning long
term memory in RNN. The learning of such a model
arXiv:1502.06922v3 [cs.CL] 16 Jan 2016


剩余24页未读,继续阅读
资源评论


ken_henderson
- 粉丝: 2
- 资源: 11









最新资源
- C# winform置托盘图标并闪烁演示源码.zip
- 打包和分发Rust工具.pdf
- SQL中的CREATE LOGFILE GROUP 语句.pdf
- C语言-leetcode题解之第172题阶乘后的零.zip
- C语言-leetcode题解之第171题Excel列表序号.zip
- C语言-leetcode题解之第169题多数元素.zip
- ocr-图像识别资源ocr-图像识别资源
- 图像识别:基于Resnet50 + VGG16模型融合的人体细胞癌症分类模型实现-图像识别资源
- C语言-leetcode题解之第168题Excel列表名称.zip
- C语言-leetcode题解之第167题两数之和II-输入有序数组.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


