

Automatic Evaluation of Attribution by Large Language Models
Xiang Yue Boshi Wang Ziru Chen Kai Zhang Yu Su Huan Sun
The Ohio State University
{yue.149,wang.13930,chen.8336,zhang.13253,su.809,sun.397}@osu.edu
Abstract
A recent focus of large language model (LLM)
development, as exemplified by generative
search engines, is to incorporate external refer-
ences to generate and support its claims. How-
ever, evaluating the attribution, i.e., verifying
whether the generated statement is fully sup-
ported by the cited reference, remains an open
problem. Although human evaluation is com-
mon practice, it is costly and time-consuming.
In this paper, we investigate automatic evalu-
ation of attribution given by LLMs. We be-
gin by defining different types of attribution
errors, and then explore two approaches for
automatic evaluation: prompting LLMs and
fine-tuning smaller LMs. The fine-tuning data
is repurposed from related tasks such as ques-
tion answering, fact-checking, natural language
inference, and summarization. We manually cu-
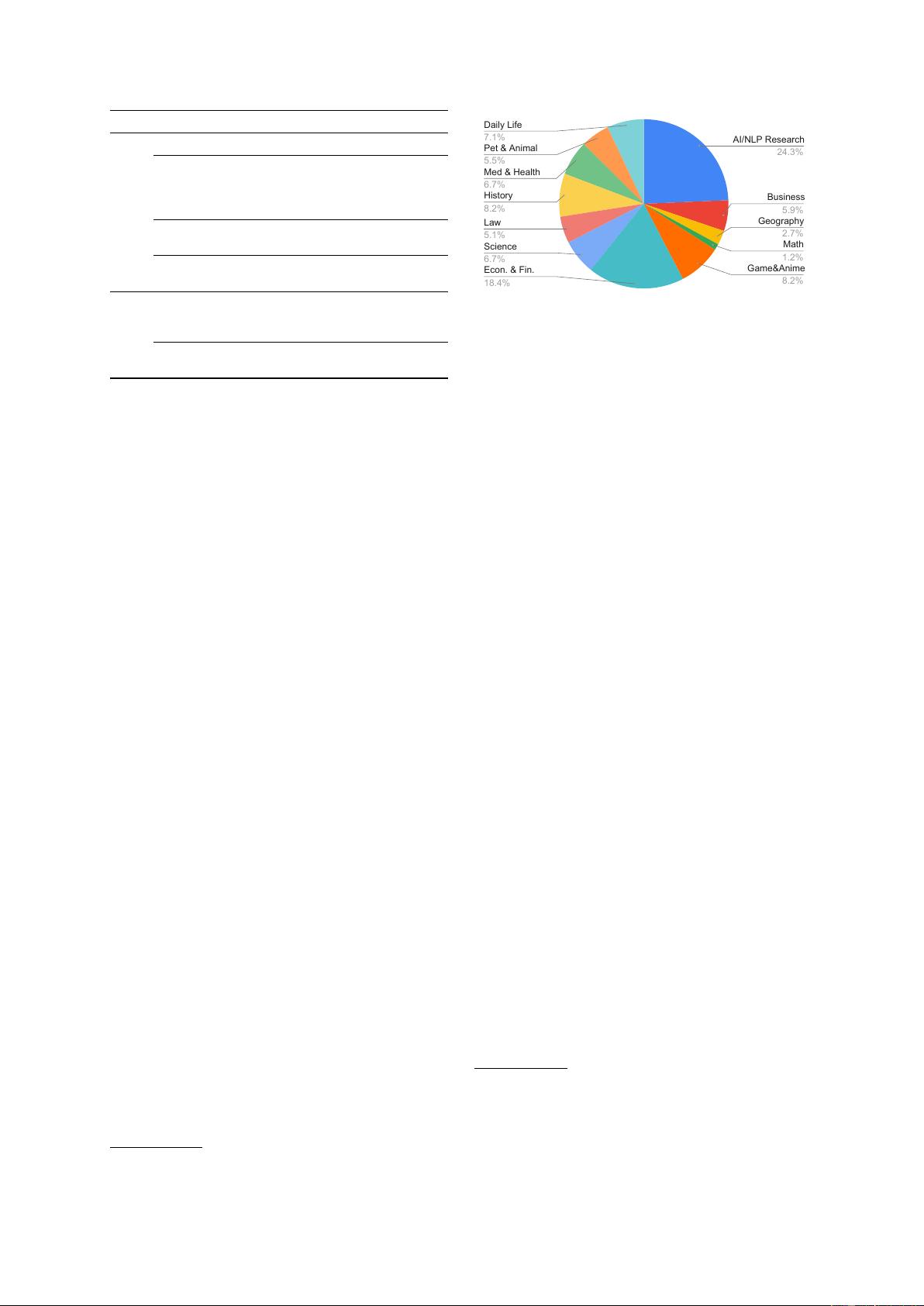
rate a set of test examples covering 12 domains
from a generative search engine, New Bing.
