
NAST: A Non-Autoregressive Generator with Word Alignment
for Unsupervised Text Style Transfer
Fei Huang, Zikai Chen, Chen Henry Wu, Qihan Guo, Xiaoyan Zhu, Minlie Huang
∗
The CoAI group, DCST; Institute for Artificial Intelligence;
State Key Lab of Intelligent Technology and Systems;
Beijing National Research Center for Information Science and Technology;
Tsinghua University, Beijing 100084, China.
f-huang18@mails.tsinghua.edu.cn natnstart@gmail.com henrychenwu98@gmail.com
gqh18@mails.tsinghua.edu.cn zxy-dcs@tsinghua.edu.cn aihuang@tsinghua.edu.cn
Abstract
Autoregressive models have been widely used
in unsupervised text style transfer. Despite
their success, these models still suffer from
the content preservation problem that they usu-
ally ignore part of the source sentence and
generate some irrelevant words with strong
styles. In this paper, we propose a Non-
Autoregressive generator for unsupervised text
Style Transfer (NAST), which alleviates the
problem from two aspects. First, we observe
that most words in the transferred sentence can
be aligned with related words in the source sen-
tence, so we explicitly model word alignments
to suppress irrelevant words. Second, existing
models trained with the cycle loss align sen-
tences in two stylistic text spaces, which lacks
fine-grained control at the word level. The pro-
posed non-autoregressive generator focuses on
the connections between aligned words, which
learns the word-level transfer between styles.
For experiments, we integrate the proposed
generator into two base models and evaluate
them on two style transfer tasks. The re-
sults show that NAST can significantly im-
prove the overall performance and provide ex-
plainable word alignments. Moreover, the non-
autoregressive generator achieves over 10x
speedups at inference. Our codes are available
at https://github.com/thu-coai/NAST.
1 Introduction
Text style transfer aims at changing the text
style while preserving the style-irrelevant contents,
which has a wide range of applications, e.g., senti-
ment transfer (Shen et al., 2017), text formalization
(Rao and Tetreault, 2018), and author imitation
(Jhamtani et al., 2017). Due to the lack of parallel
training data, most works focus on unsupervised
text style transfer using non-parallel stylistic data.
The cycle consistency loss (Zhu et al., 2017),
a.k.a. the back-translation loss (Lample et al., 2018,
*
Corresponding author: Minlie Huang.
