### Presto在京东云的应用实践
#### Presto介绍
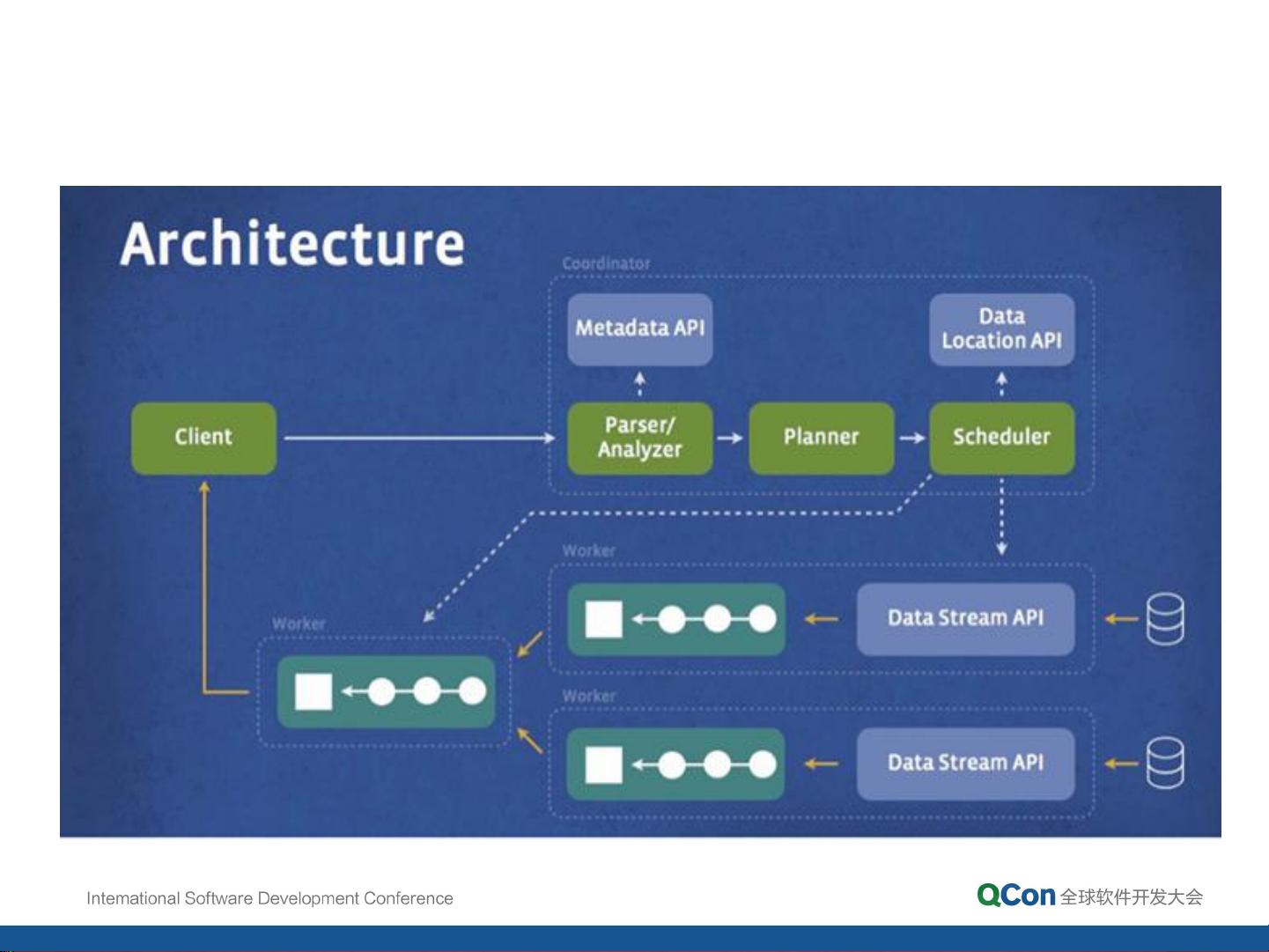
Presto是一款开源的分布式SQL查询引擎,由Facebook于2012年启动开发,并于2013年正式开源。它能够快速处理大规模数据集(从GB级到PB级)的查询任务,支持多种数据源(如Hive、Cassandra、MongoDB等)以及标准SQL语法,适用于交互式数据分析场景。Presto具有高度可扩展性,能够实现跨数据源查询,是大数据分析领域的重要工具之一。
#### Presto在京东的应用实践历程
京东自引入Presto以来,对其进行了持续的改进与优化,使其在京东内部生根发芽并逐渐成长壮大。具体来说:
- **早期阶段**:京东团队基于Presto-0.124版本进行了初步的测试与部署。在测试环境中,采用了13个节点,每个节点配备了20GB内存和32个核心。此外,还使用了Hadoop 2.5.0-cdh5.3.0和Hive-0.13.1版本作为底层技术支持。测试使用的是TPC-DS基准测试案例,数据量为100GB的TXT格式,全部转换为ORC格式进行测试。
- **发展阶段**:随着Presto项目的深入发展,京东连续开源了两个Presto-JD版本,并积极参与到了Presto开源社区中。通过不断的技术积累与优化,Presto在京东内部的应用范围不断扩大,最终成功应用于京东云平台上,为更多的用户提供服务。
#### Presto在京东云的成长壮大
- **数据源的丰富与优化**:京东针对Presto进行了多项改进,包括丰富Hive连接器的语法支持、新增Oracle和SQL Server等关系型数据库的连接器,并且实现了对MySQL分库分表的支持。此外,还优化了关系型数据库条件下的下推逻辑,增加了对更多字段类型的支持以及in/notin/between等操作的支持。
