

CS294A Lecture notes
Andrew Ng
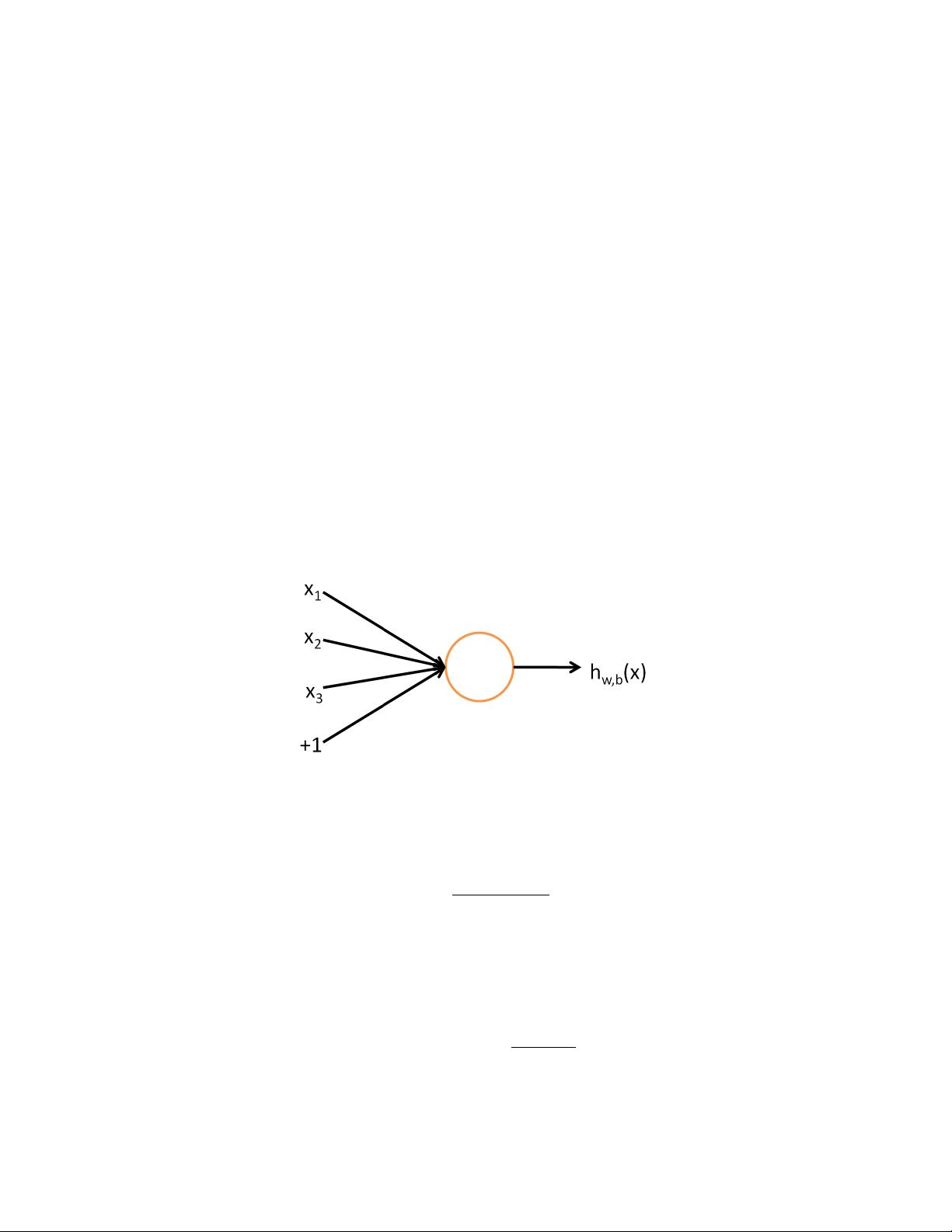
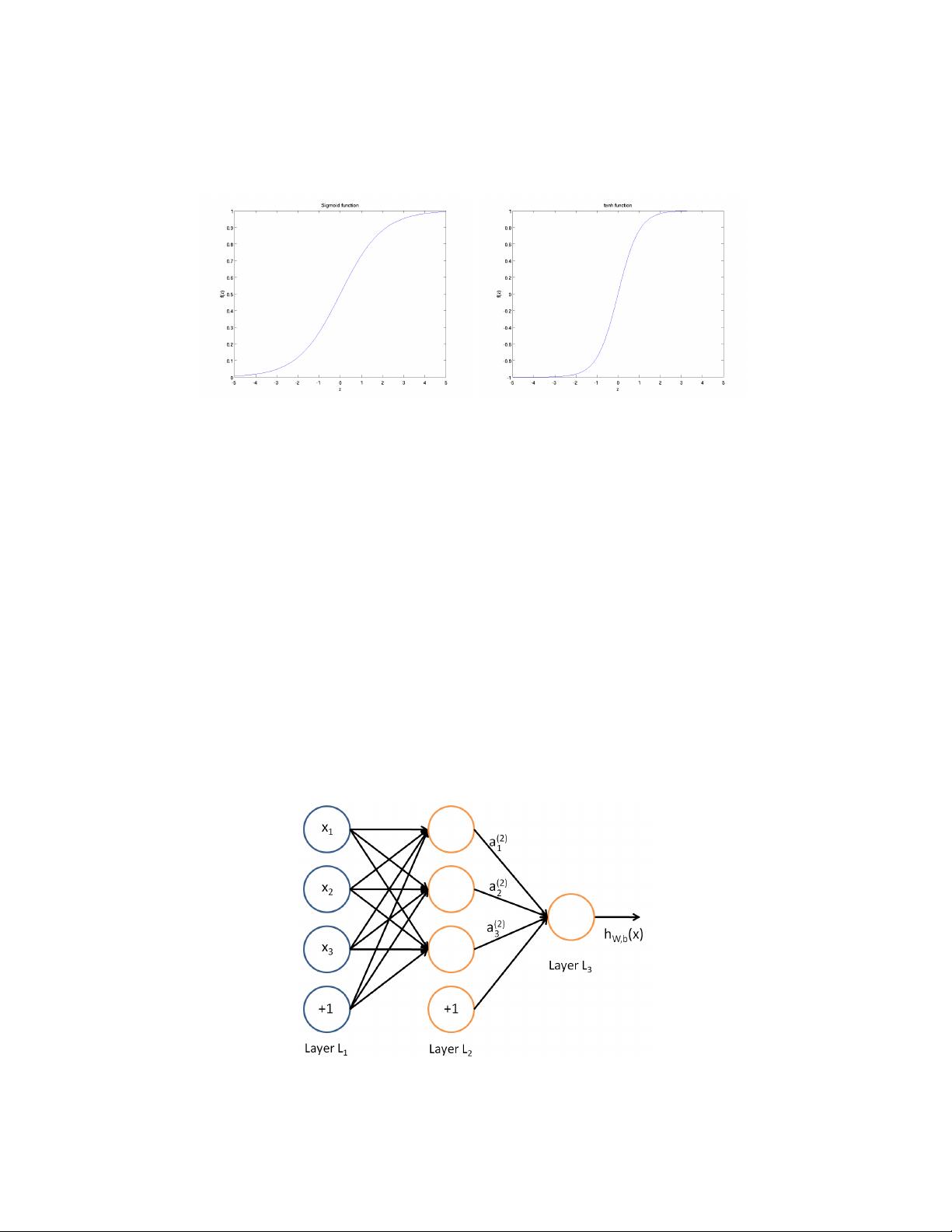
Sparse autoencoder
1 Introduction
Supervised learning is one of the most powerful tools of AI, and has led to
automatic zip code recognition, speech recognition, self-driving cars, and a
continually improving understanding of the human genome. Despite its sig-
nificant successes, supervised learning today is still severely limited. Specifi-
cally, most applications of it still require that we manually specify the input
features x given to the algorithm. Once a good feature representation is
given, a supervised learning algorithm can do well. But in such domains as
computer vision, audio processing, and natural language processing, there’re
now hundreds or perhaps thousands of researchers who’ve spent years of their
lives slowly and laboriously hand-engineering vision, audio or text features.
