

SELF-INSTRUCT: Aligning Language Model
with Self Generated Instructions
Yizhong Wang
♣
Yeganeh Kordi
♢
Swaroop Mishra
♡
Alisa Liu
♣
Noah A. Smith
♣+
Daniel Khashabi
♠
Hannaneh Hajishirzi
♣+
♣
University of Washington
♢
Tehran Polytechnic
♡
Arizona State University
♠
Johns Hopkins University
+
Allen Institute for AI
yizhongw@cs.washington.edu
Abstract
Large “instruction-tuned” language models
(finetuned to respond to instructions) have
demonstrated a remarkable ability to gener-
alize zero-shot to new tasks. Nevertheless,
they depend heavily on human-written instruc-
tion data that is limited in quantity, diver-
sity, and creativity, therefore hindering the
generality of the tuned model. We intro-
duce SELF-INSTRUCT, a framework for im-
proving the instruction-following capabilities
of pretrained language models by bootstrap-
ping off its own generations. Our pipeline
generates instruction, input, and output sam-
ples from a language model, then prunes
them before using them to finetune the orig-
inal model. Applying our method to vanilla
GPT3, we demonstrate a 33% absolute im-
provement over the original model on SUPER-
NATURALINSTRUCTIONS, on par with the per-
formance of InstructGPT
001
1
, which is trained
with private user data and human annotations.
For further evaluation, we curate a set of
expert-written instructions for novel tasks, and
show through human evaluation that tuning
GPT3 with SELF-INSTRUCT outperforms using
existing public instruction datasets by a large
margin, leaving only a 5% absolute gap behind
InstructGPT
001
. SELF-INSTRUCT provides an
almost annotation-free method for aligning pre-
trained language models with instructions, and
we release our large synthetic dataset to facili-
tate future studies on instruction tuning
2
.
1 Introduction
The recent NLP literature has witnessed a tremen-
dous amount of activity in building models that
1
Unless otherwise specified, our comparisons are with the
text-davinci-001
engine. We focus on this engine since it
is the closest to our experimental setup: supervised fine-tuning
with human demonstrations. The newer engines are more
powerful, though they use more data (e.g., code completion or
latest user queries) or algorithms (e.g., PPO) that are difficult
to compare with.
2
Code and data will be available at
https://github.
com/yizhongw/self-instruct.
can follow natural language instructions (Mishra
et al., 2022; Wei et al., 2022; Sanh et al., 2022;
Wang et al., 2022; Ouyang et al., 2022; Chung et al.,
2022, i.a.). These developments are powered by
two key components: large pre-trained language
models (LM) and human-written instruction data.
PROMPTSOURCE (Bach et al., 2022) and SUPER-
NATURALINSTRUCTIONS (Wang et al., 2022) are
two notable recent datasets that use extensive man-
ual annotation for collecting instructions to con-
struct T
0
(Bach et al., 2022; Sanh et al., 2022) and
T
𝑘
-INSTRUCT (Wang et al., 2022). However, this
process is costly and often suffers limited diver-
sity given that most human generations tend to be
popular NLP tasks, falling short of covering a true
variety of tasks and different ways to describe them.
Given these limitations, continuing to improve the
quality of instruction-tuned models necessitates the
development of alternative approaches for supervis-
ing instruction-tuned models.
In this work, we introduce SELF-INSTRUCT, a
semi-automated process for instruction-tuning a
pretrained LM using instructional signals from the
model itself. The overall process is an iterative
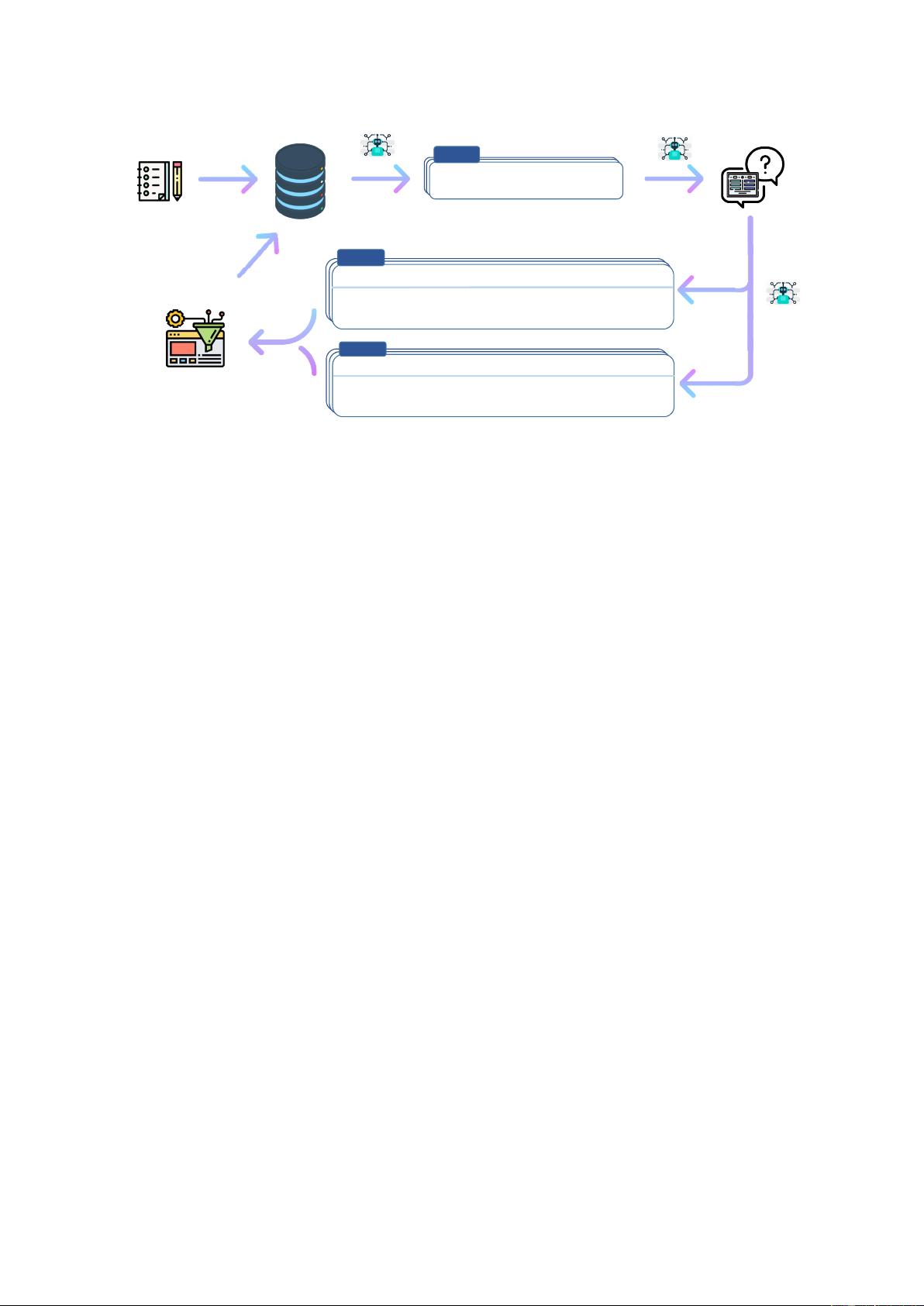
bootstrapping algorithm (see Figure 1), which starts
off with a limited (e.g., 175 in our study) seed set
of manually-written instructions that are used to
guide the overall generation. In the first phase, the
model is prompted to generate instructions for new
tasks. This step leverages the existing collection of
instructions to create more broad-coverage instruc-
tions that define (often new) tasks. Given the newly-
generated set of instructions, the framework also
creates input-output instances for them, which can
be later used for supervising the instruction tuning.
Finally, various measures are used to prune low-
quality and repeated instructions, before adding
them to the task pool. This process can be repeated
for many interactions until reaching a large number
of tasks.
To evaluate SELF-INSTRUCT empirically, we run
arXiv:2212.10560v1 [cs.CL] 20 Dec 2022