Our results on this curated test set and simu-
lated examples from existing benchmarks high-
light both promising signals and challenges.
We hope our problem formulation, testbeds,
and findings will help lay the foundation for
future studies on this important problem.
1
1 Introduction
Generative large language models (LLMs) (Brown
et al., 2020; Ouyang et al., 2022; Chowdhery et al.,
2022; OpenAI, 2023a,b, inter alia) often struggle
with producing factually accurate statements, re-
sulting in hallucinations (Ji et al., 2023). Recent
efforts aim to alleviate this issue by augmenting
LLMs with external tools (Schick et al., 2023) such
as retrievers (Shuster et al., 2021; Borgeaud et al.,
2022) and search engines (Nakano et al., 2021;
Thoppilan et al., 2022; Shuster et al., 2022).
Incorporating external references for generation
inherently implies that the generated statement is
1
Our code and dataset are available at:
https://github.
com/OSU-NLP-Group/AttrScore
backed by these references. However, the valid-
ity of such attribution, i.e., whether the generated
statement is fully supported by the cited reference,
remains questionable.
2
According to Liu et al.
(2023), only 52% of the statements generated by
state-of-the-art generative search engines such as
New Bing and PerplexityAI are fully supported by
their respective cited references.
3
Inaccurate attribution compromises the trustwor-
thiness of LLMs, introducing significant safety
risks and potential harm. For instance, in health-
care, an LLM might attribute incorrect medical ad-
vice to a credible source, potentially leading users
to make harmful health decisions. Similarly, in
finance, faulty investment advice attributed to a re-
liable source may cause substantial financial losses.
To identify attribution errors, existing attributed
