
千万日活腾讯会议背后:深度学习的最新应用
深度学习是实现语音增强最主要的方法之一,帮助我们从带噪语音中提取尽可能纯净的原
始语音,提高语音质量和可懂度。腾讯会议在去年年底推出,短短两个月内就突破千万日
活大关。在多样且复杂的场景下,深度学习如何帮助腾讯会议在实时通话中进行去混响、
声音事件检测和回声消除?本文是腾讯多媒体实验室高级研究员王燕南在「腾讯技术开放
日·云视频会议专场」的分享整理。
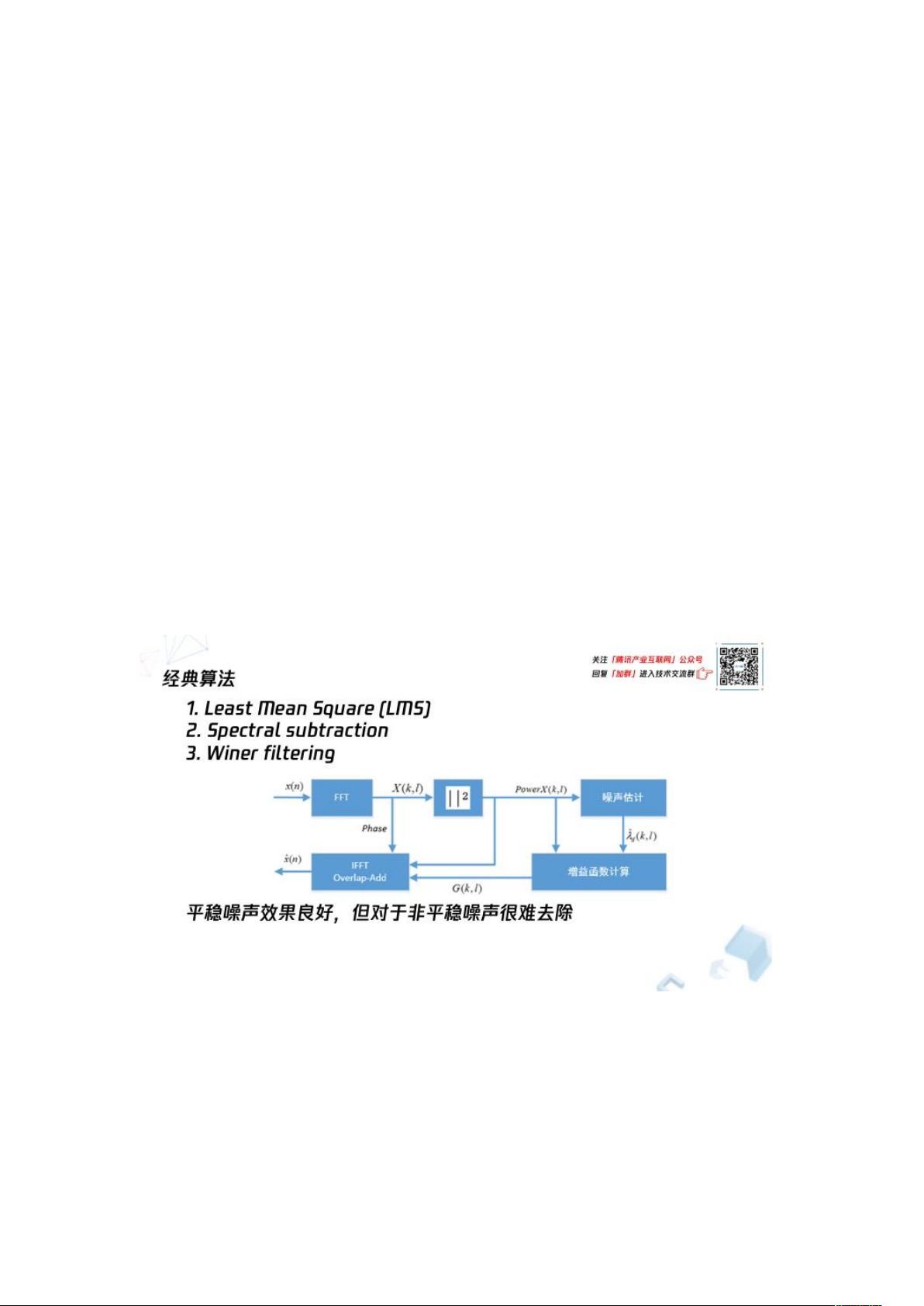
经典的语音增强深度学习算法
语音增强是指当语音信号被各种各样的噪声干扰、甚至淹没后,从噪声背景中提取有用的
语音信号,抑制、降低噪声干扰的技术。它的主要目标是从带噪语音中提取尽可能纯净的
原始语音,提高语音质量和可懂度。比如希望对方即使在飞机驾驶舱噪音环境中说话,我
们也能听清楚。
做语音增强会用到一些经典算法,我们之前自己的应用,以及竞品的应用中使用比较多也
比较成熟的算法主要有下面几种。当然算法每家不一样,本质上都是一些估计的方式:
1. Least Mean Square (LMS)
2. Spectral subtraction
3. Winer ltering
这些经典的算法,相对于其他比较激进的算法,其实大部分场景下效果都很好,特别对于
音质的保留。因为自然界或者工作生活中的噪声非常多,各种各样,所以有时候我们利用
经典算法,会达到满意的效果。还有一些常见的声音,比如键盘鼠标或者关门的声音,因
为我们关注的比较多,研究的比较多,针对这些特定类型的噪声,特定类型的算法,我们
可以做一些改进或者做新算法的研究,来提升我们现在的传统算法的效果。

剩余7页未读,继续阅读
资源评论


腾讯开发者
- 粉丝: 1485
- 资源: 52









最新资源
- 5G SRM815模组原理框图.jpg
- T型3电平逆变器,lcl滤波器滤波器参数计算,半导体损耗计算,逆变电感参数设计损耗计算 mathcad格式输出,方便修改 同时支持plecs损耗仿真,基于plecs的闭环仿真,电压外环,电流内环
- 毒舌(解锁版).apk
- 显示HEX、S19、Bin、VBF等其他汽车制造商特定的文件格式
- 8bit逐次逼近型SAR ADC电路设计成品 入门时期的第三款sarADC,适合新手学习等 包括电路文件和详细设计文档 smic0.18工艺,单端结构,3.3V供电 整体采样率500k,可实现基
- 操作系统实验 ucorelab4内核线程管理
- 脉冲注入法,持续注入,启动低速运行过程中注入,电感法,ipd,力矩保持,无霍尔无感方案,媲美有霍尔效果 bldc控制器方案,无刷电机 提供源码,原理图
- Matlab Simulink#直驱永磁风电机组并网仿真模型 基于永磁直驱式风机并网仿真模型 采用背靠背双PWM变流器,先整流,再逆变 不仅实现电机侧的有功、无功功率的解耦控制和转速调节,而且能实
- 157389节奏盒子地狱模式第三阶段7.apk
- 操作系统实验ucore lab3
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


