DERT:论文详细翻译
版权申诉


@[toc]
摘要
https://arxiv.org/pdf/2005.12872.pdf
本文提出一种新方法,将目标检测视为直接的集合预测问题。该方法简化了检测管道,有效地消除了对
许多手工设计组件的需要,如非最大抑制程序或锚点生成,这些组件显式编码了我们关于任务的先验知
识。新框架称为检测TRansformer或DETR,其主要成分是基于集合的全局损失,通过二分图匹配强制进
行独特的预测,以及TRansformer编码器-解码器架构。给定一个固定的小集合的学习对象查询,DETR
对对象和全局图像上下文的关系进行推理,以直接并行输出最终的预测集。与许多其他现代检测器不
同,新模型在概念上很简单,不需要专门的库。在具有挑战性的COCO目标检测数据集上,DETR展示了
与完善的、高度优化的Faster RCNN基线相当的准确性和运行时间性能。此外,DETR易于推广,以统一
的方式产生全景分割。实验表明,它明显优于有竞争力的基线。训练代码和预训练模型可以在https://git
hub.com/facebookresearch/detr上找到。
1、简介
目标检测的目标是预测每个感兴趣物体的一组边界框和类别标签。现代的检测器通过在大量的提议集合
[37,5]、锚点[23]或窗口中心[53,46]上定义代理回归和分类问题,以间接的方式解决这一集合预测任务。
它们的性能受到以下因素的显著影响:瓦解近似重复预测的后处理步骤、锚集的设计以及将目标框分配给
锚[52]的启发式方法。为简化这些管道,本文提出一种直接集预测方法来绕过代理任务。这种端到端哲
学在复杂的结构化预测任务(如机器翻译或语音识别)中取得了重大进展,但在目标检测方面还没有:以前
的尝试[43,16,4,39]要么添加了其他形式的先验知识,要么没有被证明在具有挑战性的基准上与强大的基
线具有竞争力。本文旨在弥合这一差距。
通过将目标检测视为直接的集合预测问题,简化了训练管道。采用基于transformer的编码器-解码器架
构[47],这是一种流行的序列预测架构。transformer的自注意力机制显式地对序列中元素之间的所有成
对交互进行了建模,使这些架构特别适合集合预测的特定约束,如删除重复的预测。
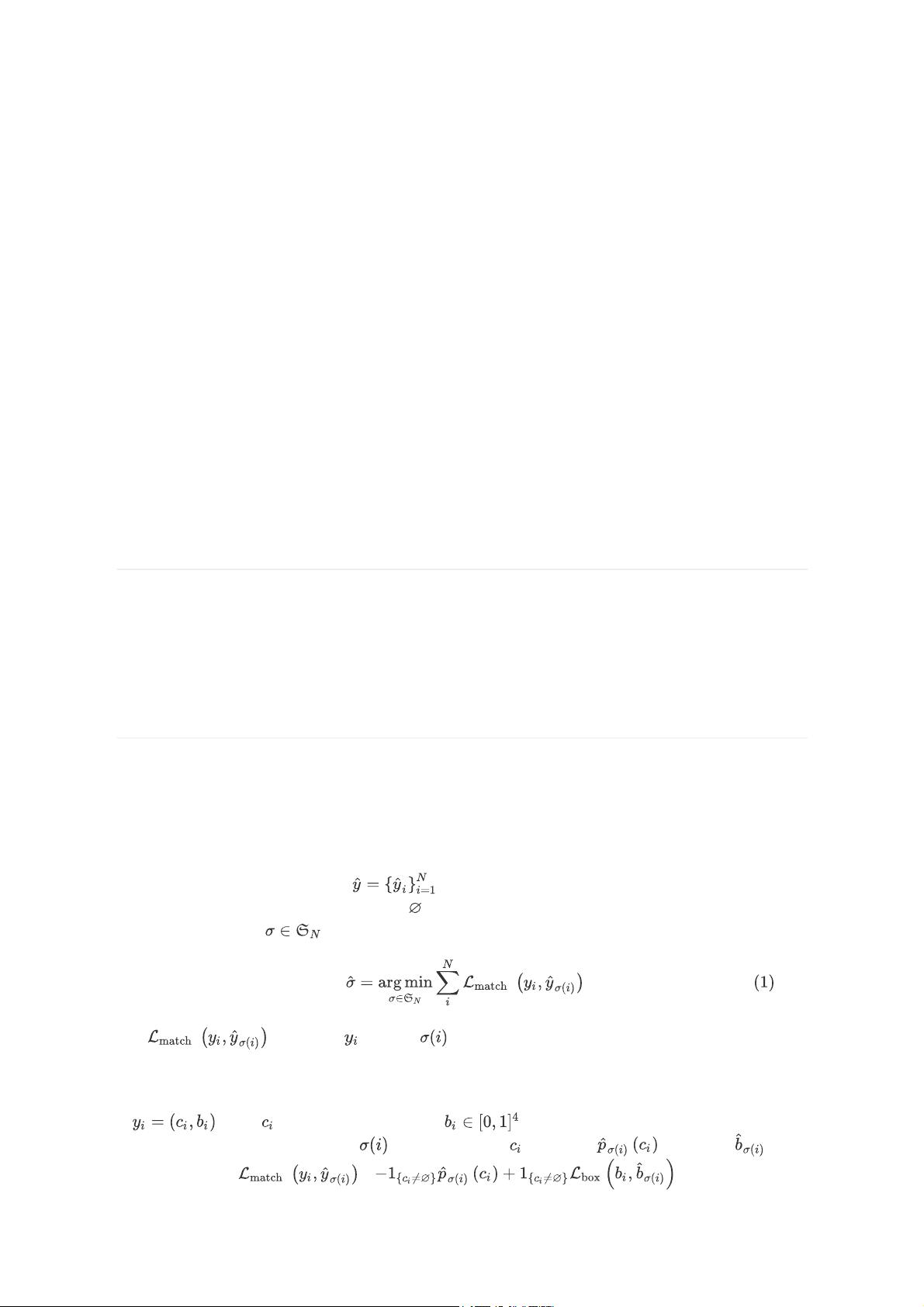
我们的检测TRansformer (DETR,见图1)一次预测所有对象,并使用一组损失函数进行端到端训练,该
函数在预测对象和真实对象之间执行二部匹配。DETR通过删除多个手工设计的组件来简化检测流程,这
些组件编码先验知识,如空间锚定或非最大抑制。与大多数现有的检测方法不同,DETR不需要任何自定
义层,因此可以在包含标准CNN和Transformer类的任何框架中轻松复制。1 .
与之前大多数直接集合预测工作相比,DETR的主要特征是将二部匹配损失和Transformer与(非自回归)
并行解码结合在一起[29,12,10,8]。相比之下,之前的工作主要集中在rnn的自回归解码
[43,41,30,36,42]。我们的匹配损失函数唯一地将预测分配给一个基本真值对象,并且对预测对象的排列
是不变的,因此我们可以并行地发射它们。
剩余15页未读,继续阅读
资源评论

 星云雨沫2023-09-30这个资源对我启发很大,受益匪浅,学到了很多,谢谢分享~
星云雨沫2023-09-30这个资源对我启发很大,受益匪浅,学到了很多,谢谢分享~


AI浩
- 粉丝: 14w+
- 资源: 216

下载权益

C知道特权

VIP文章

课程特权
开通VIP











