
一、关于 Yarn 的学习
1、YARN 的应用
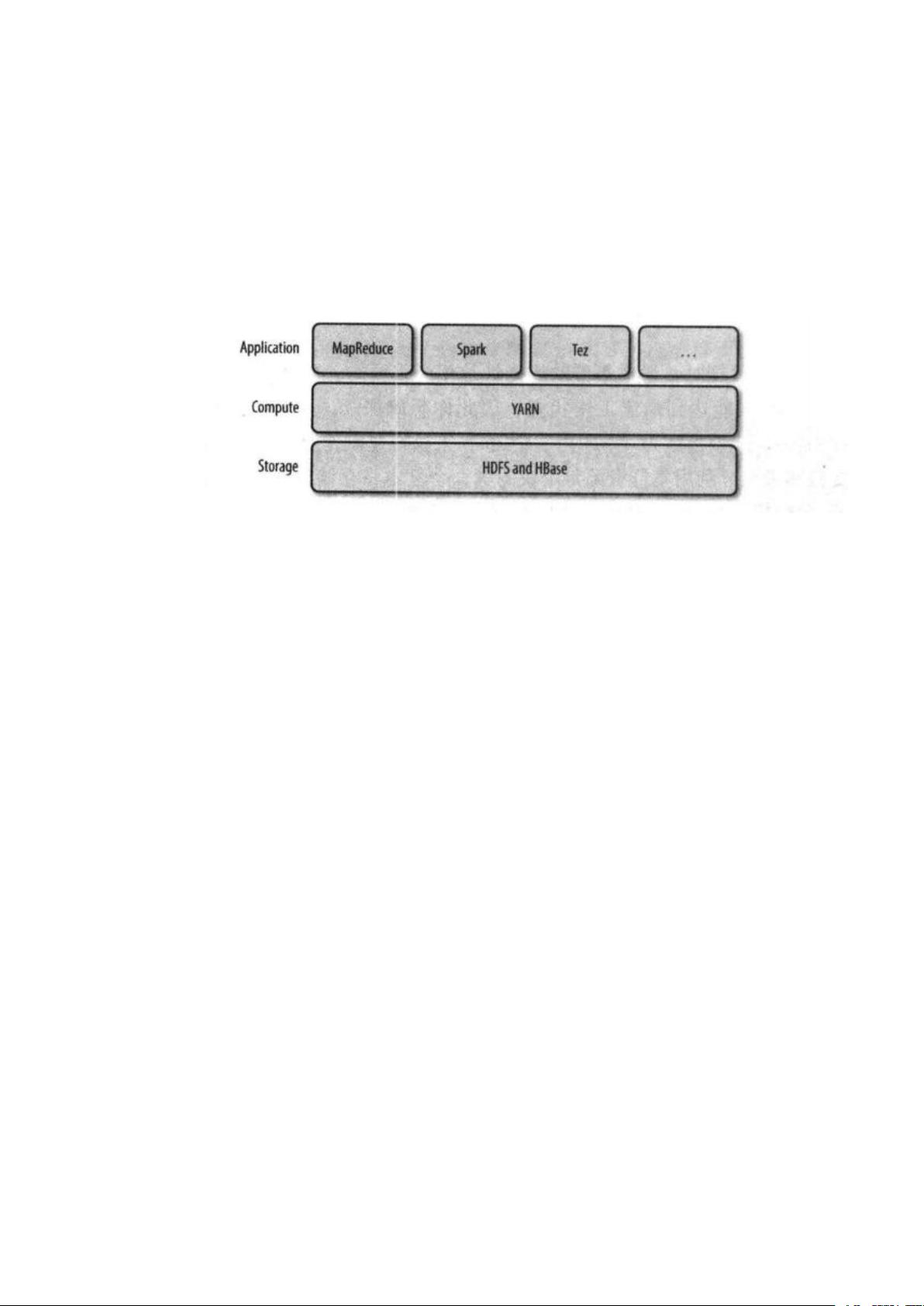
一些分布式计算框架(MapReduce,Spark 等等)作为 YARN 应用运行在集群
计算层(YARN)和集群存储层(HDFS 和 HBase)上。
还有一层应用是建立在上图所示的框架之上。如 PIg,Hive 和 Crunch 都是运行
在 MR、Spark 之上的处理框架。
2
、
YARN
的运行机制
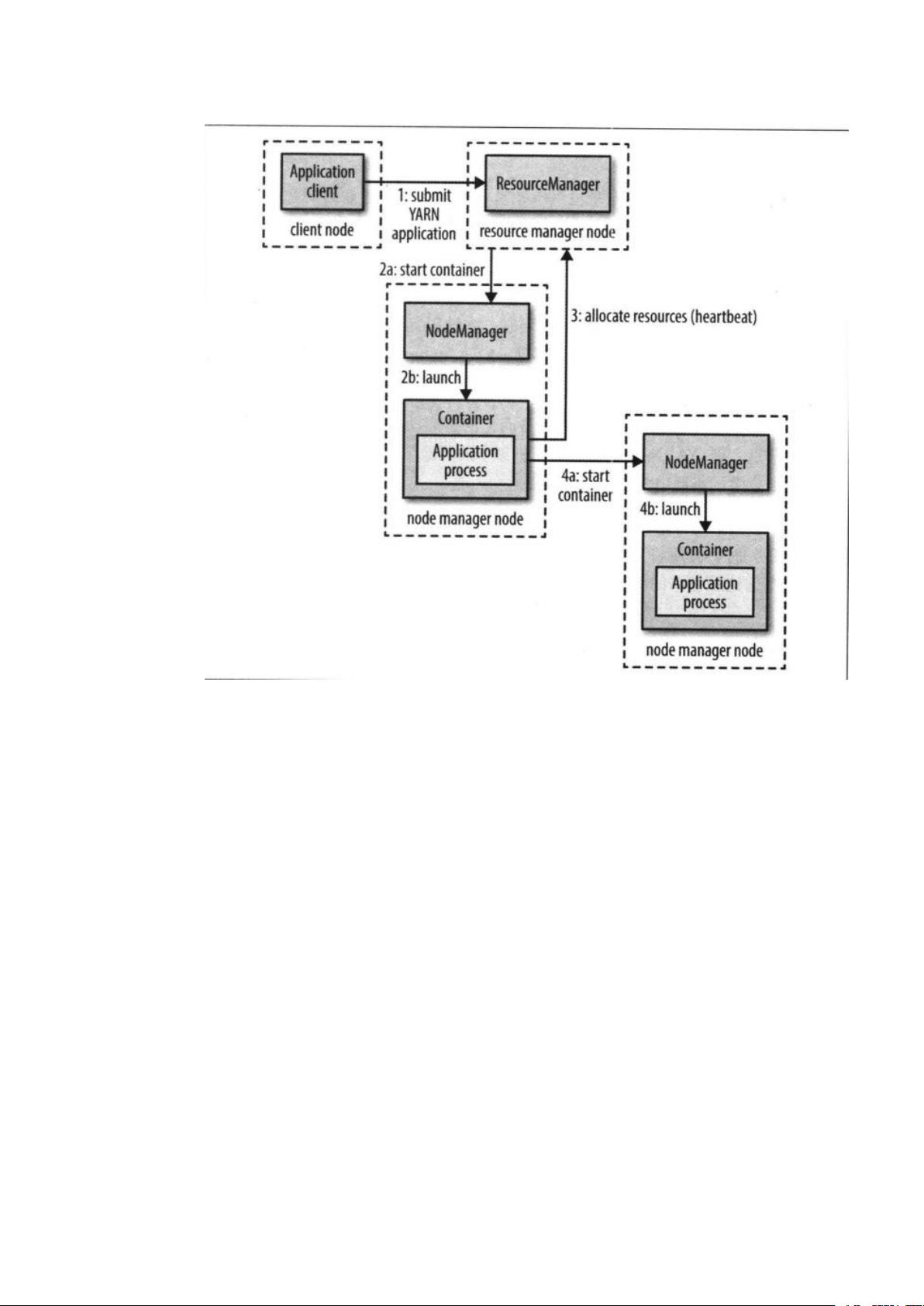
YARN
通过两类长期运行的守护进程提供自己的核心服务:管理集群行资源使用
的资源管理器(
resource manager
)、运行在集群中所有节点上且能够启动和监听容
器(
container
)的节点管理器(
node manager
)。容器用于执行特定应用程序的进
程、每个容器都有资源限制(内存、
CPU
等)。一个容器可以是一个
Unix
进程,也
可以是一个
Linux cgroup
,取决于
YARN
的配置。


剩余25页未读,继续阅读
资源评论


AA强
- 粉丝: 21
- 资源: 21









最新资源
- 【java毕业设计】springboot医学电子技术线上课堂系统(springboot+vue+mysql+说明文档).zip
- java 输入任意字符串找回文
- NewModel_3.2.2(1).zip
- 上海交通大学版 asp.NET第152页-运用ADO.NET访问数据库(注册账号并在网站中查询)
- 【源码+数据库】利用Java Swing框架与Socket技术开发的即时通讯系统,系统分为客户端和服务端,类似于qq聊天
- 计算机科学与技术数据结构实践考核要求.ppt
- 【java毕业设计】springboot中医院问诊系统的设计与实现(springboot+vue+mysql+说明文档).zip
- MATLAB大数计算工具箱及其用法
- 基于 python 实现的微博的数据挖掘与社交舆情分析
- Screenshot_20241105_140450.jpg
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


