

API-Bank: A Benchmark for Tool-Augmented LLMs
Minghao Li
1
, Feifan Song
2
, Bowen Yu
1
∗
, Haiyang Yu
1
, Zhoujun Li
3
, Fei Huang
1
, Yongbin Li
1
1
Alibaba DAMO Academy
2
MOE Key Laboratory of Computational Linguistics, Peking University
3
Shenzhen Intelligent Strong Technology Co., Ltd.
{lmh397008, yubowen.ybw, yifei.yhy, f.huang, shuide.lyb}@alibaba-inc.com
songff@stu.pku.edu.cn
lizhoujun@aistrong.com
Abstract
Recent research has shown that Large Lan-
guage Models (LLMs) can utilize external
tools to improve their contextual processing
abilities, moving away from the pure language
modeling paradigm and paving the way for
Artificial General Intelligence. Despite this,
there has been a lack of systematic evalua-
tion to demonstrate the efficacy of LLMs using
tools to respond to human instructions. This
paper presents API-Bank, the first benchmark
tailored for Tool-Augmented LLMs. API-
Bank includes 53 commonly used API tools,
a complete Tool-Augmented LLM workflow,
and 264 annotated dialogues that encompass
a total of 568 API calls. These resources have
been designed to thoroughly evaluate LLMs’
ability to plan step-by-step API calls, retrieve
relevant APIs, and correctly execute API calls
to meet human needs. The experimental re-
sults show that GPT-3.5 emerges the ability to
use the tools relative to GPT3, while GPT-4
has stronger planning performance. Neverthe-
less, there remains considerable scope for fur-
ther improvement when compared to human
performance. Additionally, detailed error anal-
ysis and case studies demonstrate the feasibil-
ity of Tool-Augmented LLMs for daily use, as
well as the primary challenges that future re-
search needs to address.
1 Introduction
Over the past several years, significant progress has
been made in the development of large language
models (LLMs), including GPT-3 (Brown et al.,
2020), Codex (Chen et al., 2021), ChatGPT, and
impressive GPT-4 (Bubeck et al., 2023). These
models exhibit increasingly human-like capabil-
ities, such as powerful conversation, in-context
learning, and code generation across a wide range
of open-domain tasks. Some researchers even be-
∗
Corresponding author.
lieve that LLMs could provide a gateway to Artifi-
cial General Intelligence (Bubeck et al., 2023).
Despite their usefulness, however, LLMs are
still limited as they can only learn from their train-
ing data (Brown et al., 2020). This information
