2016年辽宁大学分布式操作系统习题整理
需积分: 13 140 浏览量
2016-06-27
10:47:49
上传
评论 3
收藏 15.12MB DOC 举报


1
2016 整理 JXY
2016 辽宁大学分布式操作系统思考题
(6)1 在交换式 Dash 多处理机系统中,为了保持缓存一致性,采用了 Dash 协议,某一簇
中的一 CPU 写一未缓存的数据块,之后另外一簇的另外一 CPU 读该数据块。试详细说明
写操作和读操作是如何进行的。
答:写操作:写数据块的 CPU 先在本地总线发送请求察看邻近 CPU 的缓存中
是否有该数据块。如果有,执行缓冲区到缓冲区的传送,如果块状态为干净宿
主所在簇的其他拷贝必须被置为无效。若邻近 CPU 的缓存中没有该数据块,本
次查找失败,数据块在其他地方,CPU 发送信包到其宿主所在簇。如果块为未
缓存,标记为脏并发送给请求者;如果块为干净,所有拷贝置为无效,标记为
脏并发送给请求者;如果块为脏,请求传送到拥有该数据块拷贝的远程簇,该
簇将自己的拷贝置为无效并满足写操作。
读操作:读数据块的 CPU 首先检查自己的缓存,若缓存中无此字,则在本地簇
中发出请求,询问本地簇的其他 CPU 缓存中是否有此字。如果有,该数据块从
该缓存传送到发出申请的 CPU 缓存中。若该块的状态是干净,拷贝此数据块。
若为脏,其目录将此块标记为干净,使之共享。如果数据块不在任何簇的缓存
中,CPU 发一请求信包给该块的宿主所在簇。宿主所在簇的目录管理硬件检查
它的表以确定其状态。若为未缓存或者干净,硬件从全局存储器中取出块,将
其发送到请求簇,该簇更新其目录,表明该块已在缓冲区中。若此处状态为
DIRTY,目录硬件查找拥有该块的簇的标志,该簇相应请求。拥有 DIRTY 块的
簇将数据块发送给请求簇,并因为数据已共享,将其状态改为 CLEAN,它还要
给宿主所在簇发回一个拷贝以更新存储器,此时块的状态置为 CLEAN。
(6)1-1 在基于环的多处理机系统 Memnet 中,通过令牌环进行通信,并且没有集中式全
局存储器,详细说明如何实现读写操作。
答:读操作:当 CPU 要从共享存储器中读一个字时,该存储器地址传送给
Memnet 设备,Memnet 设备检查表项以确定该块是否存在。若存在,读请求立
即得到满足。否则,Memnet 设备等待直到俘获循环的令牌,将请求信包送入环
中,并挂起 CPU。请求信包包含目标地址和 32 字节哑域。信包在环中传递的过
程中,每个 Memnet 设备 double 检查自己是否有所需的块,若有责将块置入哑
