关于语言大模型的八大论断
需积分: 1 165 浏览量
2023-06-27
09:55:52
上传
评论
收藏 836KB PDF 举报


关于语言大模型的八大论断
近几个月来,语言大模型(LLM)的广泛公开部署引起了倡导
者 、 政 策 制 定 者 和 许 多 领 域 学 者 们 的 新 一 轮 关 注 和 参 与 。 本文
主要总结了 八个可能引发思考的观点,并讨论了 LLM 还存在的
局限性。
即便没有针对性的创新,LLM 的能力也会随着投资的增加
而可预估地增强
LLM 中的一些重要行为往往作为增加投资的“ 副产品” 不可
预测地出现
LLM 经常学习并使用外部世界的表征
目前还没有可靠的技术来引导 LLM 的行为
专家们还不能解释 LLM 的内部运作情况
人类在一项任务上的表现并不是 LLM 表现的上限
LLM 不需要表达其创造者的价值观,也不需要表达网络文
本中编码的价值观
与 LLM 的简短互动往往具有误导性
语言大模型及其衍生产品,如 Ch atGPT 等,最近引起了记者、政
策制定者和学者们的极大关注。然而,该技术在许多方面都没有
达到人们的预期效果,对它的简要概述往往容易忽略重点。 本
文提出了八个大胆论断,预计这些论断在 LL M 相关讨论中将引起
关 注 。它 们 代 表 着 模 型 开 发 人 员 对 LL M 的普遍看法。 本文的目
的并非针对 LLM 提出规范性意见。对于颠覆性新技术的态度应该
由核心技术研发社区之外的学者、倡导者和立法者们在充分了解
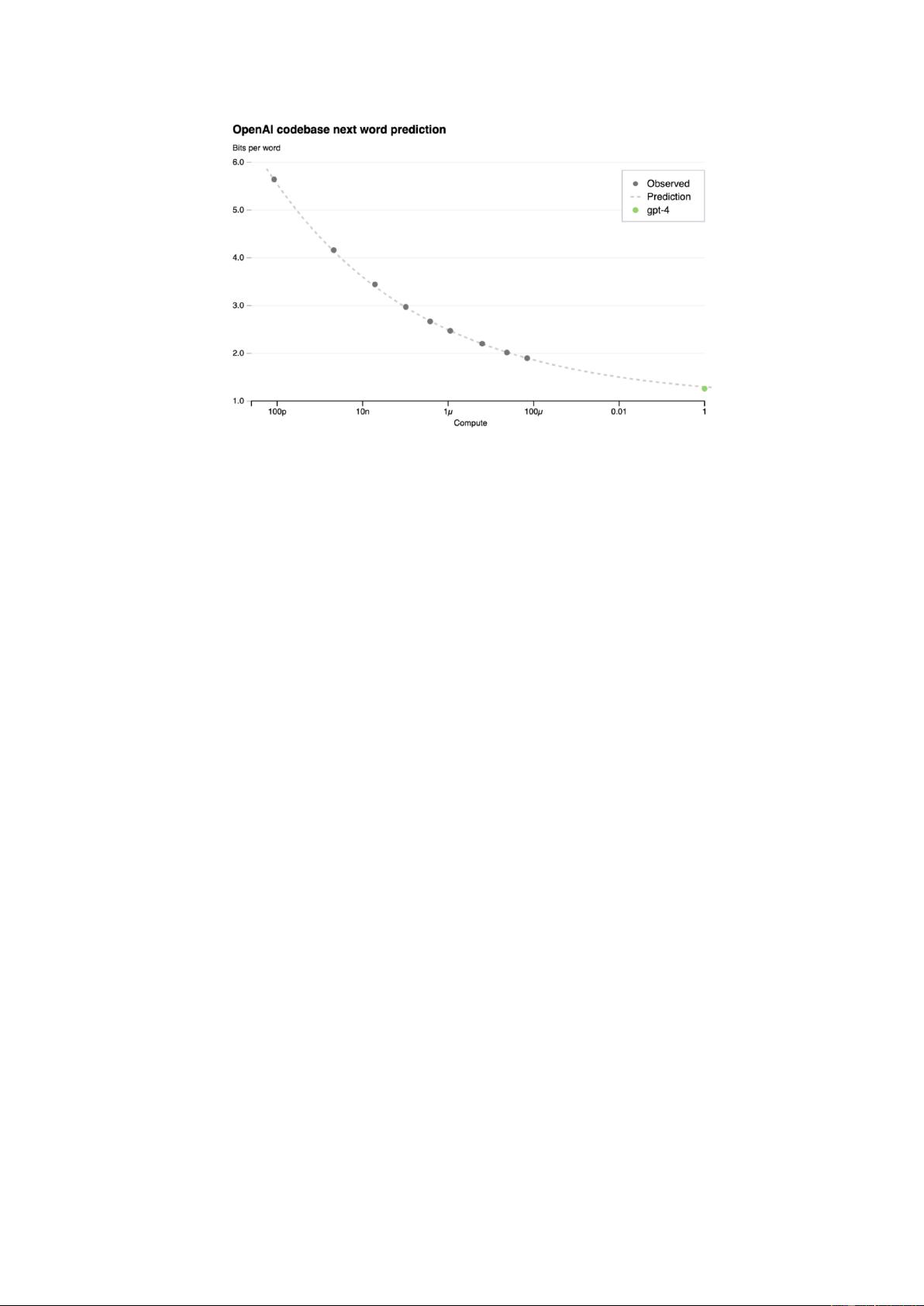
情况的基础上决定。 1 即 便 没 有 针 对 性 创 新 , LLM 的能力
也 会 随 着 投 资 的 增 加 而 可 预 估 地 增 强 规模定律(s c a l i n g
law)是近期 LLM 研究和投资激增的主要原因。有了规模定律,
当沿着模型输入的数据量、模型大小(参数量)以及训练模型的
计算量(以 F L O P 为单位))扩展 LLM 时,我们将能够预测模
型 的 未 来 能 力 。 这 样 在 面 对 关 键 设 计 决 策 时 就 可 以 直 接 作 决 策 ,
无需耗费巨资反复试验。 这种精确预测能力在软件史,甚至现
代人工智能研究史上都是不同寻常的。这也是推动投资的强大工
具 ,有 了 这 一 预 测 能 力 ,研 发 团 队 可 以 进 行 耗 资 数 百 万 美 元 的 模
型训练项目,并确保这些项目能成功产生有经济价值的系

剩余10页未读,继续阅读
资源评论













