
基于 Canoco 的 CCA 数据处理过程解析
一、 数据处理
1、数据格式要求
在 Excel 表格里面,你必须将数据做成矩形形式。默认的方式(也是常用的方式)
是一行代表一个样方,一列代表一个变量。表格左顶格最好是空着。最好第一列和第
一行分别有样方编号和变量的名称。必须注意的是名称不能超过 8 个字符,如果超过 8
个字符,CANOCO 会自动截取前 8 个字符作为名称。变量名称最好是英文字母、数字 、
圆点或是连字符,空格也可以。
除了第一行和第一列,表格内剩下的填充内容必须是数字或是空着,绝对不能使
用字符型数据。定性变量(因子)必须转换为哑变量( 0‐1 数据)方可进入 CANOCO
分析。
当数据在 Excel 表格里按要求整理好后,将包含数据的矩形方阵选定,然后选择
“复制”按钮,此时数据便复制到剪贴板中。WCanoImp 便可以从剪贴板中读取数据。如
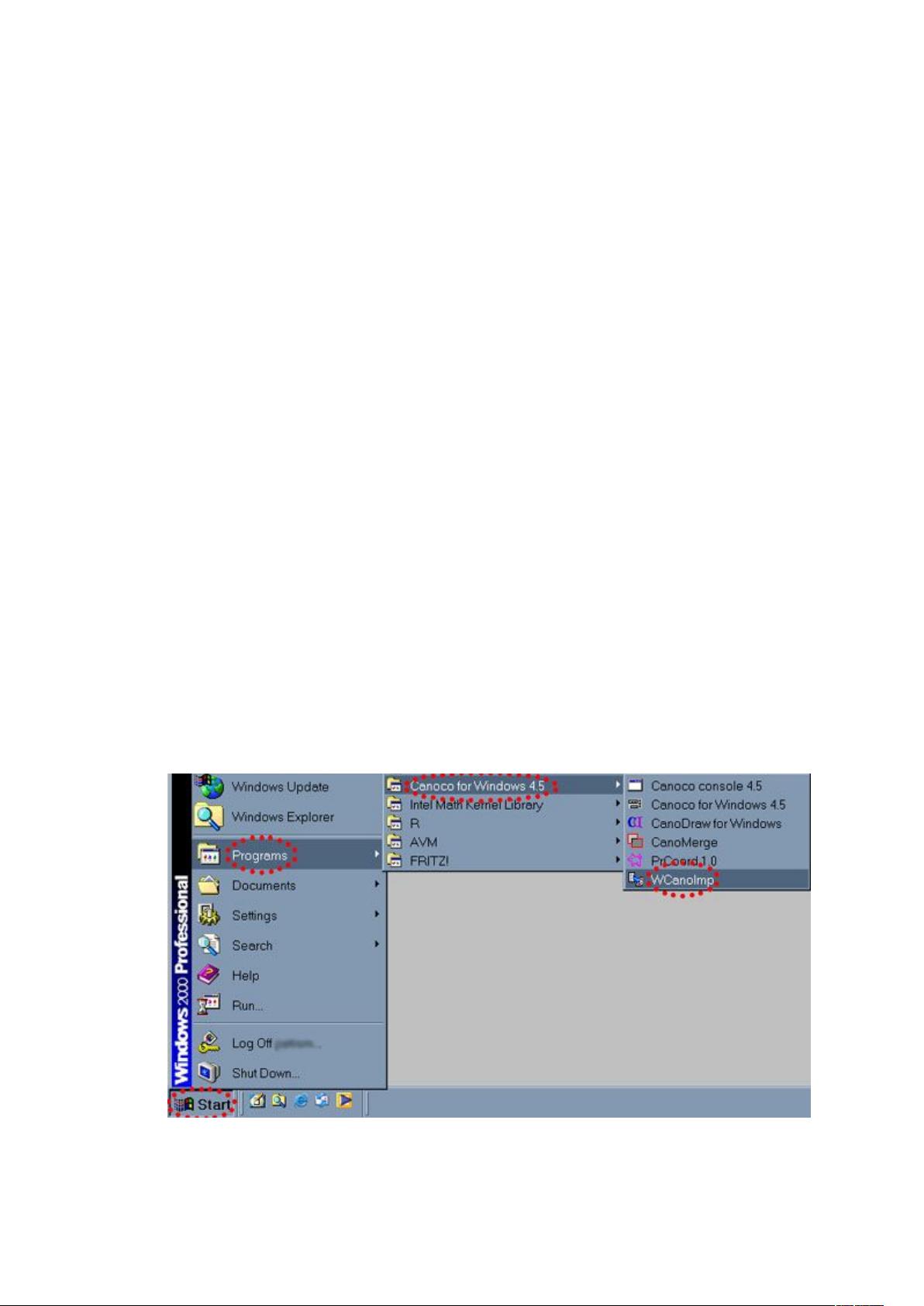
图 1‐2a 所示,WCanoImp 可以从“开始”菜单中 Canoco for windows 下来菜单中打开。此
时会弹出 WCanoImp 对话框,上半部分包含如何使用该程序的简短信息,下半部分是
一些可选框。如果在 Excel 表格数据是按照默认方式组织你的数据,第一选项不必选,
相反,如果是数据结构正好相反,以列代表样方,以行代表变量,必须选中这个“Each
column is a Sample”选项。除非你的数据是样方很少而变量很多(Excel 表格里面列数不
能超过 256 列),否则不推荐用这种方式组织数据。如果你没有样方或是变量没有编号
或 是 名 称 , 可 以 选 择 下 面 两 个 选 框 , 程 序 会 帮 你 给 各 行 各 列 附 上 默 认 名 称
(Sample1,)。最后一个选项是问你是否存为压缩型数据类型,除非你觉得硬盘空间不
够大,否则不必选这个选项,是否选这个选项中对于分析结果毫不影响。
当你确定所以的选择是正确的,你就可以按下 save 按钮,系统弹出新的对话框让
你选择保存新文件地方和取个文件名,之后会让你给这个文件加个标注,这个标注内
容将显示在新文件的数据内容第一行,以便日后数据内容的识别。选定确认后,程序
会告诉你保存成功。
图 1‐2a WCanoimp 程序打开途径
资源评论

