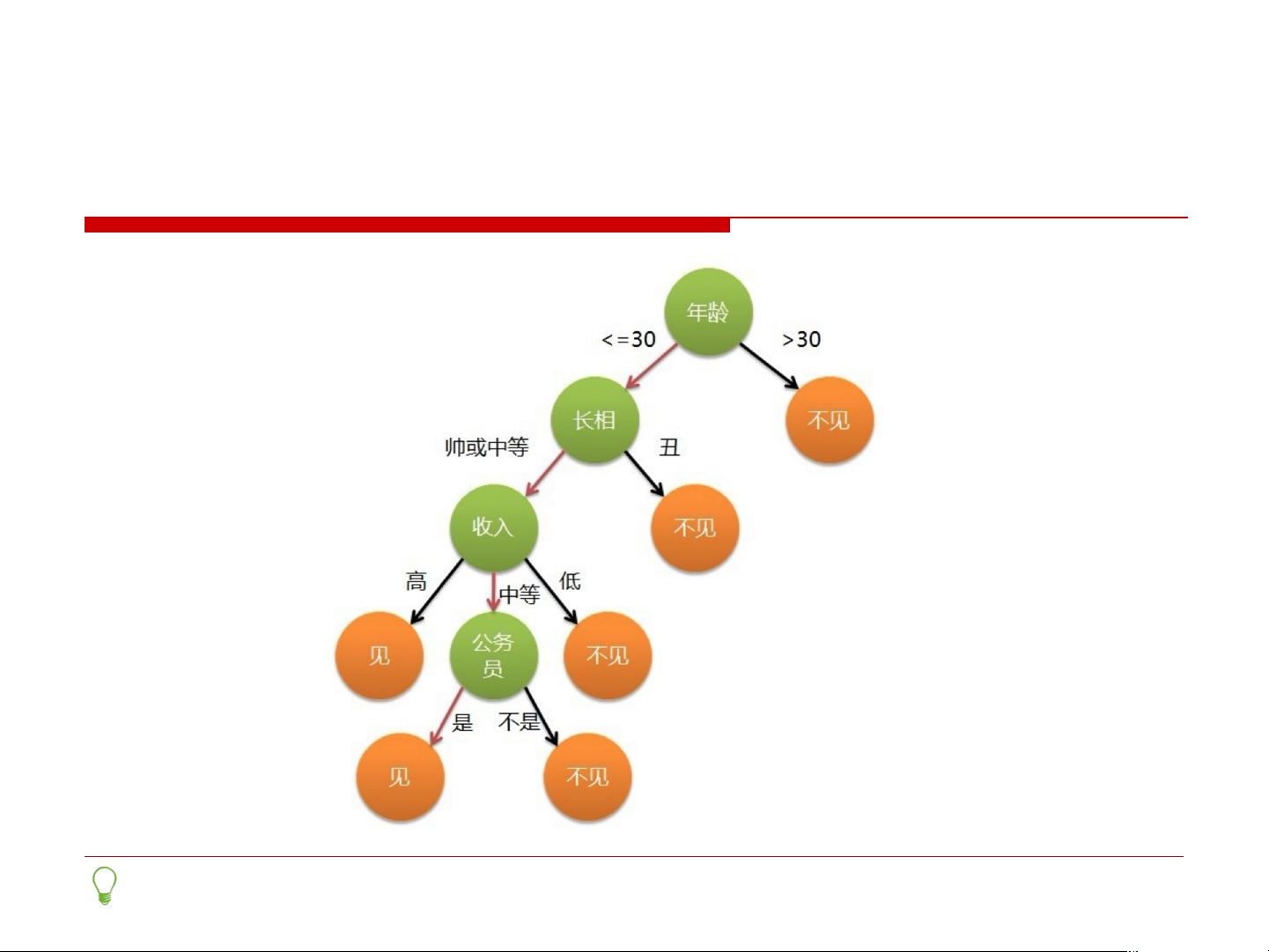
决策树是一种常见的机器学习算法,它采用树形结构对数据进行预测和分类。决策树由节点和有向边组成,每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
熵(Entropy)是决策树算法中用来衡量数据集纯度的一个重要概念。熵越高,数据集的不确定性越大,纯度越低。在决策树中,我们希望找到一个属性,通过它来划分数据集,使得划分后每个子集的熵都尽可能地小,从而提高数据集的纯度。
信息增益(Information Gain)是基于熵来度量属性划分数据集前后的信息变化,是选择最优划分属性的标准。一个属性的划分带来的信息增益越大,说明使用这个属性划分数据集的效果越好。
常见的决策树算法有ID3、C4.5、CART等。ID3算法使用信息增益来选择特征,而C4.5是ID3的改进版本,它使用信息增益比(Gain Ratio)来选择特征。CART算法则采用基尼指数(Gini Index)来构建二叉决策树。
过度拟合(Overfitting)是机器学习中的一个常见问题,决策树算法也不例外。当树构建得过于复杂时,可能会发生过度拟合现象,即模型在训练数据上表现很好,但在未知数据上泛化能力差。避免过度拟合的一种方法是剪枝(Pruning),即去除树中不必要的节点,简化模型。
增益率(Gain Ratio)是信息增益的改进,它考虑了属性的固有信息量。某些属性可能有较高的信息增益,但其分支数非常多,这种情况下用增益率可能会得到更好的划分属性。
决策树的应用场景非常广泛,包括连续函数预测、多分类问题、回归任务等。通过一系列决策规则,决策树能够从数据集中学习出简洁的规则,用以对未知数据进行分类或回归。
随机森林(Random Forest)是决策树的一种集成学习方法,它通过构建多个决策树并结合它们的预测结果来提高整体模型的准确性和泛化能力。随机森林通过引入随机性来构造不同的决策树,通常做法是在构建每棵决策树时,随机选择部分特征和数据样本。
Boosting是另一类提升模型准确率的集成学习方法,它的基本思想是将多个弱学习器按照一定的顺序生成,并且每个弱学习器在训练过程中都依赖于前一个学习器的输出结果。常用的Boosting算法有GBDT(Gradient Boosting Decision Tree)和XGBoost等。GBDT是一种基于梯度提升的决策树算法,而XGBoost是GBDT的优化版本,它在损失函数上引入了正则化项,对模型的复杂度进行控制,防止过拟合。
以上提到的算法和概念均属于机器学习的基础理论,它们在多个领域中有着广泛的应用。例如,随机森林和GBDT常常用于金融行业的信用评分模型,XGBoost则因其高效的计算速度和良好的预测性能,被应用于各种竞赛和实际问题中。这些算法不仅丰富了机器学习的理论体系,也为解决实际问题提供了强有力的工具。