

作业参考答案
第二章 高级语言及其语法描述
、( )(
)
()最左推导:
最右推导:
、G:
、( )最左推导:
! ! ! !
!! ! !"# !"# !"# !"# !" #
!" # !" #
最右推导:
!! ! ! ! ! !
!!"#!"#!"#!" #!" #!" #
!" #!" # !" #
"#
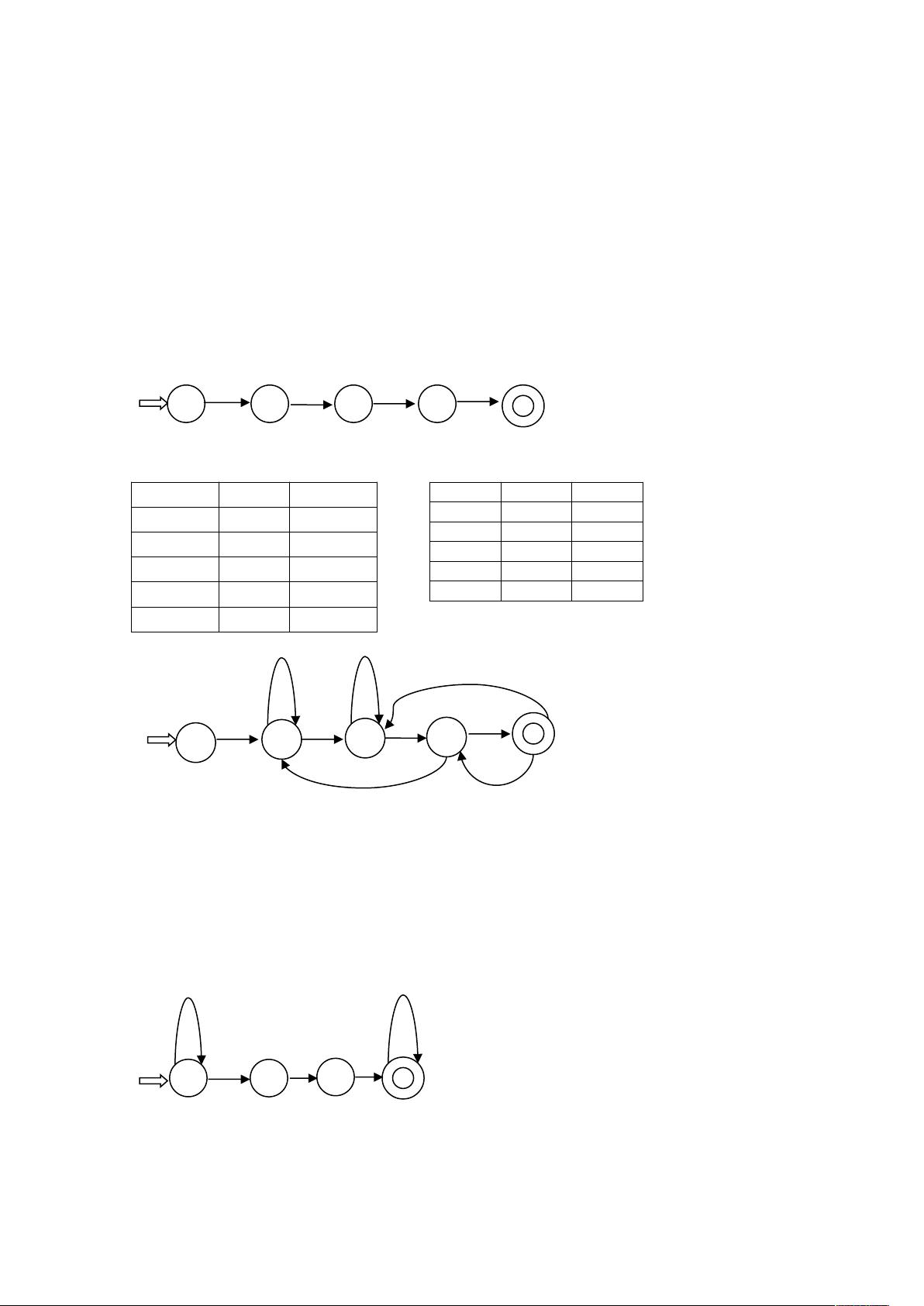
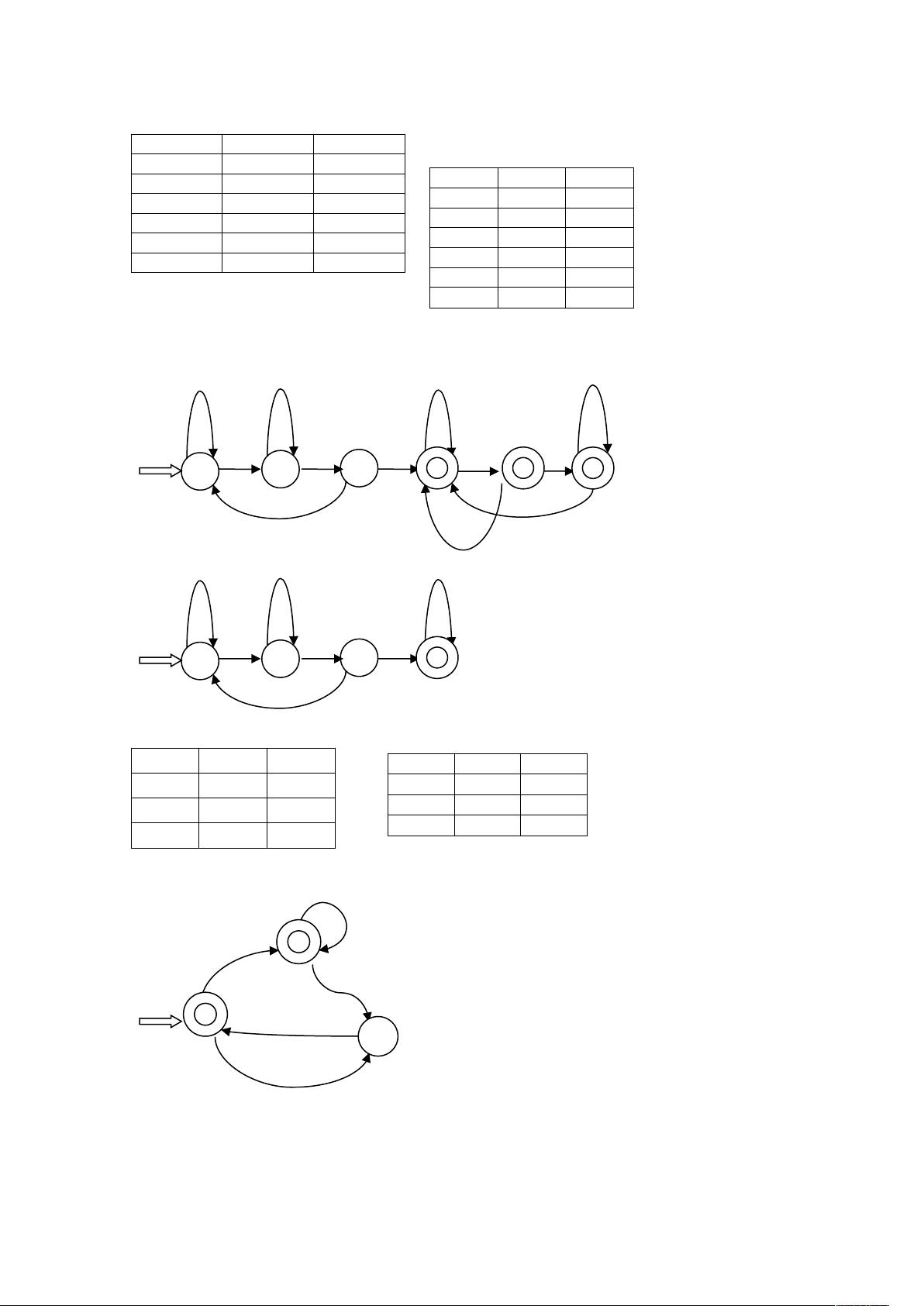
、证明:该文法存在一个句子 $ 有两棵不同语法分析树,如下所示,因此该文法是
二义的。
1
E
+ T
T
F
i
E
E + T
F
i
F
i
E
+
T
F
i
E
T
* F
i
F
i
T
E
- T
T
F
i
E
E - T
F
i
F
i
S
S
e
i
S
i
S
i
i
S
e
i
S
i
S
i
S
i
剩余15页未读,继续阅读
资源评论