域,修改信包头使下一个机器不再重复此工作。若块中的互斥位置位,则清除
它。因为某数据块一定位于系统某处,因此当信包返回发送点时,一定包含了
所需的块。CPU 发出请求并存储块,满足请求以后释放 CPU。
写操作:若包含要写字的块存在于本地并且是系统中的唯一拷贝,字就在本地
写入。若所需块在本地存在但不是系统中的唯一拷贝,CPU 将在环中发出置无
效信包,强制其他机器抛弃此块的拷贝。当置无效信包返回时,将该块的互斥
位置位,字在本地写入。若本地不存在所需块,CPU 则发出包含读请求和置无
效请求的信包。第一个有此数据块的机器将该块拷入信包,同时抛弃自己的拷
贝。其余的机器仅从自己的缓存中抛弃该数据块。当信包返回到发送者时,本
地储存该数据块并执行写操作。
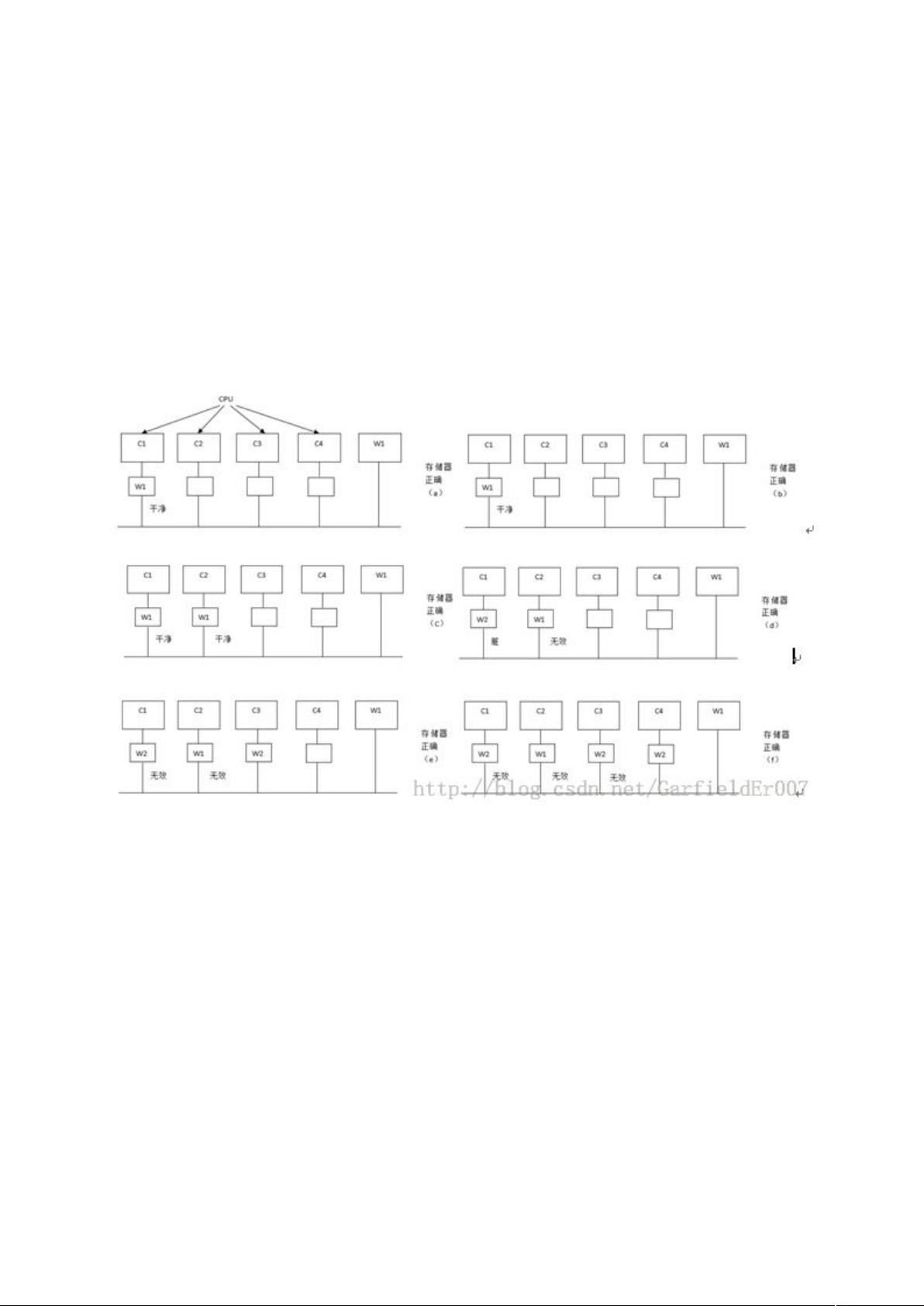
(6)2 在基于总线的多处理机系统中,遵循 write once 协议,假设有 C1,C2,C3,C4 四
个 CPU,一操作序列如下:C1 读一字 W1(只存在于共享存储器中)、C1 继续读该字、


剩余31页未读,继续阅读
资源评论


jujuezaiai1992
- 粉丝: 0
- 资源: 2









最新资源
- 机械设计整经机上纱自动化sw20非常好的设计图纸100%好用.zip
- Screenshot_20240427_031602.jpg
- 网页PDF_2024年04月26日 23-46-14_QQ浏览器网页保存_QQ浏览器转格式(6).docx
- 直接插入排序,冒泡排序,直接选择排序.zip
- 在排序2的基础上,再次对快排进行优化,其次增加快排非递归,归并排序,归并排序非递归版.zip
- 实现了7种排序算法.三种复杂度排序.三种nlogn复杂度排序(堆排序,归并排序,快速排序)一种线性复杂度的排序.zip
- 冒泡排序 直接选择排序 直接插入排序 随机快速排序 归并排序 堆排序.zip
- 课设-内部排序算法比较 包括冒泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、归并排序和堆排序.zip
- Python排序算法.zip
- C语言实现直接插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序、归并排序、计数排序,并带图详解.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


