

Design Trade-os for a Robust Dynamic Hybrid Hash Join
(Extended Version)
Shiva Jahangiri
University of California, Irvine
shivaj@uci.edu
Michael J. Carey
University of California, Irvine
mjcarey@ics.uci.edu
Johann-Christoph Freytag
Humboldt-Universität zu Berlin
freytag@informatik.hu-berlin.de
ABSTRACT
The Join operator, as one of the most expensive and commonly used
operators in database systems, plays a substantial role in Database
Management System (DBMS) performance. Among the many dif-
ferent Join algorithms studied over the last decades, Hybrid Hash
Join (HHJ) has proven to be one of the most ecient and widely-
used join algorithms. While HHJ’s performance depends largely
on accurate statistics and information about the input relations, it
may not always be practical or possible for a system to have such
information available.
HHJ’s design depends on many details to perform well. This
paper is an experimental and analytical study of the trade-os in
designing a robust and dynamic HHJ operator. We revisit the design
and optimization techniques suggested by previous studies through
extensive experiments, comparing them with other algorithms de-
signed by us or used in related studies.
We explore the impact of the number of partitions on HHJ’s
performance and propose a lower bound and a default value for
the number of partitions. We continue by designing and evaluat-
ing dierent partition insertion techniques to maximize memory
utilization with the least CPU cost. In addition, we consider a com-
prehensive set of algorithms for dynamically selecting a partition
to spill and compare the results against previously published stud-
ies. We then present two alternative growth policies for spilled
partitions and study their eectiveness using experimental and
model-based analyses.
These algorithms have been implemented in the context of
Apache AsterixDB and evaluated under dierent scenarios such as
variable record sizes, dierent distributions of join attributes, and
dierent storage types, including HDD, SSD, and Amazon Elastic
Block Store (Amazon EBS) [2].
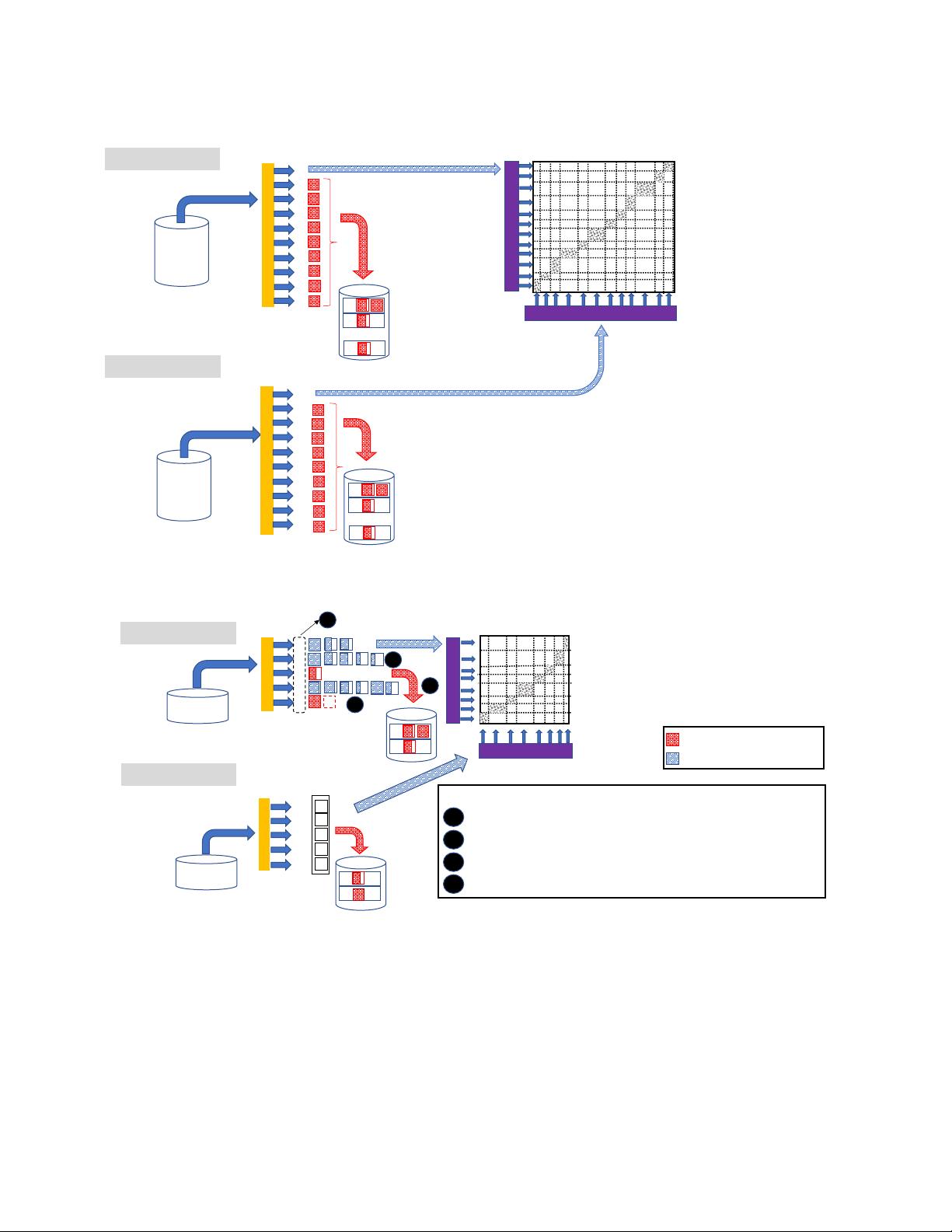
1 INTRODUCTION
As one of the most popular and expensive DBMS operators, the join
operator can signicantly impact the performance of a DBMS. HHJ
[
50
] has shown superior performance in computing the equijoin of
two datasets among other kinds of join operators. In a nutshell, HHJ
groups the records of each dataset into disjoint partitions. A hash
table is created to hold one of the partitions in memory (memory-
resident partition), while the rest will be written (spilled) to disk
to be processed in the next rounds of HHJ. The number of the
partitions and the selection of the memory-resident partition are
static decisions made at the compile time of an HHJ operator. While
previous studies [
30
,
50
] have suggested various cost models and
optimization techniques for enhancing such decisions, these studies