剩余18页未读,继续阅读
资源评论


pk_xz123456
- 粉丝: 2812
- 资源: 3980

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- Java项目:在线拍卖系统(java+SpringBoot+Mybaits+Vue+elementui+mysql)
- 立体口罩接料机sw18可编辑全套技术资料100%好用.zip
- DevExpressComponentsBundleSetup-22.2.7.exe
- 计算机科学+计算机组成原理实验
- STM32F407单片机连接W5500以太网芯片实现设置静态IP的方式连接EMQX平台(MQTT平台)
- Java项目:在线拍卖系统(java+SpringBoot+Mybaits+Vue+elementui+mysql)
- 回声法语音信息隐藏信号处理实验MATLAB源代码
- 立体口罩收料包装机sw18可编辑全套技术资料100%好用.zip
- 含光伏的33节点系统接线图PSCAD,可拿来分析,谐波含量很小,容量为550kW,此外还有两个电动汽车充电桩负荷
- Java项目:在线拍卖系统(java+SpringBoot+Mybaits+Vue+elementui+mysql)
- 源码-科学 PDF 文档翻译及双语对照工具
- 计算机视觉中YOLOv8的最新进展及其在多领域中的应用与优化
- 【岗位说明】4S店各岗位说明.doc
- 【岗位说明】4S店岗位职责说明书.xls
- 【岗位说明】4S店岗位工作说明书配件主管.xls
- 【岗位说明】汽车4S店售后经理岗位职责.doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