 gaoshuagain2013-09-09这个不怎么好,对我没啥用处
gaoshuagain2013-09-09这个不怎么好,对我没啥用处

doukezhhiwu
- 粉丝: 0
- 资源: 2









最新资源
- springboot项目志同道合交友网站.zip
- springboot项目在线考试系统.zip
- springboot项目在线互动学习网站设计.zip
- springboot项目制造装备物联及生产管理ERP系统.zip
- springboot项目智慧校园之家长子系统.zip
- springboot项目中国陕西民俗网.zip
- RISCV GD32VF103 中断向量模式以及非向量模式
- 基于Rust语言的快速异步与多路复用Redis驱动设计源码
- 基于Vue的教程:学生课业帮扶系统前端设计源码
- 基于JavaScript的在线中国象棋对战平台设计源码
- 基于Lua语言的ESP32嵌入式系统开源设计源码
- 基于Vue的云盘前端设计源码
- 自动驾驶控制-车辆三自由度动力学MPC跟踪双移线 matlab和simulink联合仿真,基于车辆三自由度动力学模型的mpc跟踪双移线
- 分布式驱动汽车稳定性控制 采用分层式直接横摆力矩控制,上层滑模控制,下层基于轮胎滑移率最优分配 滑模控制跟踪横摆角速度和质心侧偏角误差 七自由度整车模型输出实际质心侧偏角和横摆角速度,二自由度模
- 基于Vue.js框架的旅游舆情分析项目设计源码
- 基于TypeScript的轻量级JavaScript点阵库设计源码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