have two shortcomings: (1) They assume a uniform distribution for
join attribute values. (2) Their cost models rely on having accurate
statistical information such as input sizes prior to query execution.
Unfortunately, collecting and accessing or predicting such infor-
mation may not always be feasible. For example:
•
Many data management systems process external data that
resides outside their storage for which they have little or
no information. (Examples include: Apache AsterixDB [
3
],
Apache Spark [4], and Oracle [7].)
•
The accurate sizes of join inputs may not be known if they
result from other operators instead of being base relations.
•
Newly developed DBMSs may not have statistics available
until they become more mature in other dimensions.
Not having sucient statistics can be detrimental to the perfor-
mance of operators whose designs depend on such information.
[
45
] has proposed Dynamic HHJ to address the unbalanced join at-
tribute values distribution by dynamically destaging the partitions
at the runtime of a join query.
Investigating the Dynamic HHJ algorithm reveals several design
questions that must be explored carefully, as they may impact the
system’s overall performance:
•
Number of partitions: How many partitions should the records
be hashed into if the sizes of inputs are unknown or inaccu-
rate?
•
Partition Insertion: How can we nd a "good" page (memory
frame) within a partition for inserting a new record?
•
Victim Selection Policy: How can we select a "good" partition
to spill in the case of insucient memory?
•
Growth Policy: How many memory frames should a spilled
partition be allowed to occupy?
With this motivation, this paper is an experimental survey of the
trade-os in designing a robust Dynamic HHJ algorithm. We an-
swer the questions above through a comprehensive evaluation of
dierent design aspects of the Dynamic HHJ algorithm and eval-
uate the alternative options through extensive experimental and
model-based analyses.
The rst contribution of this paper is to propose a lower bound
and a default value for the number of partitions for Dynamic HHJ.
We show that our proposed lower bound, while simple, can reduce
the total amount of I/O by a factor of three in some investigated
scenarios. Second, we study dierent partition insertion algorithms
to eciently nd a frame with enough space in the target parti-
tion. We evaluate the eectiveness of these algorithms on partition
compactness (fullness) and total I/O reduction. Additionally, we
propose and evaluate two policies for allocating memory frames
to spilled partitions. Finally, we propose and implement various
dynamic destaging (victim selection) strategies and evaluate them
under dierent scenarios such as dierent record size distributions,
join attribute value distributions, and combinations thereof. The
suggested optimization techniques and algorithm variants have
arXiv:2112.02480v1 [cs.DB] 5 Dec 2021


剩余16页未读,继续阅读
资源评论














