
CS 224D: Deep Learning for NLP
1
1
Course Instructor: Richard Socher
Lecture Notes: Part II
2
2
Author: Rohit Mundra, Richard Socher
Spring 2015
Keyphrases: Intrinsic and extrinsic evaluations. Effect of hyper-
parameters on analogy evaluation tasks. Correlation of human
judgment with word vector distances. Dealing with ambiguity in
word using contexts. Window classification.
This set of notes extends our discussion of word vectors (inter-
changeably called word embeddings) by seeing how they can be
evaluated intrinsically and extrinsically. As we proceed, we discuss
the example of word analogies as an intrinsic evaluation technique
and how it can be used to tune word embedding techniques. We then
discuss training model weights/parameters and word vectors for ex-
trinsic tasks. Lastly we motivate artificial neural networks as a class
of models for natural language processing tasks.
1 Evaluation of Word Vectors
So far, we have discussed methods such as the Word2Vec and GloVe
methods to train and discover latent vector representations of natural
language words in a semantic space. In this section, we discuss how
we can quantitatively evaluate the quality of word vectors produced
by such techniques.
1.1 Intrinsic Evaluation
Intrinsic evaluation of word vectors is the evaluation of a set of word
vectors generated by an embedding technique (such as Word2Vec or
GloVe) on specific intermediate subtasks (such as analogy comple-
tion). These subtasks are typically simple and fast to compute and
thereby allow us to help understand the system used to generate the
word vectors. An intrinsic evaluation should typically return to us a
number that indicates the performance of those word vectors on the
evaluation subtask.
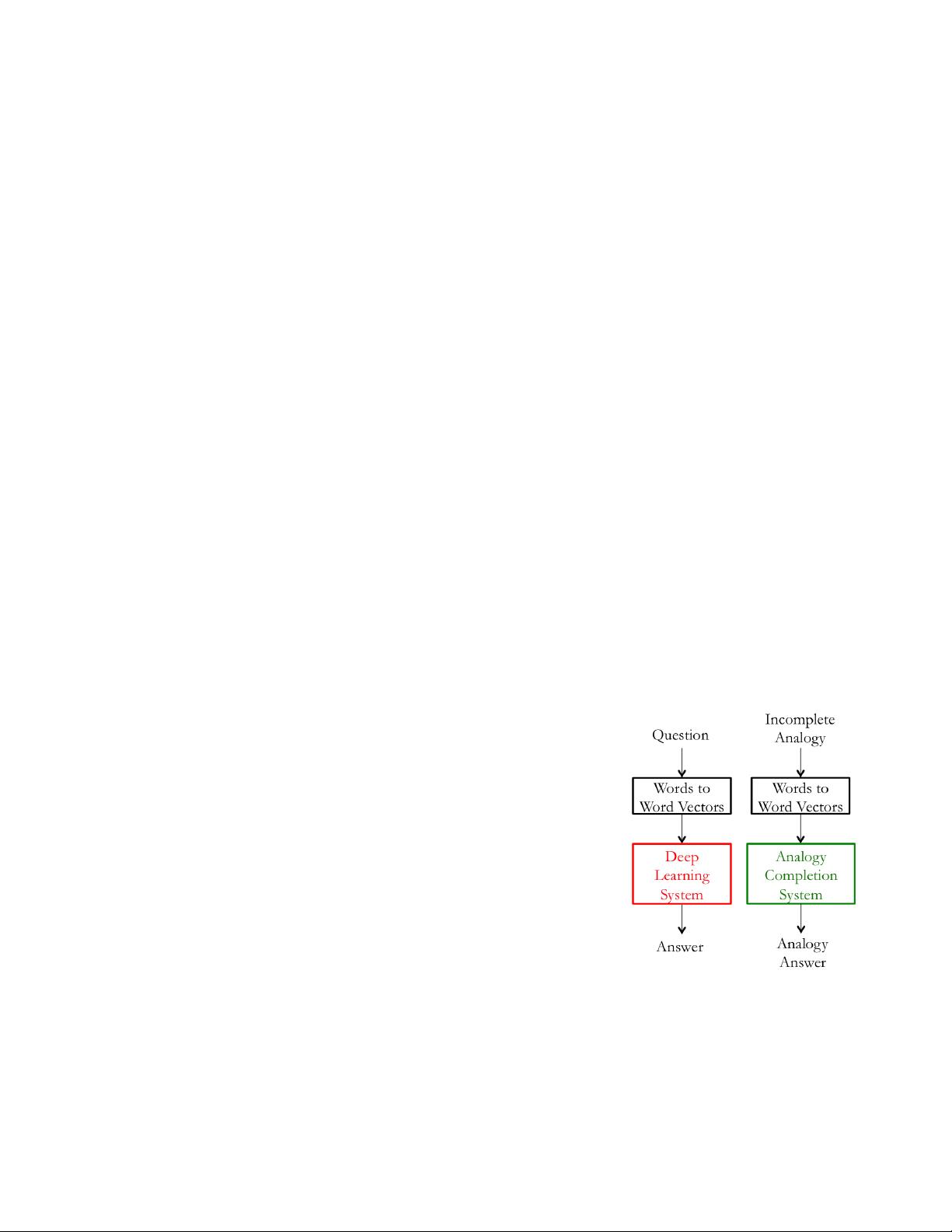
Figure 1: The left subsystem (red)
being expensive to train is modified by
substituting with a simpler subsystem
(green) for intrinsic evaluation.
Motivation: Let us consider an example where our final goal
is to create a question answering system which uses word vectors
as inputs. One approach of doing so would be to train a machine
learning system that:
1. Takes words as inputs
2. Converts them to word vectors

剩余10页未读,继续阅读
资源评论


Nicoder
- 粉丝: 70
- 资源: 6









最新资源
- VMware-Workstation-17.6.2-24409262.x86-64.bundle.tar
- 基于ssm的莲湖小区疫情物资管理系统源码(java毕业设计完整源码).zip
- Screenshot_20241230_124309_com.tencent.tmgp.pubgmhd.jpg
- 不同颜色球体检测10-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- ABB机器人二次开发 C#读取和写入数据,可以获取点位信息及写入点位信息 自己写的ABB机器人类,机器人常规操作功能都有,非常适合进行二次开发
- 基于ssm的面向社区健康服务的医疗平台源码(java毕业设计完整源码+LW).zip
- 基于ssm的明星周边在线购物商城源码(java毕业设计完整源码).zip
- VMware-Workstation-16.2.5-20904516.x86-64.bundle.tar
- 新能源汽车车载双向OBC,PFC,LLC,V2G 双向 充电桩 电动汽车 车载充电机 充放电机 MATLAB仿真模型 : (1)基于V2G技术的双向AC DC、DC DC充放电机MATLAB仿真模型
- 基于ssm的农产品销售系统源码(java毕业设计完整源码+LW).zip
- 固高GTS运动控制卡,C#语言三轴点胶机样本程序源代码,使用 的是固高GTS-800 8轴运动控制卡 资料齐全,3轴点胶机样本程序,还有操作手册及各种C#事例程序,适合自己参照做二次开发,GTS-4
- VMware-Workstation-15.5.7-17171714.x86-64.bundle.tar
- 一种手机电池粘胶机sw18可编辑全套技术资料100%好用.zip
- 基于Python控制台的二手房预测可视化分析
- 高校教材订购系统的数据库设计方案和技术实现要点
- 光伏并网逆变器资料,包含原理图,pcb,源码以及元器件明细表 如下: 1) 功率接口板原理图和pcb,元器件明细表 2) 主控DSP板原理图(pdf);如果有需要,可发mentor版本的原
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


