

Towards Trustworthy Large Language Models
in Industry Domains
INF-Team
July 04, 2024
Abstract
This report addresses the challenges and strategies for mitigating hal-
lucinations in large language models (LLMs), particularly in domain-
specific applications. Hallucinations refer to the generation of unrealistic
or illogical outputs by LLMs. We explore several methods to reduce hallu-
cinations, including using high-quality domain-specific data for training,
ensuring that the model stays up-to-date with new knowledge, and em-
ploying alignment techniques to ensure that the LLM adheres to human
instructions. A key proposition is the adoption of neuro-symbolic sys-
tems, which combine large-scale deep learning models with symbolic AI.
These systems leverage neural networks for fast “black box” probabilistic
predictions while also enabling “white box” logical reasoning. The inte-
gration of these approaches represents a significant technical direction for
future artificial general intelligence and provides a “gray box” approach to
developing trustworthy LLMs for industrial applications. This dual capa-
bility enhances logical reasoning and improves explainability. In addition,
we detail our efforts to construct domain-specific LLMs for finance and
healthcare. Using anti-hallucination strategies, our finance LLM outper-
forms GPT-4 on the CFA tests, while our healthcare LLM ranks first on
the public MedBench competition leaderboard.
1 Introduction
With the unprecedented development of large language models (LLMs), LLMs
are used to improve communication, generate creative text formats, translate
languages effectively, and even assist scientific research. However, LLMs are
notorious for yielding unreliable outputs, which greatly hinder their applica-
tion in real-world tasks, especially for high-stakes decision-making applications
in industries such as healthcare, asset investment, criminal justice, and other
domains.
One of the key challenges is the “hallucination” problem, whereby LLMs may
output content that seems reasonable but is, in fact, incorrect or illogical. As
an inherent limitation of LLM [51], the hallucination phenomenon is inevitable.
Hallucinations can be divided into two categories [13,14]. One is the factuality
1



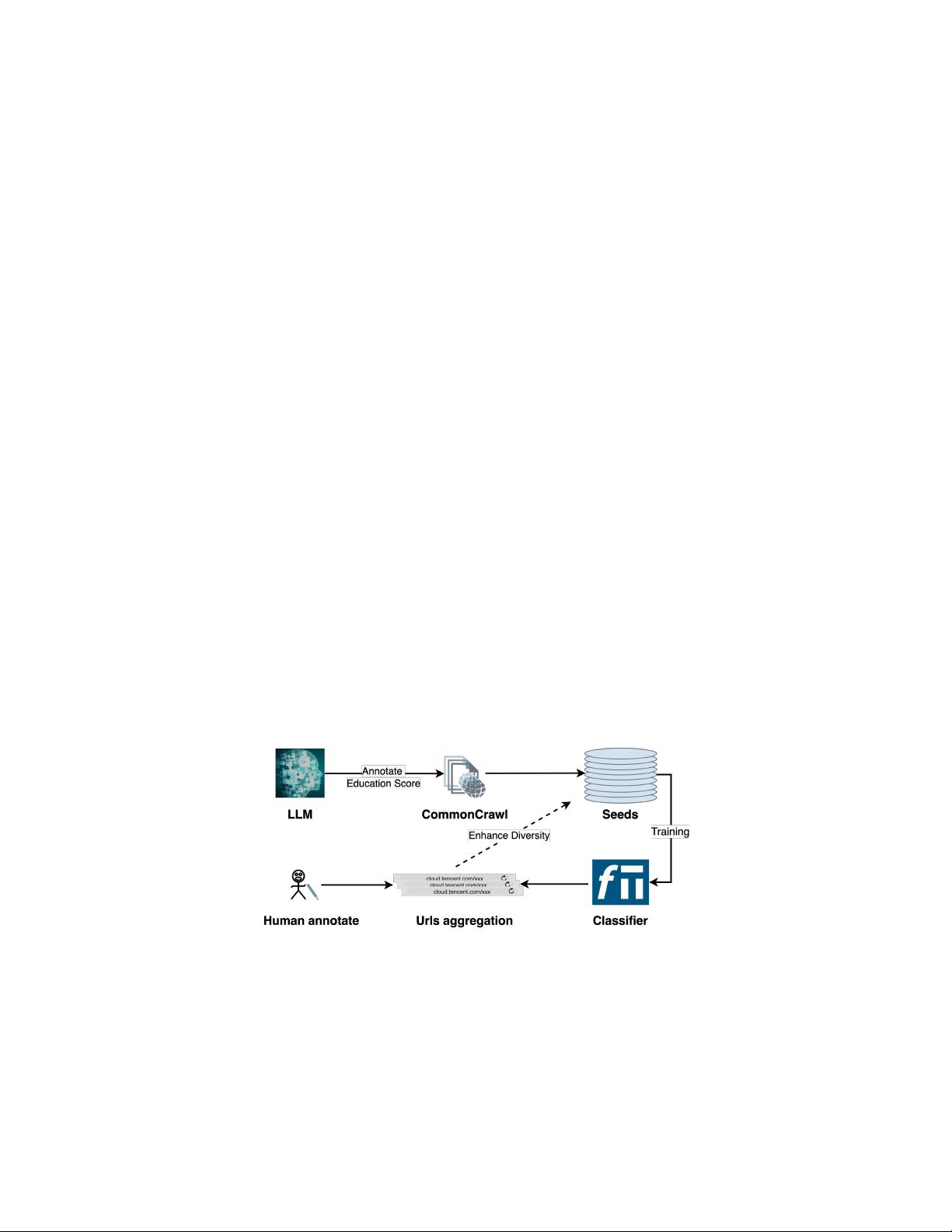
剩余59页未读,继续阅读
资源评论


pk_xz123456
- 粉丝: 2284
- 资源: 2353

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 【java毕业设计】新闻资讯系统源码(springboot+vue+mysql+说明文档+LW).zip
- PromptSource: 自然语言提示的集成开发环境与公共资源库
- 在线英语阅读分级平台:SpringBoot 与 HTML5 + CSS3 框架内的阅读教学蓝图与实施规划
- 利用网页设计语言制作的一款简易打地鼠小游戏
- 步进电机foc+弱磁驱动方案.zip
- 【java毕业设计】志同道合交友网站源码(springboot+vue+mysql+说明文档+LW).zip
- PHP民宿酒店管理系统源码带文字安装教程数据库 MySQL源码类型 WebForm
- 生活の日本語,用于日常生活用语总结
- 制造业数据合集1.0(三份)-最新出炉.zip
- 制造业高质量发展水平测算(原始数据+测算结果)2011-2022年-最新出炉.zip
- 年全国各城市和县域社会经济统计面板数据(2000-2022年)-最新出炉.zip
- 1990-2023年A股上市公司制造业数据大全-最新出炉.zip
- 2007-2023年全国各城市小区二手房挂牌价格明细数据-最新出炉.zip
- 数字经济指数与制造业相关数据集-最新出炉.zip
- axure 图表 资源文件
- 【java毕业设计】医院药品管理系统设计与实现源码(springboot+vue+mysql+说明文档+LW).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