LLMs (Nakano et al., 2021; Thoppilan et al., 2022)
rely heavily on human evaluation, which is both
expensive and time-consuming. For instance, the
average cost of annotating a single (query, answer,
reference) example is about $1 in Liu et al. (2023).
In the actual use of attributed LLMs, it is the user
who needs to be wary of the attribution and manu-
ally verify it, which puts a tremendous burden on
their side. Therefore, effective and reliable meth-
ods to automatically evaluate attribution and iden-
tify potential attribution errors are highly desired.
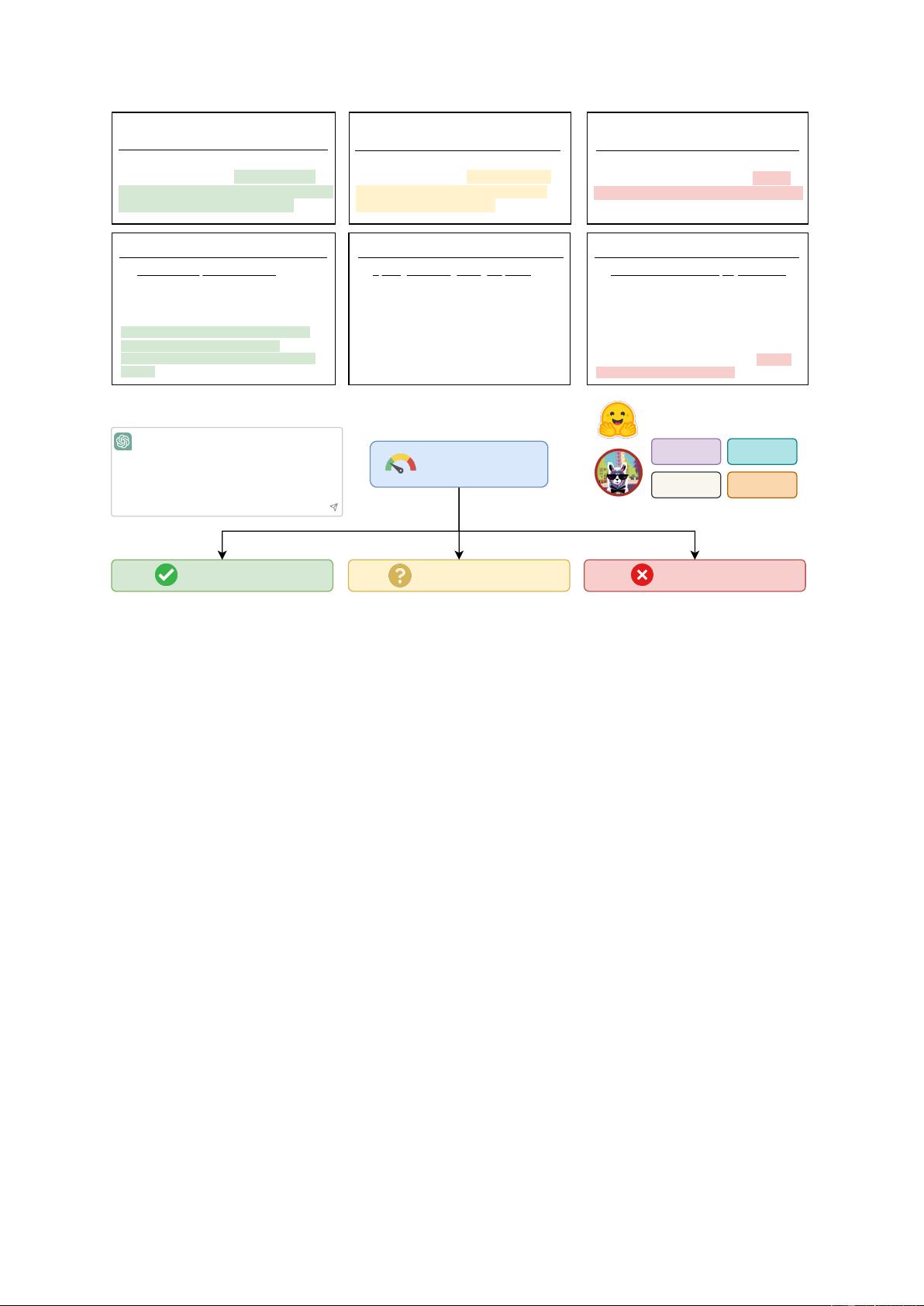
Towards this goal, we take the first step by intro-
ducing AttrScore (Figure 1), a framework designed
for automatic evaluation of attribution and identi-
fication of specific types of attribution errors. We
propose a new problem formulation that catego-
rizes attribution into three types: 1) attributable:
the reference fully supports the generated state-
ment; 2) extrapolatory: the reference lacks suffi-
cient information to support the generated state-
2
Attribution primarily refers to “the act of attributing some-
thing” in this paper, which is similar to “verifiability” as de-
fined in Liu et al. (2023).
3
www.bing.com/new, www.perplexity.ai
arXiv:2305.06311v2 [cs.CL] 7 Oct 2023


剩余20页未读,继续阅读
资源评论


pk_xz123456
- 粉丝: 2304
- 资源: 2398

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 非常好的python入门书傻瓜式教程100%好用.zip
- 小型流畅接口,更轻松地在 redis 中缓存 sequelize 数据库查询结果.zip
- 火焰检测19-YOLO(v5至v7)、COCO、CreateML、Darknet、Paligemma、TFRecord、VOC数据集合集.rar
- 项目二 李白代表作品页面(资源)
- 将数据存储在 Redis 数据库中的 Node.js 应用.zip
- 将你的 Laravel 应用程序与 redis 管理器集成.zip
- 将一个 redis db 复制到另一个 redis db.zip
- 将 redis 示例 twitter 应用程序移植到 Ruby 和 Sinatra.zip
- 非常好的Python入门教程100%好用.zip
- 非常好的教程Python 编程指南100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


