在IT领域,Python是一种广泛应用的编程语言,尤其在数据分析、文本处理和自动化任务中表现出色。本主题聚焦于一个使用Python编写的词频统计工具,它可以帮助用户快速分析文本文件中的词汇出现频率,从而理解文本内容的核心或者进行进一步的数据挖掘。
词频统计是自然语言处理(NLP)中的基础任务之一,它可以揭示文本的主要主题和模式。Python中有许多库支持这样的功能,如NLTK(Natural Language Toolkit)、spaCy和TextBlob等。这个特定的工具可能就是基于其中的一个或多个库来实现的。
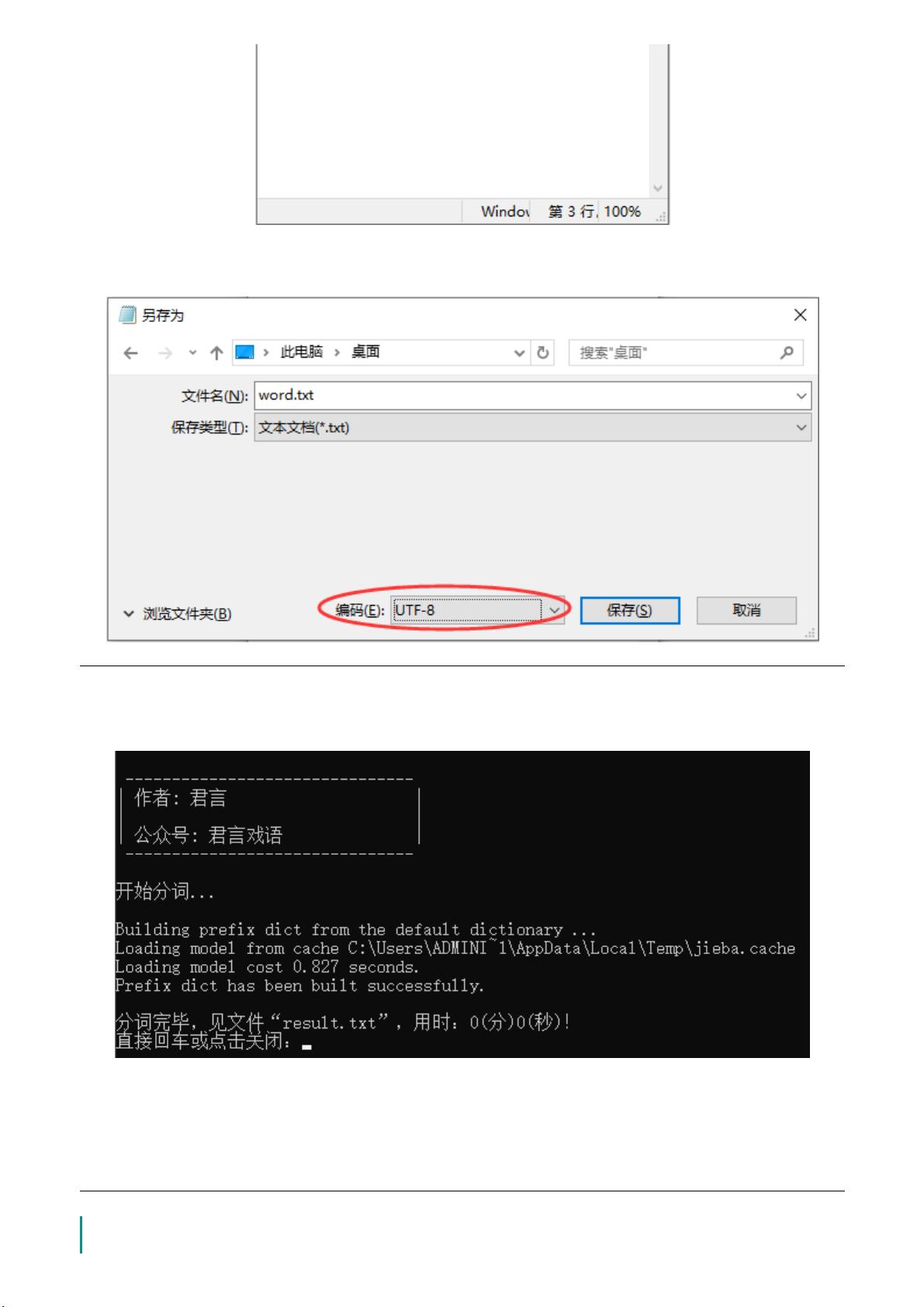
我们来看`WordCount`这个名字,这通常意味着该工具会计算每个单词在文本中的出现次数。在Python中,实现这样的功能通常涉及以下步骤:
1. **读取文件**:使用内置的`open()`函数读取文本文件,如`with open('filename.txt', 'r') as file:`。
2. **预处理**:对文本进行清洗,去除标点符号、数字和其他非字母字符。这可以使用正则表达式库`re`来完成。
3. **分词**:将文本分解成单个单词。NLTK库提供了`word_tokenize()`函数,或者可以简单地通过空格分割字符串。
4. **词频统计**:创建一个字典来存储每个单词及其出现次数,遍历分词后的列表并更新字典。例如,`word_dict[word] = word_dict.get(word, 0) + 1`。
5. **结果展示**:按照出现频率排序并打印或保存结果。
Python的`collections`模块中的`Counter`类也可以简化这个过程,它能自动统计元素的出现次数,如`from collections import Counter; word_counts = Counter(words)`。
此外,如果这个工具包含更高级的功能,可能还会涉及以下方面:
- **停用词移除**:排除像“的”、“和”这类常见但对主题识别帮助不大的词语。
- **词形还原**:使用如NLTK的`WordNetLemmatizer`将动词、名词等还原到基本形式。
- **n-gram分析**:统计连续出现的n个词的组合频率,提供更丰富的语义信息。
- **TF-IDF**:计算词频与文档频率的比值,用于评估单词在文档中的重要性。
- **可视化**:使用matplotlib或seaborn等库将结果以图表的形式展示出来,便于理解。
对于初学者,理解并编写这样的词频统计工具是学习Python和NLP的好方法。对于专业人士,这样的工具则可以作为数据预处理和文本分析的起点,为进一步的文本挖掘和机器学习任务奠定基础。通过掌握Python的这些基础知识和库,你可以构建出功能强大的文本分析应用,满足各种实际需求。

 WordCount.rar (6个子文件)
WordCount.rar (6个子文件)  WordCount
WordCount  flag.txt 0B
flag.txt 0B WordCount.exe 24.65MB
WordCount.exe 24.65MB 说明.pdf 156KB
说明.pdf 156KB












- 1
- 2
- 3
前往页