 MambaSpirit_forever2020-05-17里面的题也太少了吧。。。
MambaSpirit_forever2020-05-17里面的题也太少了吧。。。 psdfeng2012-03-13有点乱码,总体还行,做作业可以参考。。
psdfeng2012-03-13有点乱码,总体还行,做作业可以参考。。

fengjliang2009
- 粉丝: 4
- 资源: 60









最新资源
- 基于matlab的FFT分析和滤波程序,可对数据信号进行频谱分析,分析波形中所含谐波分量,并可以对特定频率波形进行提取 不需要通过示波器观察,直接导入数据即可,快捷便利 程序带有详细注释, 图a为
- 基于Springboot+Vue的精简博客系统的设计与实现-毕业源码案例设计(源码+论文).zip
- 基于Springboot+Vue交通管理在线服务系统的开发-毕业源码案例设计(95分以上).zip
- uDDS源程序publisher
- 机械手自动排列控制PLC与触摸屏程序设计
- 基于Springboot+Vue的客户关系管理系统(crm)的设计与实现-毕业源码案例设计(高分毕业设计).zip
- 基于Springboot+Vue的课程作业管理系统毕业源码案例设计(高分毕业设计).zip
- 基于Springboot+Vue的酒店客房管理系统-毕业源码案例设计(源码+数据库).zip
- (链家)上海市房屋租赁价格数据.zip
- ESP8266-调试.pdf
- 基于STM32设计的工地扬尘与噪音实时监测系统(网页).pdf
- 基于Springboot+Vue的库存管理系统-毕业源码案例设计(高分毕业设计).zip
- 基于Springboot+Vue的老年人体检管理系统-毕业源码案例设计(高分毕业设计).zip
- 基于Springboot+Vue的乐享田园系统-毕业源码案例设计(95分以上).zip
- 基于Springboot+Vue的流浪宠物管理系统的设计与实现-毕业源码案例设计(95分以上).zip
- 基于Springboot+Vue的论坛系统-毕业源码案例设计(高分项目).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


