机器学习2022学习笔记(课上)
需积分: 0 92 浏览量
2023-02-19
15:11:38
上传
评论 1
收藏 1.7MB PDF 举报


智能2101张世博(markdown笔记导出无法显示运行结果)
第一章 机器学习概述
机器学习的基本概念
机器学习:机器学习是一种计算机程序,它可以让系统在未经人为编辑的情况下,具有经验(数
据)中自动学习并自我改进的能力
ps:机器学习是人工智能的一个子分类
相关知识
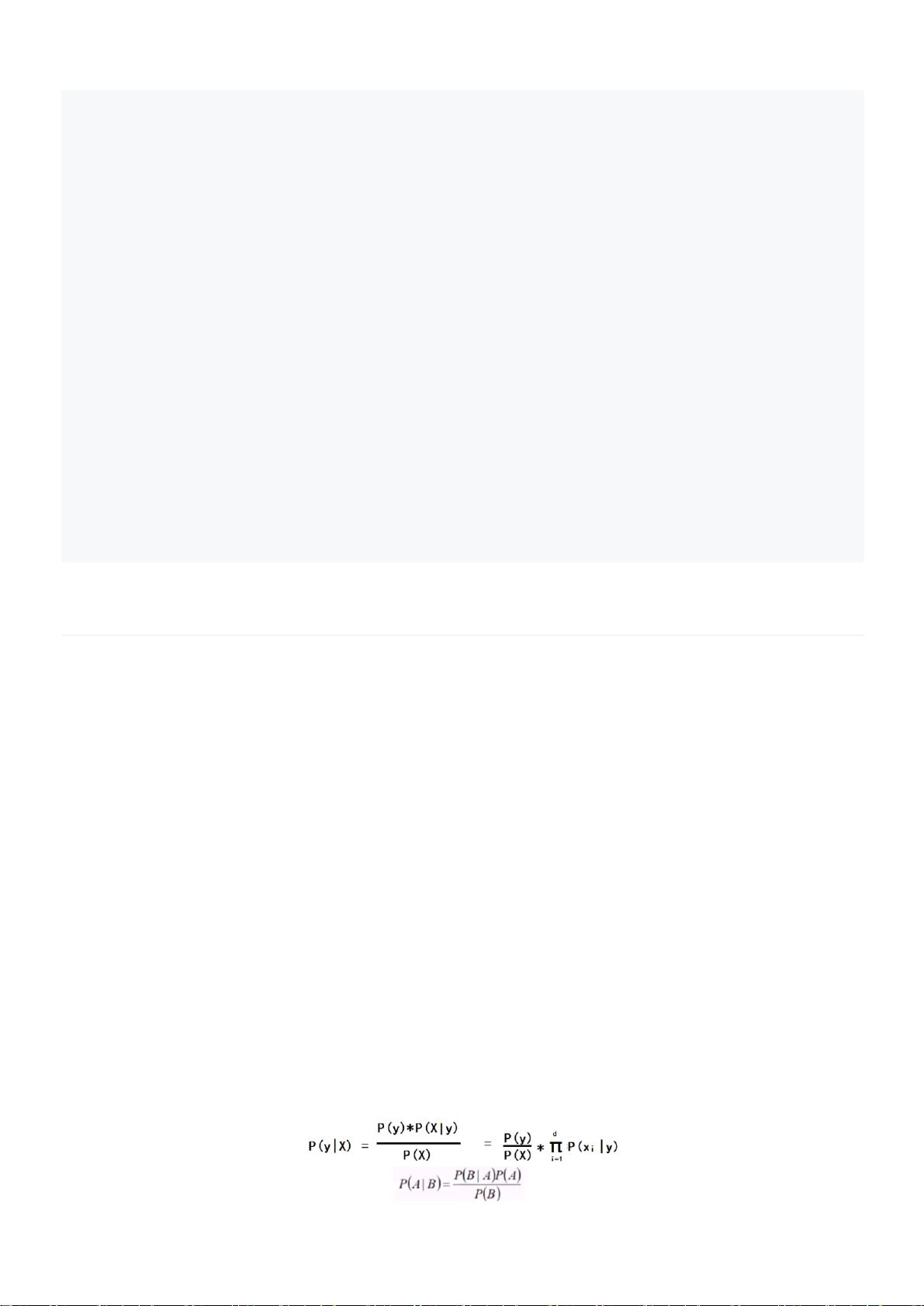
监督学习和无(非)监督学习
监督学习是通过现有训练数据集(以下简称训练集)进行建模,再用模型对新的数据样本进行分类
或者回归分析的机器学习算法。
无监督学习则是在没有训练集的情况下,对没有标签的数据进行分析并建立合适的模型,以便给出
问题解决方案的方法。
分类和回归
分类( classification )和回归( regression )都是监督学习中的概念。分类预测样本属于哪个
类别,而回归预测样本目标字段的数值。
数据集和特征
数据集( dataset )是预测系统的原材料,用于训练机器学习模型的历史数据,数据集由若干条数
据组成,而每条数据又包含若干个特征( feature )。特征是描述数据集中每个样本的属性,有的
时候也袯称为“字段”。
特征工程
特征工程是创建预测模型之前的过程,在这个过程中我们将对数据的特征进行分析清理和结构化。
过拟合和欠拟合
当学习器把训练样本学的“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在
样本都会具有的一般性质,这样就会导致泛化性能下降,这种现象称为过拟合。
欠拟合是指对训练样本的一般性质尚未学好。在训练集及测试集上的表现都不好。

剩余17页未读,继续阅读
资源评论













