
flume-ng+Kafka+Storm+HDFS 实时系统
针对项目需求的对应用服务器集群与 MySQL 集群产生的日志进行实时汇集的需求,可
以采用目前比较流行的解决方案:ume-ng+Kaa+Storm+HDFS。
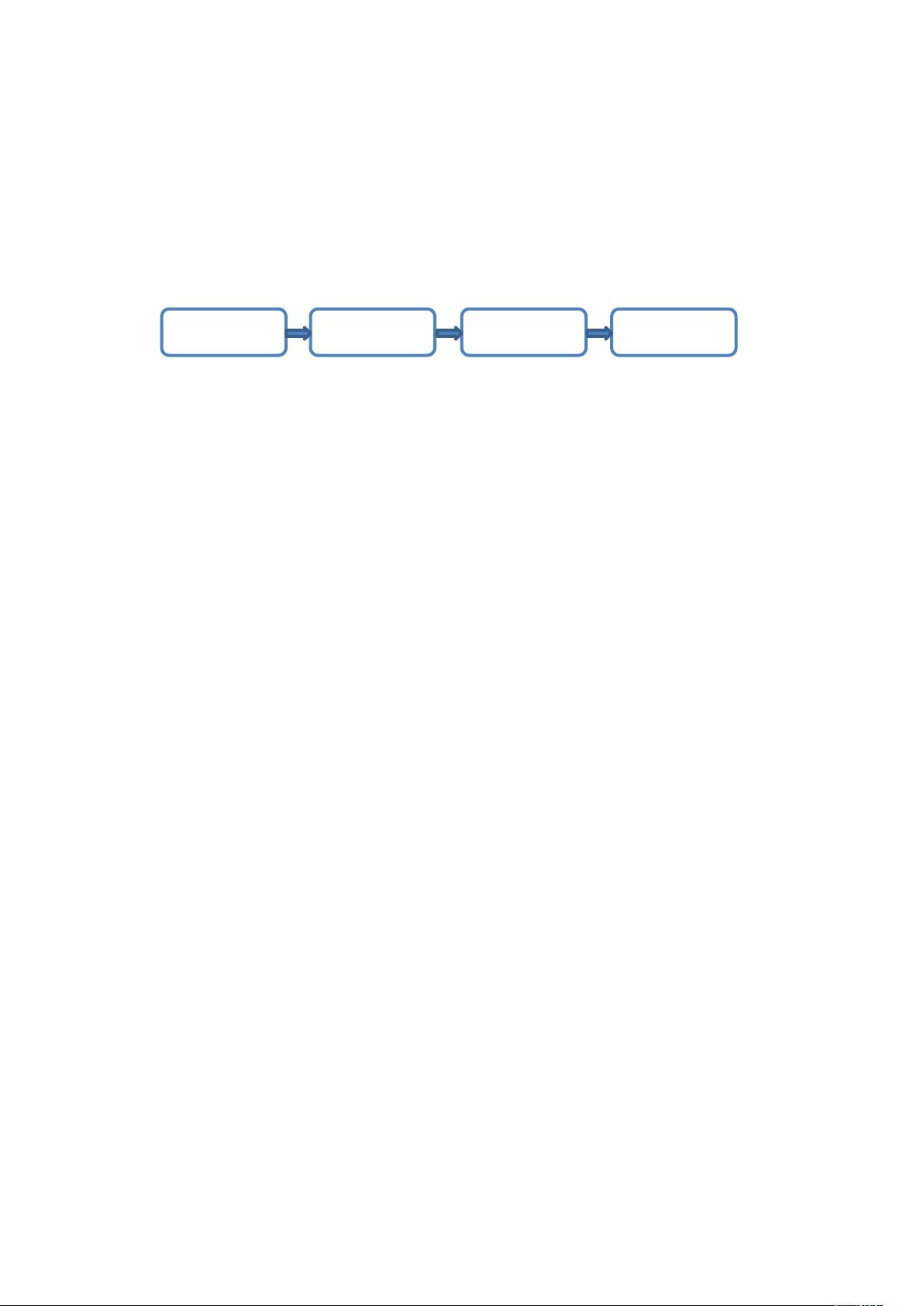
系统主要分为 4 部分:
1).数据采集
负责从各节点上实时采集数据,选用 cloudera 的 ume 来实现。(需求里提到的用这个)
2).数据接入
由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲
可选用 apache 的 kaa(这个类似 mq,灰哥很熟悉。)
3).流式计算
对采集到的数据进行实时分析,选用 apache 的 storm
4).数据输出
对分析后的结果持久化,可以使用 mysql(或者看客户想用啥)
模块化之后,假如当 Storm 挂掉了之后,数据采集和数据接入还是继续在跑着,数据不会
丢失,storm 起来之后可以继续进行流式计算。
数据采集 数据接入 数据输出流式计算
资源评论