While much of this feature-engineering work is extremely clever, one has to
wonder if we can do better. Certainly this labor-intensive hand-engineering
approach does not scale well to new problems; further, ideally we’d like to
have algorithms that can automatically learn even better feature representa-
tions than the hand-engineered ones.
These notes describe the sparse autoencoder learning algorithm, which
is one approach to automatically learn features from unlabeled data. In some
domains, such as computer vision, this approach is not by itself competitive
with the best hand-engineered features, but the features it can learn do turn
out to be useful for a range of problems (including ones in audio, text, etc).
Further, there’re more sophisticated versions of the sparse autoencoder (not
described in these notes, but that you’ll hear more about later in the class)
that do surprisingly well, and in many cases are competitive with or superior
to even the best hand-engineered representations.
1
剩余18页未读,继续阅读
资源评论

 wml7601254532017-12-05还不错,学习了,谢谢。。。
wml7601254532017-12-05还不错,学习了,谢谢。。。
echea
- 粉丝: 0
- 资源: 1









最新资源
- 基于PLC的全自动洗衣机控制系统设计:硬件与软件的完美结合方案,基于PLC的全自动洗衣机控制系统设计详解含硬件和软件设计章节一套完整方案,基于PLC全自动洗衣机控制系统设计 含Word文档一整套 前
- 基于COMSOL的结晶凝固过程仿真:考虑温度场、浓度场、相变及物质偏析的全方位分析,COMSOL仿真模拟结晶过程:涵盖温度场、浓度场、相变及物质偏析等多元因素研究,comsol 仿真结晶,凝固,考虑温
- stm32 OLED显示模块 寄存器方式代码
- 基于Matlab的迁移学习技术用于滚动轴承故障诊断,振动信号转图像处理并高精度分类,基于Matlab的迁移学习滚动轴承故障诊断系统:高准确率,简易操作,Matlab 基于迁移学习的滚动轴承故障诊断 1
- 双缸水平蒸汽机3D 双缸水平蒸汽机
- 基于XAFS数据处理的拟合算法及小波变换应用研究,基于XAFS数据处理的拟合算法及小波变换应用研究,xafs数据处理,拟合,小波变 ,xafs数据处理; 拟合; 小波变换,Xafs数据处理与拟合的小波
- 无线通信Mimo系统中STBC空时编码与MRC最大比合并的性能比较研究(基于Matlab 2016b版本),无线通信MIMO系统中的STBC空时编码与MRC最大比合并技术性能研究,基于Matlab 2
- 基于Python的Django-vue基于Spark的国漫推荐系统实现源码-说明文档-演示视频.zip
- C#实现多协议数据传输:OPC与DCS无DCOM配置读取及高效数据转发方案,C#实现无需DCOM配置的OPC与DCS数据传输:通过Socket转发至其他电脑或MODBUS/UDP协议实现高效数据读取与
- C语言基础入门学习笔记大纲.pdf
- 回溯组合问题_202503061306_54460.hinote
- 火狐判断安装_64位版本 (1).exe
- 基于python+PYQT开发的电子发票管理软件(源码+说明)
- 基于STM32F103C8T6与ATT7022芯片的三相交流电测量RTU-功能丰富、数据准确、稳定可靠的电能监控系统,基于STM32与ATT7022芯片的三相交流电测量RTU系统:集成电压、电流及多
- 回溯组合问题_202503061309_56587.pdf
- 基于python和豆包开发的根据提示词生成脚本 通过视频脚本调用微软tts生成语音功能的软件(源码)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


