
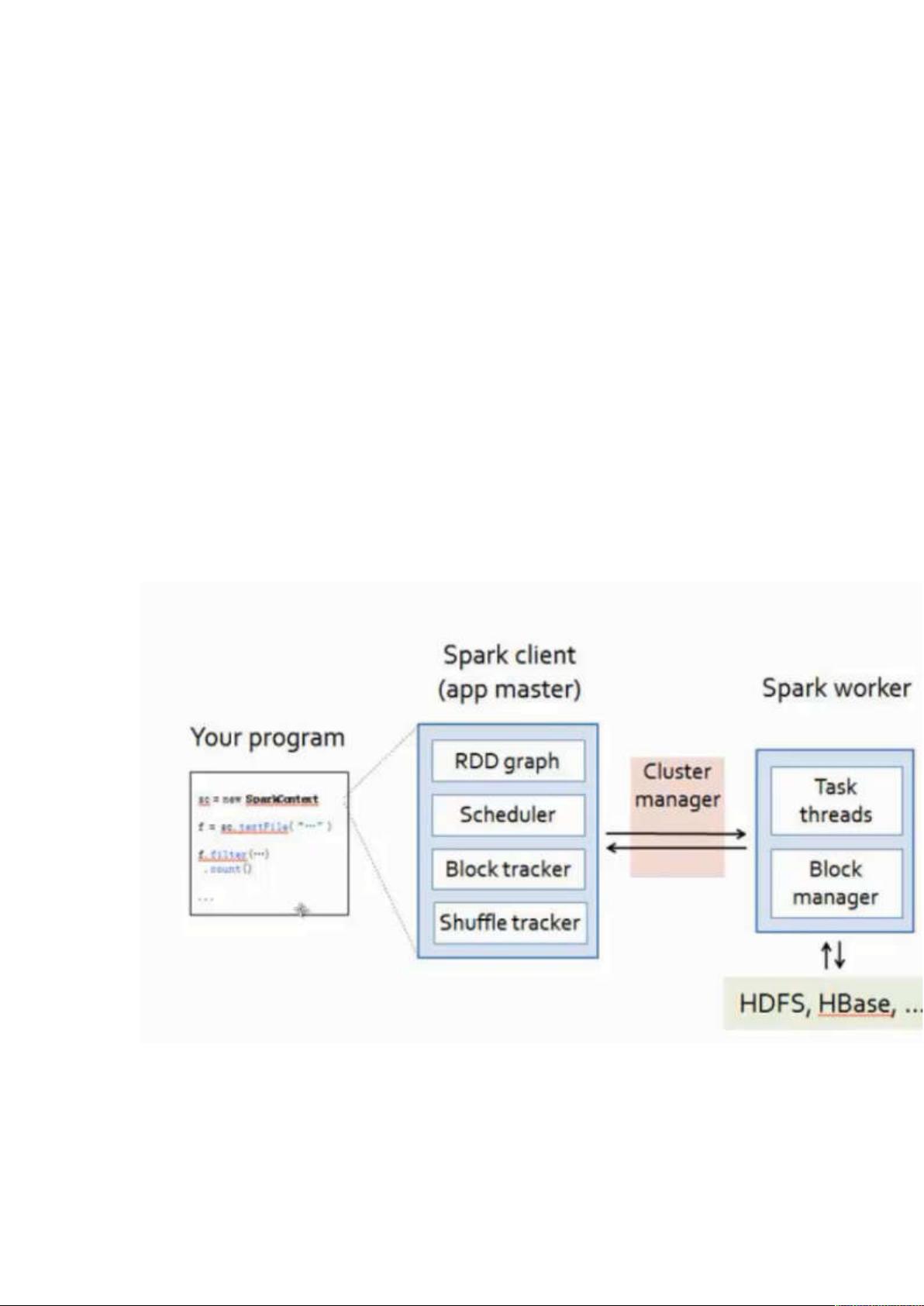
一:spark 运行原理
Spark 是一个分布式(很多机器,每个机器负责一部部分数据),基于内存(内存不够可
以放在磁盘中),特别适合于迭代计算的计算框架。
基于内存(在一些情况下也会基于磁盘),优先考虑放入内存中,有更好的数据本地性。
如果内存中放不完的话,会考虑将数据 或者部分数据放入磁盘中。
擅长迭代式计算是 spark 的真正精髓。基于磁盘的迭代计算比 hadoop 快 10x 倍,基于
内存的迭代计算比 hadoop 快 100x 倍。
Driver 端, 就是写好的本地程序提交到特定的机器上。
Spark 开发语言说明
国内开发程序 spark 程序 有些使用 java 开发,
1. 人才问题 java 开发人员很多(scala 开发人员较少)
2. 整合更加容易
3. 维护更加容易
4. 但是要更好的掌握 spark 还是需要用 scala 写 spark,因为 java 写起来太繁琐了而且有些
功能实现起来很困难。
Spark 组件
处理数据来源: hdfs 、hbase、hive 、db。
Hivee 包括数据仓库和计算引擎,sparksql 只能取代 hive 的计算引擎。
处理数据输出: hdfs 、hbase、hive 、db、s3(云)。还可以直接输出给客户端(dirver 端)。
剩余7页未读,继续阅读
资源评论













