Apache Spark 是一种强大的分布式数据处理框架,它使用了多种优化技术来高效地处理大数据。在Spark中,调度器(Scheduler)是整个系统的核心组件之一,负责管理和调度任务(task)以及执行过程中的各类资源分配。本文档将深入探讨Spark调度器的原理,从其架构设计到实际的调度过程,帮助读者对Spark的调度机制有更深入的理解。
Spark采用了stage-oriented scheduling(基于阶段的调度)策略,将整个任务分成多个阶段(Stage),每个阶段包含了多个任务集合(TaskSet)。在Spark内部,提交的任务首先被划分为一系列的RDD(弹性分布式数据集)操作,这些操作根据依赖关系被组织成一个有向无环图(DAG)。每个RDD操作可以依赖于前一个操作的结果,形成一个 DAG 形状的数据流。
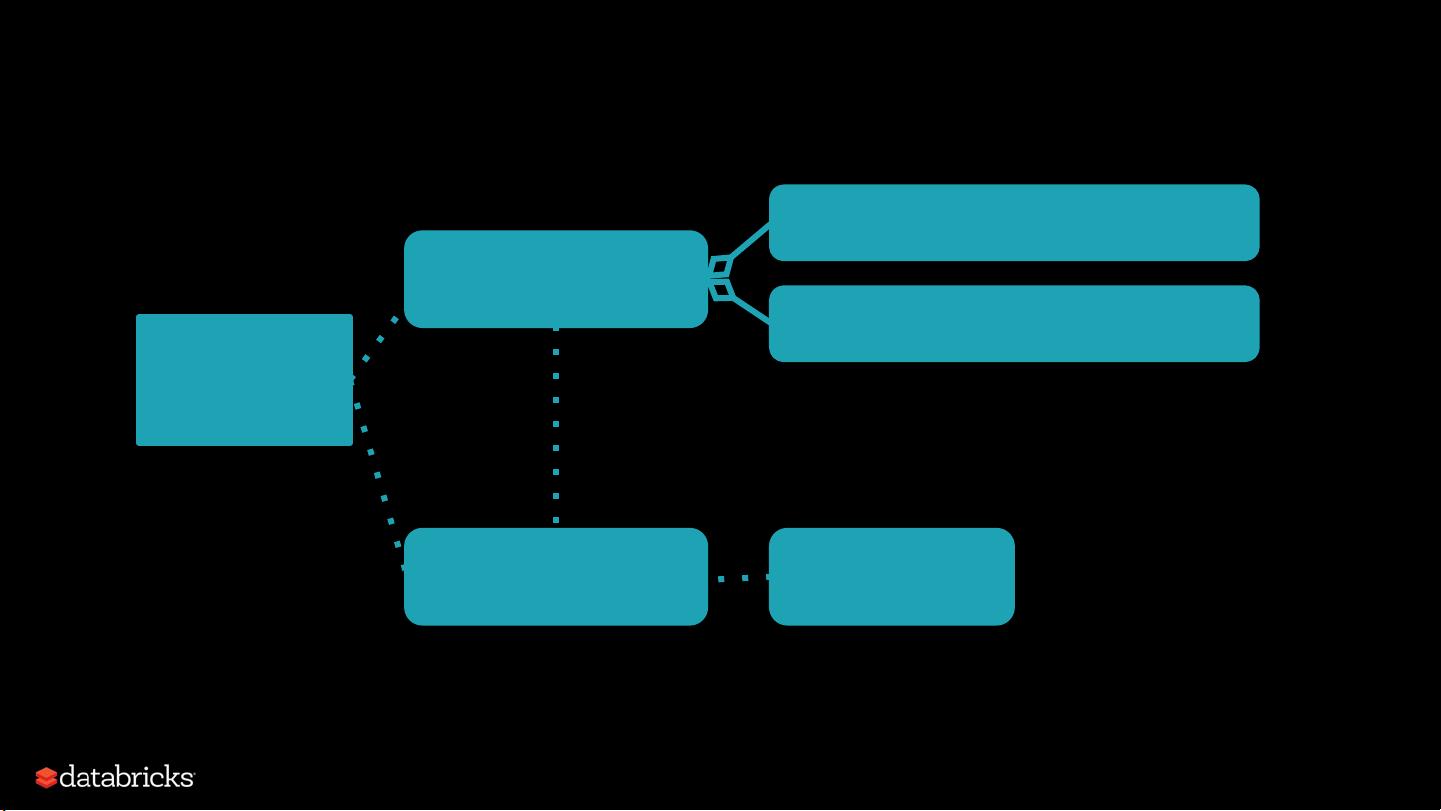
DAGScheduler 负责将这个DAG转化为一系列的stage,每个stage包含了一系列具有相同数据分区(partition)的任务。DAGScheduler计算出一个DAG的stage图,跟踪已经计算出来的RDD/Stage结果,并找到最小化的任务集来运行整个作业。DAGScheduler的职责是实现stage的划分,计算提交作业的stage DAG,跟踪已经物化的RDD/Stage结果,并找到运行作业的最小化任务集。
每个stage都会生成多个TaskSet,对应着需要计算的特定stage的多个分区。DAGScheduler会为每个Stage生成对应的TaskSet,其中TaskSet包含了计算特定stage缺失分区所需的一组任务。
在任务分配方面,Spark的TaskScheduler负责将DAGScheduler提交的TaskSet任务集合调度到Worker节点上执行。TaskScheduler与SchedulerBackend一起工作,任务调度器通过SchedulerBackend监控任务的执行状态,并且返回事件到DAGScheduler,例如作业提交、作业取消、Map阶段提交、阶段取消和作业完成事件等。
Spark的调度器后端(SchedulerBackend)是集群管理器(Cluster Manager)和调度器之间的抽象层。它主要负责与集群管理器交互,以分配执行任务所需的资源,如CPU和内存。在Spark中,有CoarseGrainedSchedulerBackend和LocalSchedulerBackend两种调度器后端。CoarseGrainedSchedulerBackend用于集群模式,负责与集群管理器通信,分配任务到不同的Worker节点上。LocalSchedulerBackend用于本地模式,在单机上运行任务。
Spark的调度过程包括了任务的创建、分发、监控和资源的管理等。当Spark作业开始运行时,首先初始化SparkContext,它是整个Spark作业的入口点。SparkContext创建DAGScheduler、TaskScheduler和SchedulerBackend等组件。一旦作业被提交,DAGScheduler计算出作业的DAG,并将stage DAG传递给TaskScheduler,TaskScheduler再将任务分配到各个Worker节点上。
在任务调度的过程中,Spark调度器还支持容错处理。例如,如果某个TaskSet失败,DAGScheduler可以重新计算依赖于该失败TaskSet的后续Stage,并将它们提交给TaskScheduler。DAGScheduler还能够追踪失败的任务集,并将失败的任务集标记为Zombie TaskSet(僵尸任务集),并尝试重新调度计算。
Spark的调度器设计为灵活和高效的分布式数据处理提供了坚实的基础。通过DAGScheduler和TaskScheduler的协同工作,Spark可以有效地将大数据处理工作分配给集群中的各个节点,同时利用集群资源进行高效的任务执行。不仅如此,Spark的调度器还内置了容错机制,确保了数据处理任务在遇到错误时,能够自动重试和恢复,从而大大提升了大数据处理的可靠性和稳定性。