- **安全访问集群**:为了确保集群的安全性,京东实施了严格的身份验证及权限控制机制。例如,访问Presto集群需要提供用户名及密码;同时,通过Kerberos认证来确保Presto对HDFS及Hive Metastore的安全访问。此外,还提供了细粒度的权限控制,允许对数据库和表进行精确的操作权限设置。
- **Presto on Yarn**:京东还实现了Presto on Yarn的功能,通过Slider组件向Yarn申请启动Presto集群。这不仅提高了资源利用率,还增强了系统的容错能力,比如在NodeManager宕机或AppMaster/Coordinator容器关闭时能够自动恢复。同时,还支持了Kerberos认证,并根据集群规模自动调整优化参数。
- **用户定义函数(UDF)支持**:为了提高灵活性和安全性,京东增强了Presto对UDF的支持。支持动态加载UDF,允许不同用户拥有同名函数的同时保证了系统的安全性。此外,还新增了dropudf语法,以便于用户删除自定义的函数。
#### Presto在京东云的具体应用场景
- **大数据量实时查询**:Presto能够在短时间内处理大量的数据查询请求,支持实时数据查询的需求。
- **Ad-hoc即席查询**:用户可以随时提出查询需求,Presto能够快速响应并返回结果。
- **数据抽取与导入**:利用Presto的高效性能,可以快速地完成大量数据的抽取与导入工作。
- **定制化报表**:结合Presto的灵活性,可以方便地创建各种定制化的报表。
- **精准营销**:通过对海量用户数据的分析,实现更精准的营销策略制定。
#### 结合计算框架的集成
京东云集成了Presto计算引擎的计算框架,称为“数据计算平台”(Data Computing Service,简称DCS)。该平台通过不同的分布式计算框架满足即席查询、批量离线处理等多种场景的需求,提供面向多租户、完全托管的海量数据处理分析服务。这种集成不仅提升了数据处理效率,也为京东云用户提供了更加灵活、高效的服务体验。
通过上述内容可以看出,京东云在Presto的应用实践中积累了丰富的经验和技术优势,为大数据分析领域的发展做出了贡献。