

1
深入浅出谈 CUDA
Hotball
CUDA
是
NVIDIA
的
GPGPU
模型,它使用
C
语言为基础,可以直接以大多数人熟悉的
C
语言,写出在显示芯片上执行的程序,而不需要去学习特定的显示芯片的指令或是特殊的结
构。
”
CUDA是什么?能吃吗?
编者注:
NVIDIA
的
GeFoce 8800GTX
发布后,它的通用计算架构
CUDA
经过一年多的推广后,
现在已经在有相当多的论文发表,在商业应用软件等方面也初步出现了视频编解码、金融、
地质勘探、科学计算等领域的产品,是时候让我们对其作更深一步的了解。为了让大家更容
易了解
CUDA
,我们征得
Hotball
的本人同意,发表他最近亲自撰写的本文。这篇文章的特点是
深入浅出,也包含了
hotball
本人编写一些简单
CUDA
程序的亲身体验,对于希望了解
CUDA
的
读者来说是非常不错的入门文章,
PCINLIFE
对本文的发表没有作任何的删减,主要是把一些
台湾的词汇转换成大陆的词汇以及作了若干
"
编者注
"
的注释。
现代的显示芯片已经具有高度的可程序化能力,由于显示芯片通常具有相当高的内存带宽,
以及大量的执行单元,因此开始有利用显示芯片来帮助进行一些计算工作的想法,即 GPGPU。
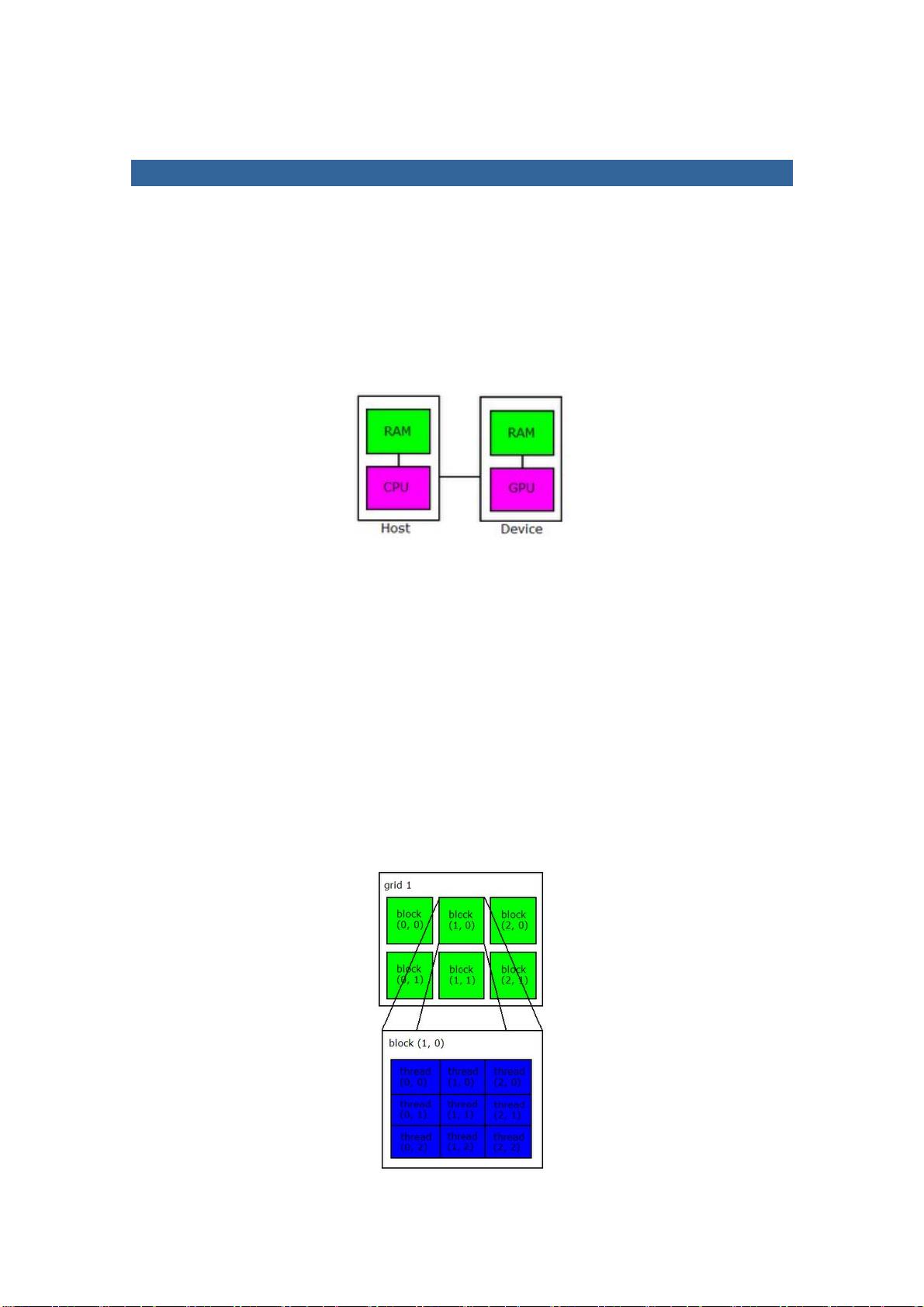
CUDA 即是 NVIDIA 的 GPGPU 模型。
NVIDIA 的新一代显示芯片,包括 GeForce 8 系列及更新的显示芯片都支持 CUDA。NVIDIA
免费提供 CUDA 的开发工具(包括 Windows 版本和 Linux 版本)、程序范例、文件等等,
可以在
CUDA Zone 下载。
GPGPU 的优缺点
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个好处:
1. 显示芯片通常具有更大的内存带宽。例如,NVIDIA 的 GeForce 8800GTX 具有超过
50GB/s 的内存带宽,而目前高阶 CPU 的内存带宽则在 10GB/s 左右。
2. 显示芯片具有更大量的执行单元。例如 GeForce 8800GTX 具有 128 个 "stream
processors",频率为 1.35GHz。CPU 频率通常较高,但是执行单元的数目则要少得多。
3. 和高阶 CPU 相比,显卡的价格较为低廉。例如目前一张 GeForce 8800GT 包括
512MB 内存的价格,和一颗 2.4GHz 四核心 CPU 的价格相若。
当然,使用显示芯片也有它的一些缺点:
1. 显示芯片的运算单元数量很多,因此对于不能高度并行化的工作,所能带来的帮助就
不大。
2. 显示芯片目前通常只支持 32 bits 浮点数,且多半不能完全支持 IEEE 754 规格, 有
些运算的精确度可能较低。目前许多显示芯片并没有分开的整数运算单元,因此整数
运算的效率较差。
3. 显示芯片通常不具有分支预测等复杂的流程控制单元,因此对于具有高度分支的程序,
效率会比较差。
4. 目前 GPGPU 的程序模型仍不成熟,也还没有公认的标准。例如 NVIDIA 和
AMD/ATI 就有各自不同的程序模型。


剩余30页未读,继续阅读
资源评论