can become outdated and may not be suitable
for all applications (Trivedi et al., 2022; Mialon
et al., 2023). Consequently, there has been a surge
in research aimed at augmenting LLMs with the
ability to use external tools to access up-to-date
information (Izacard et al., 2022), perform com-
putations (Schick et al., 2023), and interact with
third-party services (Liang et al., 2023) in response
to user requests. Tool use has traditionally been
viewed as uniquely human behavior, and the emer-
gence of tool use has been considered a significant
milestone in primate evolution, even serving to
demarcate the appearance of the genus Homo (Am-
brose, 2001). Analogous to the timeline of human
evolution, we believe that at this current juncture,
we must address two key questions: (1) How effec-
tive are current LLMs in using tools? (2) What are
the remaining obstacles for LLMs to use tools?
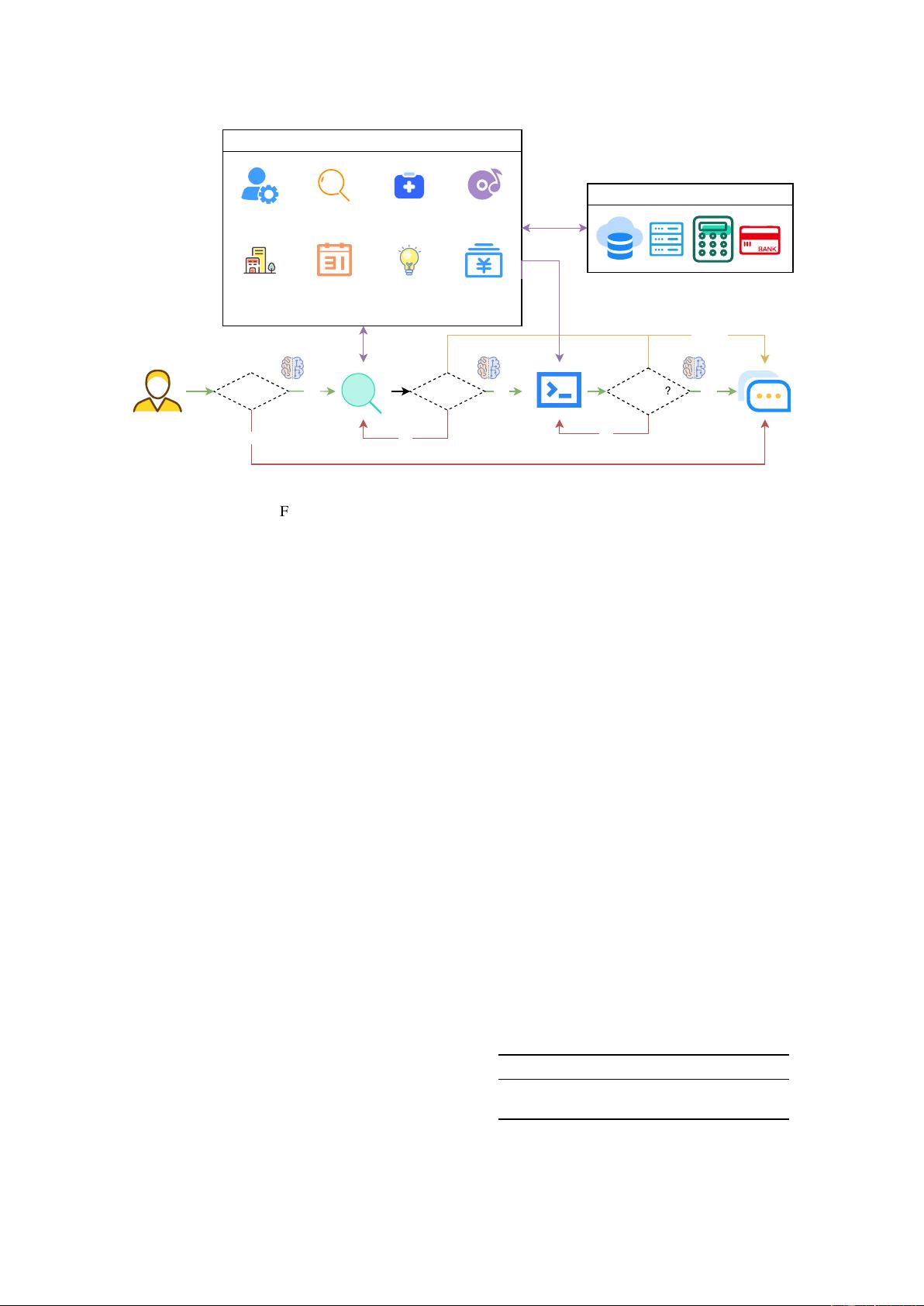
In this paper, we introduce API-Bank, the
first systematic benchmark for evaluating Tool-
Augmented LLMs’ ability to use tools. We imagine
a vision where, with access to a global repository of
tools, LLMs can aid humans in
plan
ning a require-
ment by outlining all the steps necessary to achieve
it. Subsequently, it will
retrieve
the tool pool for
the needed tools and, through possibly multiple
rounds of API
call
s, fulfill the human requirement,
thus becoming truly helpful and all-knowing. To
achieve this goal, we first simulate the real-world
scenario by creating 53 commonly used tools, such
as SearchEngine, PlayMusic, BookHotel, Image-
Caption, and organize them in an API Pool for
LLMs to call. We then propose a complete work-
flow for LLMs to use these tools, which includes
determining whether to call an API, which API to
call, generating an API call, and self-assessing the
arXiv:2304.08244v1 [cs.CL] 14 Apr 2023

剩余11页未读,继续阅读
资源评论


pk_xz123456
- 粉丝: 2304
- 资源: 2398

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 灭火器检测4-YOLO(v5至v9)数据集合集.rar
- 最快的基于thunk,promise的redis客户端,支持所有redis功能 .zip
- 更快地缓存 Wordpress.zip
- 版本控制系统中Git的安装与配置指南
- Building Resilient Architectures on AWS.pdf
- 扫描 Redis RDB 以查找大键 分析redis的RDB文件,输出big key报告.zip
- 我使用 redis 的工具.zip
- 灭火器检测39-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord、VOC数据集合集.rar
- 异步并发哈希图 与 Redis 不同,它支持多线程和高级数据结构.zip
- 常见有用的服务器配置,包括nginx,mysql,tomcat,redis.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