Not great, but good atmosphere and great service
Not terrible, but not very good
Source:
Transferred:
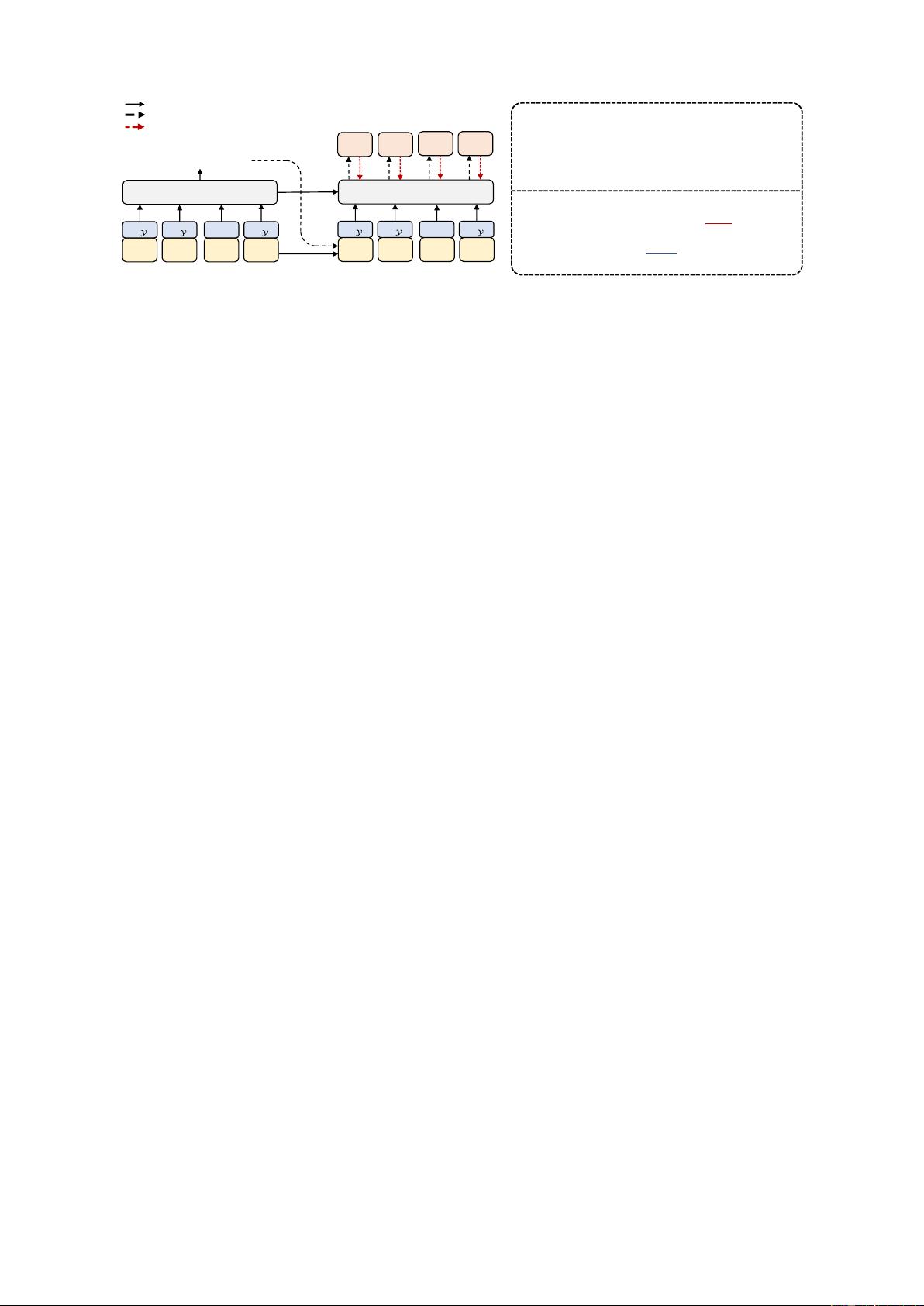
Autoregressive Generation
(a) Existing Style Transfer Model
Not perfect , but
indeed
very good
Not terrible , but not very good
Source:
Target:
(b) Observation of Word Alignment
Not perfect , but very good indeed
Not terrible , but
not very good
veryNot terrible , but good [Mask]
Source:
Transferred:
Step 1. Alignment Prediction
Aligned:
(c) NAST (Ours)
Two Step Decomposition
Step 2. Non-autoregressive Generation
61 2 3 4 7 0
5
1 2 3 4 6
7
Figure 1: Sentiment transfer examples (negative to pos-
itive). (a) Existing models without word alignments
may generate words irrelevant to the source sen-
tence. (b) An example of word alignments between the
source and target sentences. Arrows connect aligned
words (identical or relevant), and blue words are not
aligned. (c) NAST’s generation process. Step 1: gener-
ate the index of aligned words. [Mask] is a placeholder
for unaligned words. Step 2: generate the transferred
sentence non-autoregressively.
2019), has been widely adopted by unsupervised
text style transfer models (Dai et al., 2019; He et al.,
2020; Yi et al., 2020). Specifically, the cycle loss
minimizes the reconstruction error for the sentence
transferred from style
X
to style
Y
and then back to
X
, which aligns the sentences in two stylistic text
spaces to achieve the transfer and preserve style-
irrelevant contents. The cycle-loss-based models
are trained in an end-to-end fashion, and thus can
be easily applied to different datasets.
Although cycle-loss-based models yield promis-
ing results, one of their major failure cases is to
replace some part of the source sentence with irrel-
evant words that have strong styles, as shown in Fig
1(a). This problem degrades content preservation
and can be alleviated from two perspectives.
First
,
we observe that most words in the human-written
arXiv:2106.02210v1 [cs.CL] 4 Jun 2021

剩余13页未读,继续阅读
资源评论



易小侠
- 粉丝: 6634
- 资源: 9万+









最新资源
- 【通用】-08-组织架构图.docx
- 【通用】-11-组织架构图.docx
- 【通用】-12-组织架构图.docx
- 【通用】-10-组织架构图.docx
- 【物业公司】-02-组织架构图.docx
- 【物流行业】-06-组织架构图.docx
- 【物业公司】-05-组织架构图.docx
- 【物业公司】-03-组织架构图.docx
- 【物业公司】-04-组织架构图.docx
- 【物业公司】-06-组织架构图.docx
- 【销售公司】-02-组织架构图.docx
- 【销售公司】-03-组织架构图.docx
- 【影视行业】-01-组织架构图.docx
- 【印染公司】-01-组织架构图.docx
- 01-集团公司组织架构图.docx
- 【资产管理】-01-组织架构图.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


