

Subword Embedding from Bytes Gains
Privacy without Sacrificing Accuracy and Complexity
Mengjiao Zhang
Department of Computer Science
Stevens Institute of Technology
mzhang49@stevens.edu
Jia Xu
Department of Computer Science
Stevens Institute of Technology
jxu70@stevens.edu
Abstract
While NLP models significantly impact our lives, there are rising concerns about
privacy invasion. Although federated learning enhances privacy, attackers may
recover private training data by exploiting model parameters and gradients. There-
fore, protecting against such embedding attacks remains an open challenge. To
address this, we propose Subword Embedding from Bytes (SEB) and encode sub-
words to byte sequences using deep neural networks, making input text recovery
harder. Importantly, our method requires a smaller memory with
256
bytes of
vocabulary while keeping efficiency with the same input length. Thus, our solution
outperforms conventional approaches by preserving privacy without sacrificing
efficiency or accuracy. Our experiments show
SEB
can effectively protect against
embedding-based attacks from recovering original sentences in federated learning.
Meanwhile, we verify that
SEB
obtains comparable and even better results over
standard subword embedding methods in machine translation, sentiment analysis,
and language modeling with even lower time and space complexity.
1 Introduction
Advances in Natural Language Processing (NLP), such as Large Language Models (LLMs), have
made noticeable advancements in performance over the last decades, partially attributed to the large
datasets available. Since most data are from users, their privacy concerns play an increasingly critical
role, which is essential to building user trust, encouraging the responsible use of language data,
protecting personal information, ensuring ethical use, and avoiding potential harm to individuals.
Federated learning (FL) enables training shared models across multiple clients without transferring
the data to a central server to preserve user privacy. Although only the model updates are sent to
the central server, adversaries can still use model updates to reconstruct the original data and leak
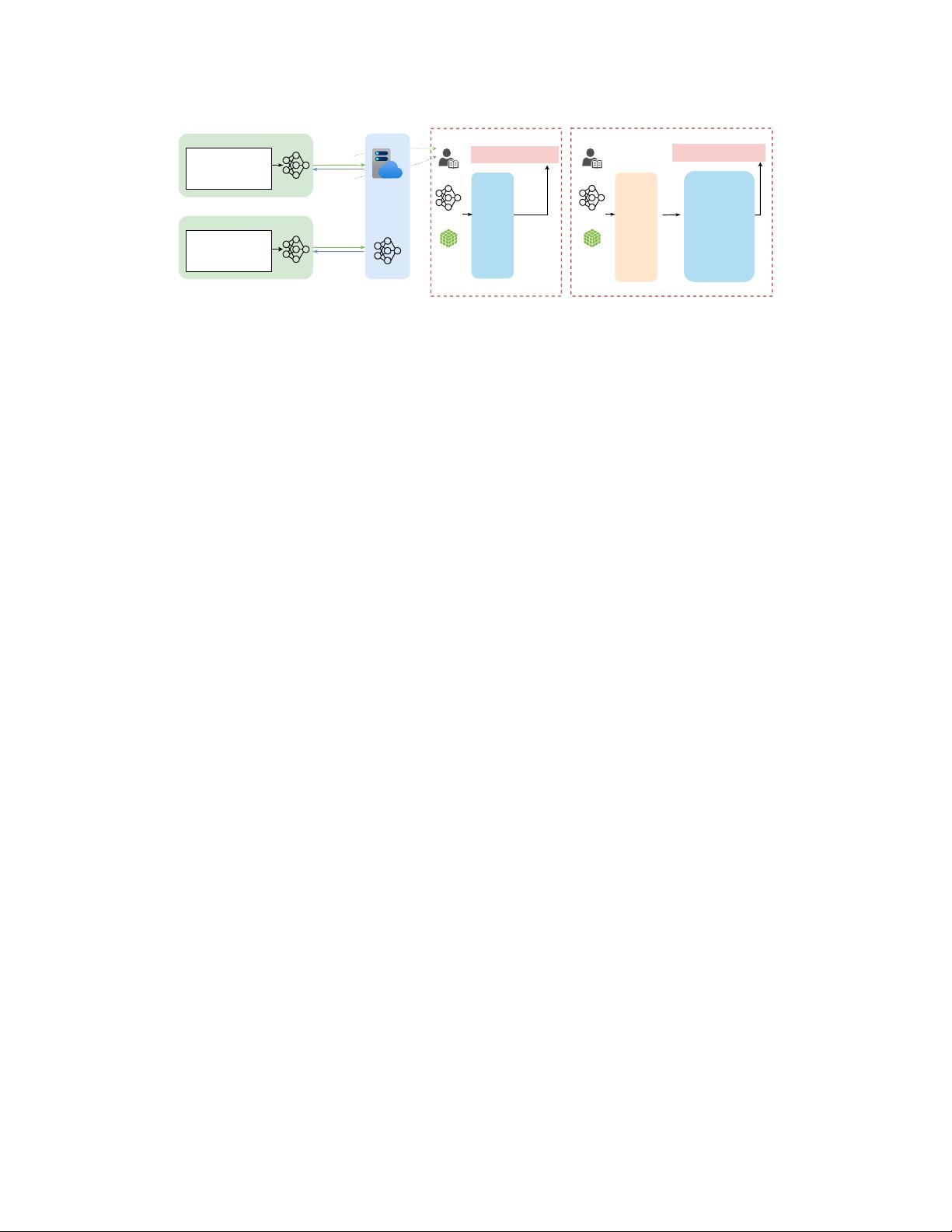
sensitive information to compromise the user’s privacy. Figure 1(a) demonstrates an FL framework,
and Figure 1(b) shows how embedding-based attacks work as in [
7
]. In the illustrated example,
the attacker extracts all candidate words in a batch of data from the embedding gradients and can
easily reconstruct the text with beam search and reordering since one can perform straightforward
lookups when a vector is updated due to the one-to-one mapping between word/subword tokens and
embedding vectors.
Our intuitive idea is to apply the byte embedding method because the same bytes are repeatedly
used for multiple subwords. We aim to design a one-to-many mapping between words/subwords and
embedding vectors to increase the difficulty of the simple lookup so that retrieving input subwords
with the updated byte embeddings is harder, which makes the byte embedding in NLP models a
potential defense. For example, in subword embedding, if the word “good” is updated, the attacker
will only retrieve this word based on embedding updates. However, if we tokenize “good” into four
bytes, such as “50, 10, 128, 32", all subwords containing at least one of these bytes will be retrieved,
Preprint. Under review.
arXiv:2410.16410v1 [cs.AI] 21 Oct 2024

剩余14页未读,继续阅读
资源评论













